

1. 서 론
2. 머신러닝 기법 개요
2.1 Random Forest (RF)
2.2 eXtreme Gradient Boosting (XGBoost)
2.3 K-Nearest Neighbor (KNN)
2.4 Deep Neural Network (DNN)
2.5 Tabular Prior-Data Fitted Network (TabPFN)
3. 데이터 수집 및 분석
3.1 현장 개요
3.2 로드헤더 굴진 데이터 수집
3.3 머신러닝 학습을 위한 데이터 상관관계 분석
4. 예측 모델 개발 및 분석
4.1 예측 모델 개발
4.2 예측 모델 학습 성능 분석 및 비교
5. 결 론
1. 서 론
전 세계적으로 도심지 과밀화 문제를 해결하기 위한 지하공간 개발이 활발히 추진되고 있다. 그러나 도심지에서의 터널 공사는 굴착 과정에서 발생하는 소음과 진동으로 인해 민원이 빈번히 발생하며, 이는 중요한 사회적 문제로 대두되고 있다. 최근 국내에서는 이러한 민원 문제를 해소하기 위해 도심지에서의 발파 공법 사용을 축소하고, 상대적으로 진동과 소음이 적은 기계식 터널 굴착 공법을 장려하는 추세이다(Jung et al., 2023).
대표적인 기계화 터널 굴착 공법으로는 TBM (tunnel boring machine) 공법과 로드헤더(roadheader) 공법이 있다. 그 중 기계식 굴착 장비인 로드헤더는 TBM과 비교할 때, 터널 단면 형상 변화에 대한 대응력과 이동성이 우수하고, 제작 기간이 짧으며 초기 투자 비용이 적다는 장점을 지닌다(Chang, 2015). 이러한 특성을 바탕으로, 로드헤더 공법은 NATM (New Austrian Tunneling Method)의 시공성 한계와 TBM 공법의 제약을 보완할 수 있는 대안적 굴착 공법으로 주목받고 있다(Kim et al., 2021).
그러나 로드헤더는 장비 자중을 반력으로 이용하기 때문에 TBM처럼 넓은 단면을 한 번에 굴착하기 어렵고, 굴착 가능한 암반 강도가 제한적이다(Park et al., 2013). 암반 강도가 높을 경우, 장비의 추력 및 토크가 증가하고, 버력 발생량은 감소하며, 피크 소모량은 급격히 증가하여 경제성이 저하되는 문제점이 나타난다. 또한 로드헤더 공법은 NATM 공법과 유사하게 굴착-1차 숏크리트-강지보 설치-록볼트-2차 숏크리트의 공정을 수행해야 하므로, 굴착 시간을 최소화하여 후속 공정의 효율성을 확보하는 것이 필수적이다. 따라서 다양한 암반조건에 대응하며 공정의 효율성을 확보하기 위해서는 로드헤더의 굴진 성능을 정확하게 예측할 수 있는 방안이 필요하다.
기존 설계 단계에서 로드헤더의 굴진 성능을 예측하는 방법은 주로 선형 회귀 분석 또는 절삭 시험에 기반한 경험적 예측식(Bilgin et al., 1988; Gehring, 1989; Copur et al., 1998; Thuro and Plinninger, 1999; Balci et al., 2004; Ebrahimabadi et al., 2011)을 사용하고 있으며, 이들 대부분은 적용의 용이성 측면에서 암석의 일축압축강도(unconfined compressive strength, UCS)를 핵심 변수로 사용해 왔다(Park et al., 2013).
최근 인공지능 기술의 발달과 함께 터널 및 암반 분야에서도 인공지능 기법의 활용이 활발해지고 있으며, 머신러닝 기법을 활용한 기계식 굴착 장비의 굴진 성능 예측 연구가 활발히 진행되고 있다(Kim, 2021). 로드헤더 굴진 성능의 더욱 정확한 예측을 위해 UCS, 브라질리언 인장 강도(Brazilian tensile strength, BTS), 암질 지수(rock quality designation, RQD)를 입력 변수로 활용한 다층 퍼셉트론(multi layer perceptron, MLP)과 K-자기조직화 특성지도(Kohonen self-organizing feature map, KOSFM) 모델(Ebrahimabadi et al., 2015), 장비 중량, UCS, RQD를 입력 변수로 활용한 앙상블(ensemble) 모델(Seker and Ocak, 2019), UCS, BTS, RQD, 절리면 각도를 입력 변수로 활용한 인공신경망(artificial neural network, ANN) 모델(Salsani et al., 2014) 등 머신러닝 기법을 활용한 예측 모델 개발 연구가 꾸준히 진행되고 있다.
하지만 국내 현장에서는 최근 로드헤더 장비 도입이 이루어졌고, 굴진 데이터 수집의 제약으로 관련된 국내 연구는 미비한 실정이다. 따라서 국내 로드헤더 굴착 현장 데이터를 수집하고, 이를 활용한 연구의 필요성이 있다고 판단된다.
본 연구에서는 로드헤더를 적용한 국내 터널 굴착 현장에서 작업 시간, 굴진 시간, 피크 교체 시간, 암반 강도, 굴진장, 피크 소모량 등의 굴진 데이터를 수집하였다. 피어슨 상관분석을 통해 예측의 핵심 변수를 선정하였고, 머신러닝 기법에 적용하여 로드헤더 굴진속도 예측 모델을 제안하였다. Random Forest (RF), eXtreme Gradient Boosting (XGBoost), K-Nearest Neighbor (KNN), Deep Neural Network (DNN), Tabular Prior-Data Fitted Network (TabPFN), 총 5가지 머신러닝 기법을 활용하여 모델을 구축하고, 각 기법의 학습 성능을 비교·분석함으로써 예측 결과의 신뢰성과 적용 가능성을 검토하였다.
2. 머신러닝 기법 개요
2.1 Random Forest (RF)
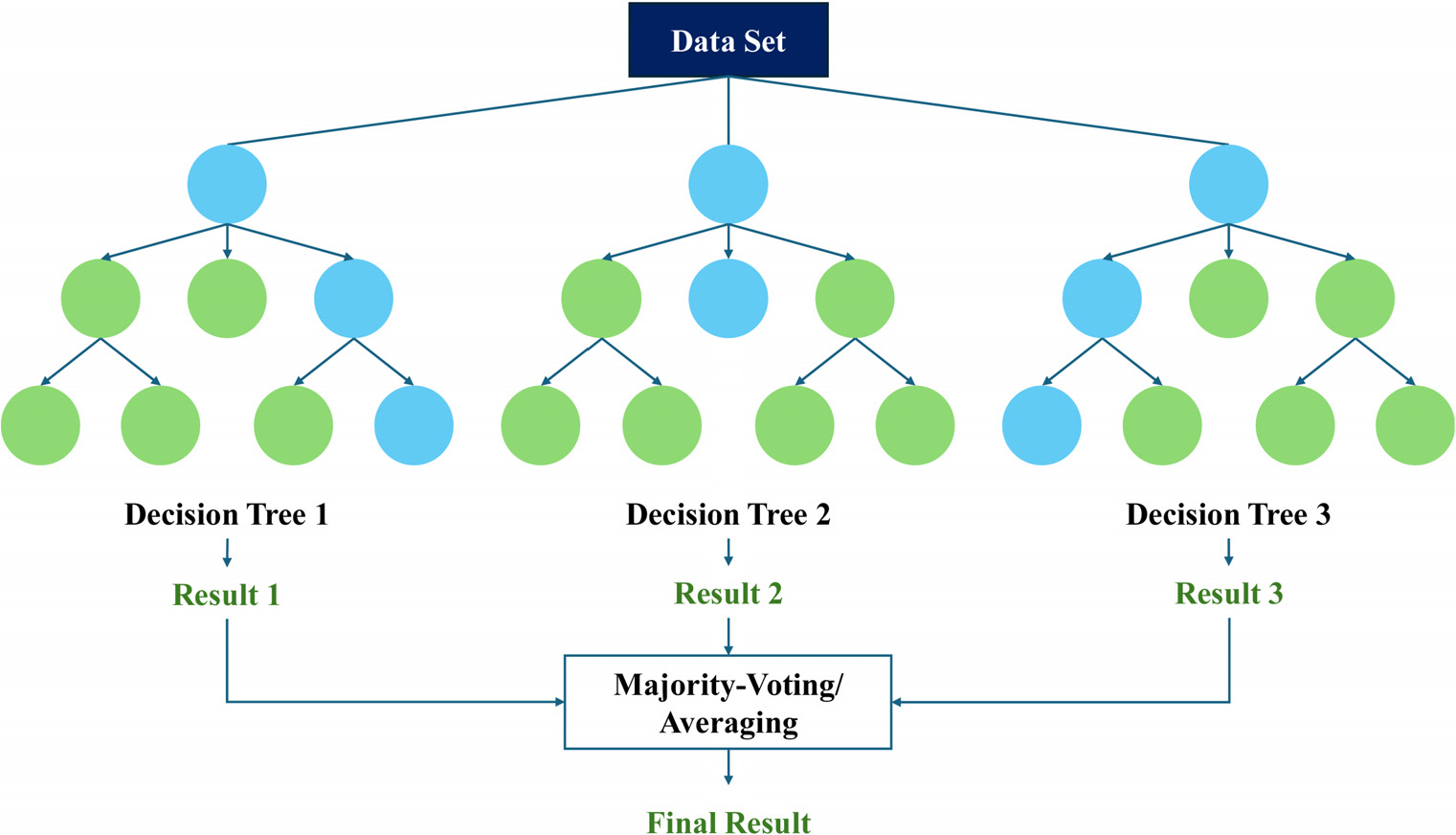
Random Forest는 배깅(bagging) 기법에 기반하여 여러 개의 결정 트리를 학습시키되, 각 트리가 학습할 때 데이터 샘플을 부트스트랩 방식으로 무작위 추출하고, 분기 시점마다 일부 입력 변수를 무작위로 선택하여 사용한다. 이렇게 개별적으로 학습된 트리들의 예측값을 평균함으로써 최종 결과를 도출하는 앙상블 기법이다(Fig. 1). Random Forest는 트리 수가 많아질수록 분산이 감소하여 모델 성능이 안정화되며, 따라서 과적합 위험이 상대적으로 낮다. 또한 이상치가 존재하거나 차원이 높은 데이터에서도 견고한 성능을 발휘하는 것으로 알려져 있다.
2.2 eXtreme Gradient Boosting (XGBoost)
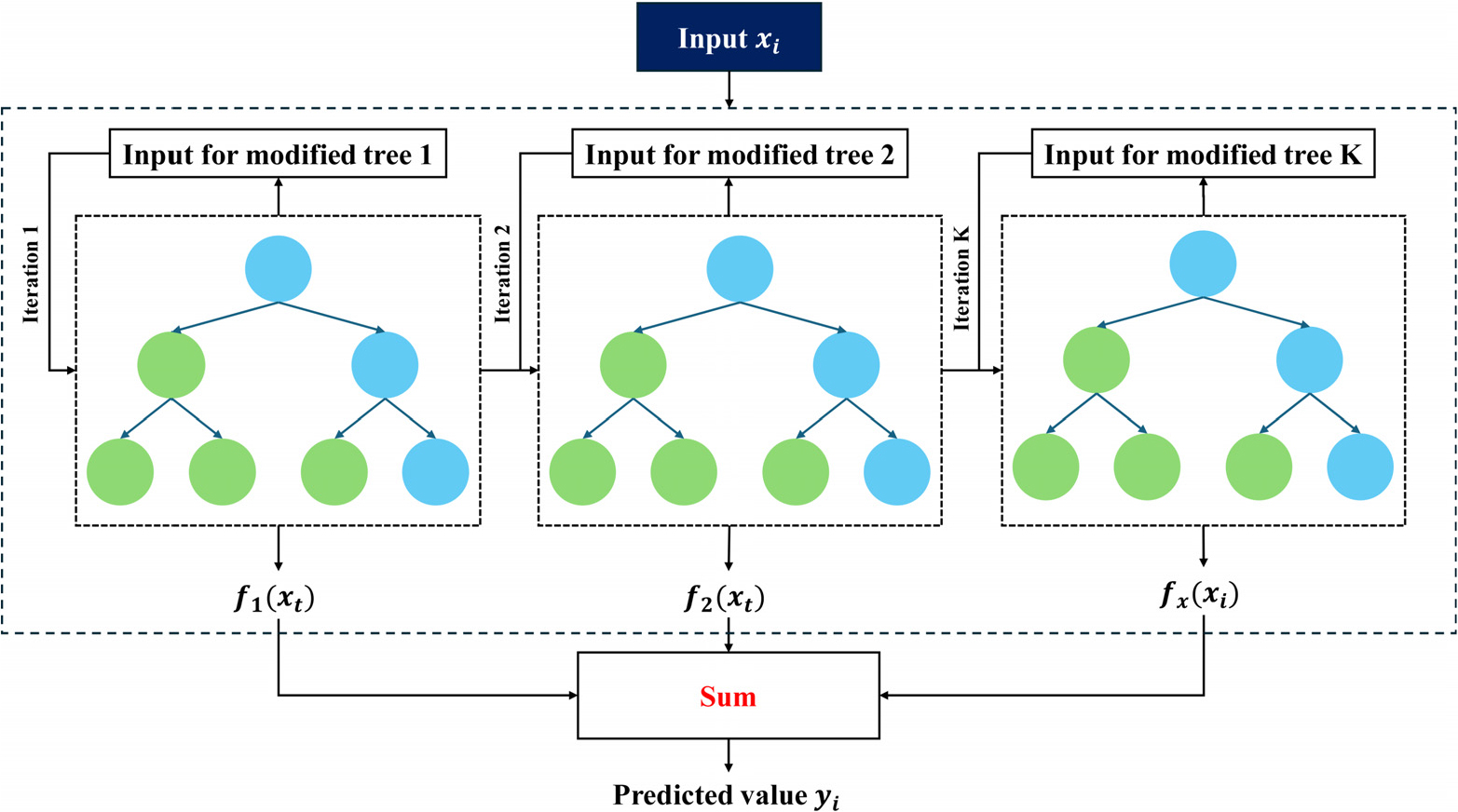
XGBoost는 그래디언트 부스팅(gradient boosting) 방식을 효율적으로 구현한 트리 기반 앙상블 기법으로, 회귀와 분류 문제 모두에서 널리 활용되고 있는 기법이다(Fig. 2). 이 알고리즘은 손실 함수의 그래디언트를 활용하여 이전 단계 모델의 오차를 줄이는 방향으로 새로운 트리를 순차적으로 추가 학습함으로써 성능을 점진적으로 향상시킨다. 다만 하이퍼파라미터의 종류가 많아 최적화 과정이 복잡하고, 데이터가 단순 선형적이거나 표본 수가 적을 경우 모델이 과적합 될 위험이 있다. 그럼에도 불구하고 XGBoost는 정규화 항과 조기 종료와 같은 기법을 포함하여 비교적 안정적인 성능을 제공한다.
2.3 K-Nearest Neighbor (KNN)
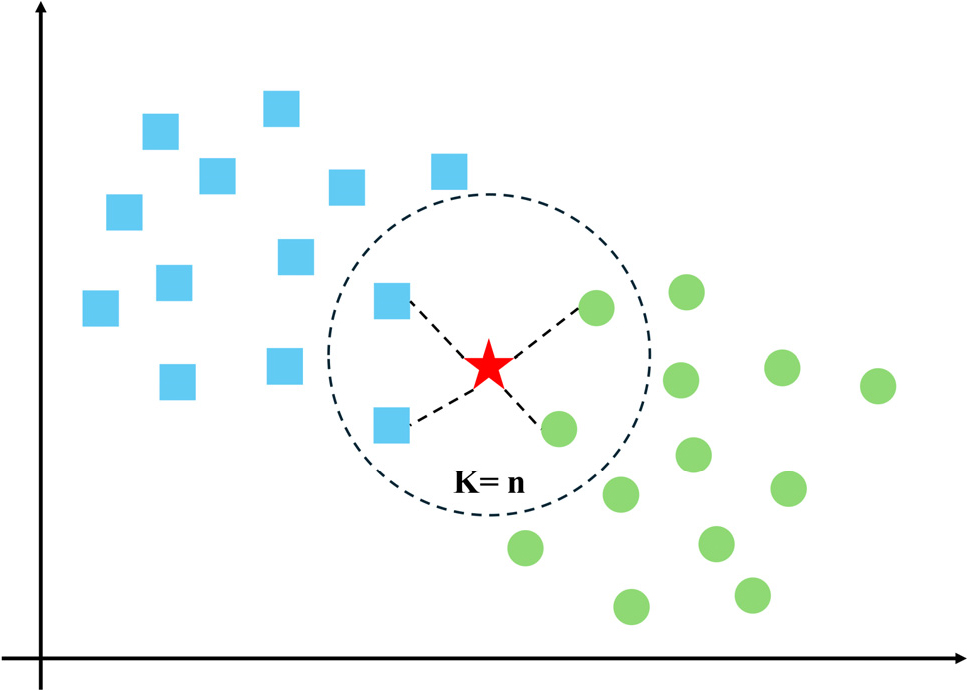
KNN은 가장 단순하고 직관적인 지도 학습 기법으로, 별도의 복잡한 매개변수 학습 과정을 거치지 않고 훈련 데이터를 그대로 저장한 뒤, 예측 단계에서 입력 데이터와 기존 훈련 데이터 간 거리를 계산하여 가장 가까운 K개의 이웃을 탐색한다(Fig. 3). 회귀 문제에서는 이웃들의 목표값을 평균하거나 거리 가중 평균하여, 분류 문제에서는 다수결 원리에 따라 최종 예측값을 산출한다. 이 기법은 특정 함수 형태를 가정하지 않기 때문에 비선형적인 데이터 관계를 유연하게 반영할 수 있다는 장점이 있다.
2.4 Deep Neural Network (DNN)
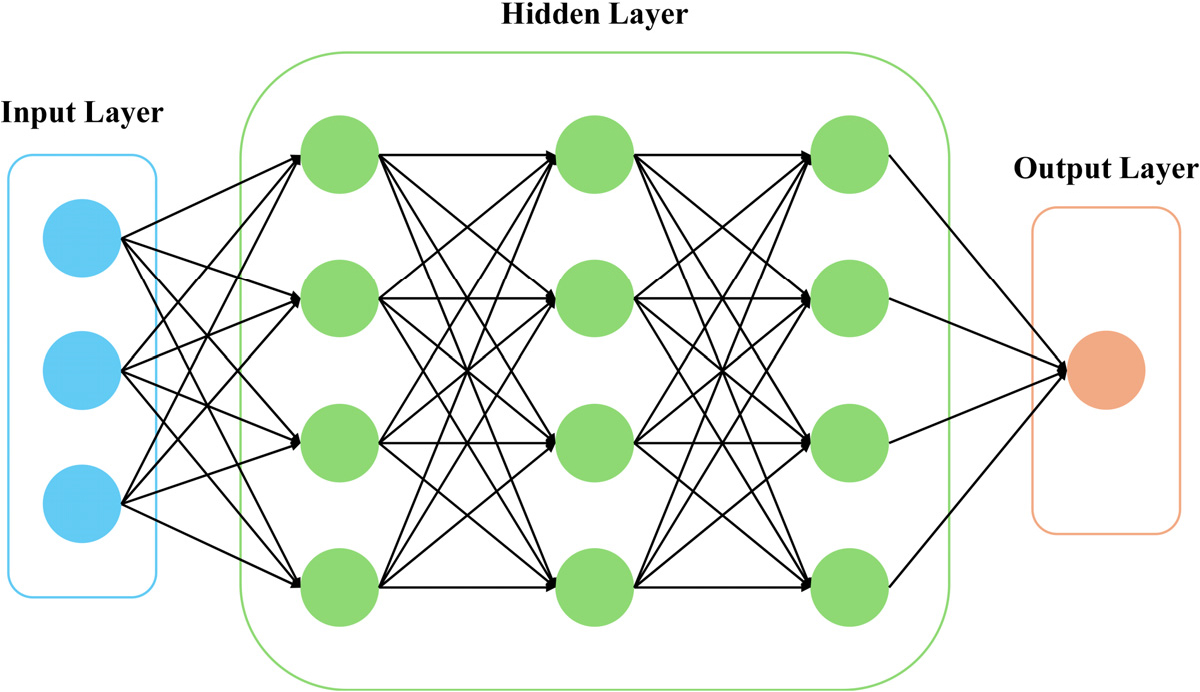
DNN 회귀는 입력층과 출력층 사이에 다수의 은닉층을 배치하여 비선형적이고 복잡한 함수 관계를 효과적으로 학습할 수 있는 모델이다(Fig. 4). 학습 과정에서는 역전파 알고리즘과 경사하강법을 통해 가중치와 편향이 최적화되며, 드롭아웃(dropout), 배치 정규화(batch normalization), 조기 종료(early stopping)와 같은 기법을 통해 과적합을 억제한다. 통계적 모형과 달리 특정한 분포 가정을 거의 필요로 하지 않기 때문에 고차원·대규모 데이터 처리와 복잡한 함수 근사에서 강력한 성능을 발휘한다.
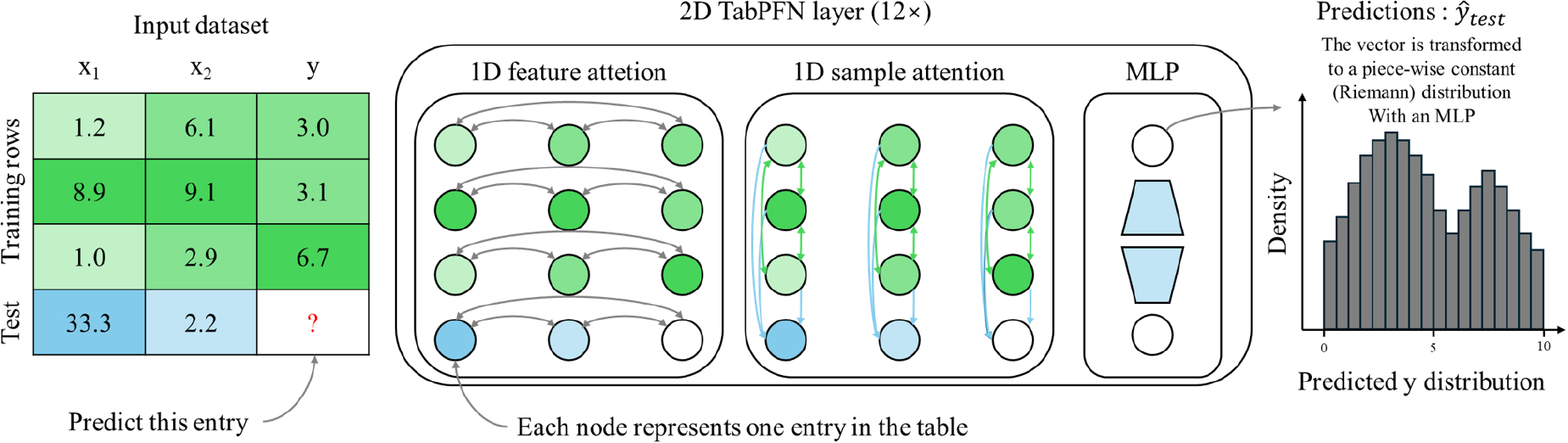
2.5 Tabular Prior-Data Fitted Network (TabPFN)
TabPFN은 소규모 테이블형 데이터 예측을 위해 설계된 사전 학습 기반 모델이다(Fig. 5). 이 모델은 수많은 합성(synthetic) 데이터 분포를 활용하여 대규모 Transformer 네트워크를 사전 학습함으로써, 하이퍼파라미터 조정이나 추가 학습 과정 없이도 새로운 데이터셋에 대해 즉시 예측을 수행할 수 있다. 특히 데이터가 제한적인 환경에서 Random Forest나 XGBoost와 같은 최신 머신러닝 기법과 동등하거나, 경우에 따라서는 그 이상의 성능을 보이는 것으로 보고되었다(Hollmann et al., 2025).
3. 데이터 수집 및 분석
3.1 현장 개요
연구 대상 현장은 총연장 3.31 km의 철도 구간으로, 개착부 454 m와 본선 터널 2,851 m로 구성되어 있다. 굴착은 구간별 암반 조건에 따라 TBM과 대형 로드헤더를 병행 적용하였다. 암반 강도가 100 MPa 이상이고 하저를 통과하는 고위험 구간(1,057 m)에는 쉴드 TBM이, 100 MPa 이하 구간(1,104 m)에는 로드헤더가 적용되었다. 현장에서 사용된 로드헤더는 Sandvik사의 130 t급 Transverse Type 장비(MT720)로, 길이 19.35 m·높이 4.62 m·폭 4.56 m의 대형 장비이며, 일축압축강도 80–140 MPa 범위의 암반을 굴착할 수 있다. 연구 대상 현장의 터널 굴착 단면적은 69.86 m2이며, 총 144개의 피크가 장착되었다. 로드헤더의 구체적인 제원은 Table 1과 Fig. 6에 제시하였다. 로드헤더 굴착은 NATM 공정 중 천공·발파·버력처리 역할을 대체하며, 지보와 보조 지공은 기존 NATM 방식과 동일하게 수행되었다.
Table 1.
Roadheader technical data (Sandvik, 2017)

3.2 로드헤더 굴진 데이터 수집
본 연구에서는 약 1년간의 로드헤더 굴착 기록 중 총 158개 막장 데이터를 수집하였으며, 초기 굴진 구간과 결측된 데이터를 제외한 135개의 데이터를 활용하였다. 굴진장(m), 피크 교체시간(min), 장비 세팅 시간(min), 순굴진시간(min), 막장당 피크 소모량(EA/Face), 부피당 피크 소모량(EA/m3)을 수집하였고, 로드헤더 제작사의 순굴진율 그래프를 기반으로 굴착 부피당 피크소모량을 활용하여 막장별 암반 강도를 추정하였다(Fig. 7). 데이터의 통계치는 Table 2에 제시하였다.
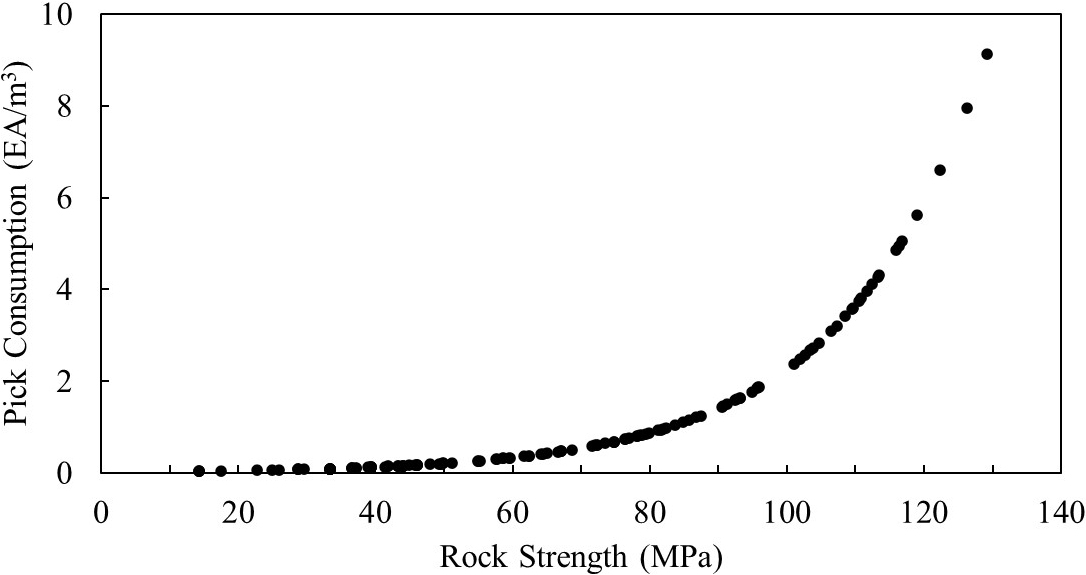
Table 2.
Recorded data of roadheader excavation
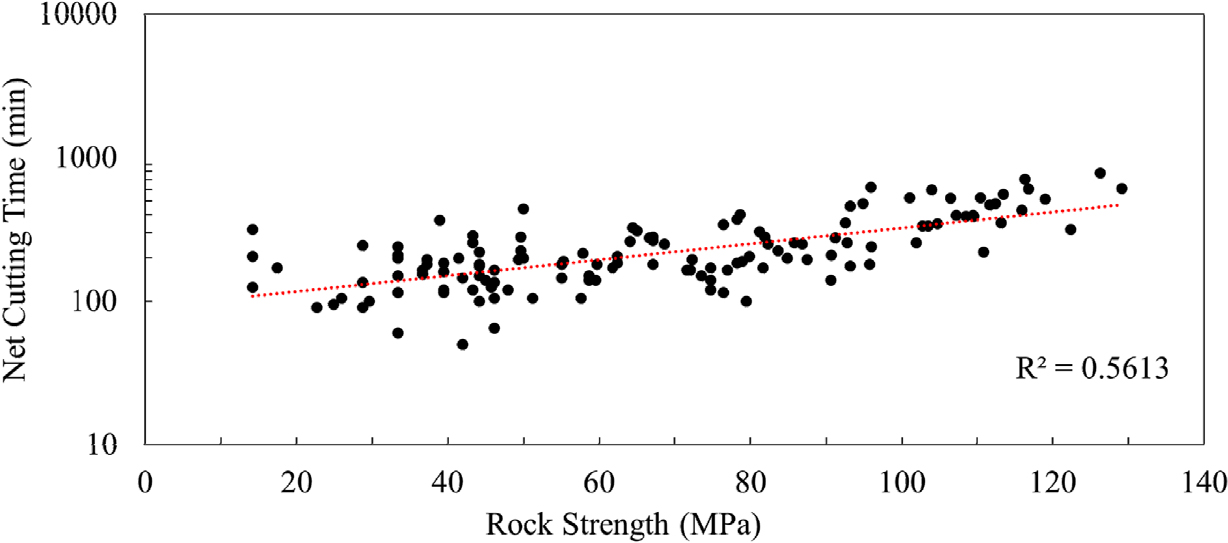
순굴진시간은 평균 245분으로 나타났으며, Fig. 8과 같이 암반 강도-순굴진시간 관계 그래프를 도출한 결과 암반 강도와의 지수적 관계를 확인할 수 있었다. 피크 교체시간은 평균 94분으로 작업 효율에 직접적인 영향을 주는 요인으로 확인되었으며, 최대 585분에 달해 현장 조건에 따른 변동성이 크다는 점을 확인하였다. 장비 세팅 시간은 평균 34분으로 비교적 안정적인 범위를 보였다.
피크 소모량은 막장당 평균 80개였으며, 최소 2개에서 최대 632개까지 편차가 컸다. 부피당 피크 소모량 또한 평균 1.15 EA/m3로 나타났으나, 최대 9.12 EA/m3까지 기록되어 암반 조건에 따라 피크 마모가 급격히 증가할 수 있음을 시사한다. 암반 강도는 평균 66.8 MPa로, 14.2 MPa에서 129.2 MPa까지 분포하여 연암에서 중경암에 이르는 다양한 조건을 포함하였다.
3.3 머신러닝 학습을 위한 데이터 상관관계 분석
수집된 작업 및 지반 데이터를 대상으로 피어슨 상관분석을 실시하고, 결과를 Fig. 9에 제시하였다. 주요 변수 간의 상관성을 분석하고, 인공지능 학습 모델에 활용할 입력·출력 변수의 적절성을 검토하였다.
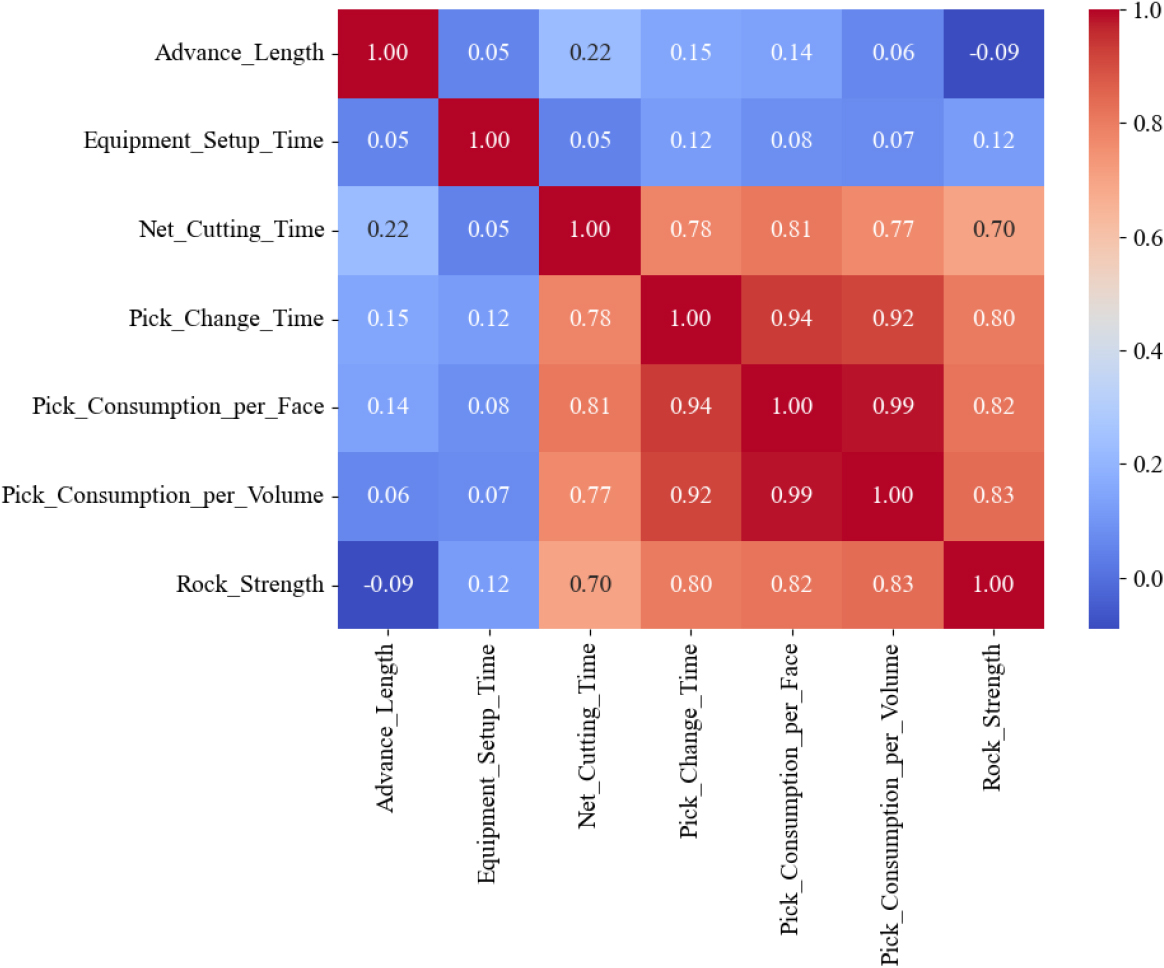
피어슨 상관분석 결과, 순굴진시간은 피크 교체시간(0.78), 피크 소모량(막장당: 0.79, 부피당: 0.77), 암반 강도(0.70)와 높은 상관관계를 보였다. 이는 순굴진시간이 장비 운용 효율, 피크 마모 특성, 암반 강도와 밀접하게 연결되어 있음을 보여준다.
특히 피크 소모량은 암반 강도와 0.82, 0.83의 높은 상관관계를 나타내었으며, 암반 강도의 증가는 절삭 저항과 피크 마모를 증가시켜 절삭 효율 저하 및 순굴진속도의 감소를 야기하고, 지체시간의 증가로 이어지는 것으로 해석된다. 또한 굴진장은 다른 변수들과의 상관계수가 -0.09–0.22 수준으로 낮게 나타났으나, 공정을 직접적으로 반영하는 지표라는 점에서 로드헤더 굴진속도 예측을 위한 입력 변수로 설정하였다.
반면, 장비 세팅 시간은 장비 점검, 정렬, 운반 등의 비굴착 작업에 해당하여 순굴진시간과의 상관관계가 매우 낮게 나타났으며, 피크 교체시간은 피크 소모량과 높은 상관관계를 보여 입력 변수에서 제외하였다.
이러한 분석 결과를 토대로, 본 연구에서는 입력 변수로 막장당 피크 소모량, 암반 강도, 굴진장을 선정하고, 출력 변수는 순굴진시간으로 설정하였다.
4. 예측 모델 개발 및 분석
4.1 예측 모델 개발
본 연구에서는 로드헤더 굴진 데이터를 활용하여 총 다섯 가지 예측 모델을 구축하였다. 적용된 모델은 RF, XGBoost, KNN, DNN, TabPFN이며, 각 모델의 특성과 데이터 규모에 적합한 하이퍼파라미터를 탐색하여 구축하였다. 모델 구축 시, 전체 데이터셋에 대해 스케일링(scaling) 기법을 적용하여 암반 강도, 굴진장, 막장당 피크 소모량, 순굴진시간을 동일한 범위로 정규화하여 학습에 활용하였다. 데이터셋은 무작위로 분할하여 학습 데이터(80%)와 테스트 데이터(20%)로 구성하였고, 테스트 데이터를 통해 모델의 학습 성능을 비교·분석하였다.
RF와 XGBoost 모델은 주요 하이퍼파라미터 최적화를 위해 K-Fold 교차검증 기반의 RandomizedSearchCV를 적용하였다. RF 모델에서는 트리 개수(number of estimators), 최대 깊이(maximum depth), 최소 분할 샘플 수(minimum samples to split) 등을 탐색하였으며, XGBoost 모델에서는 학습률(learning rate), 최대 깊이, 최소 손실 감소량(minimum child weight), 서브 샘플링 비율 등을 조합하여 최적의 성능을 도출하였다.
KNN 모델은 K-Fold 교차검증 기반의 GridSearchCV를 활용하여 최적의 이웃 개수(k)와 거리 측정 방식, 가중치 부여 방식을 체계적으로 탐색하였다. 이를 통해 국소적 데이터 분포를 가장 잘 반영하는 파라미터 조합을 도출하였다.
DNN 모델은 하이퍼파라미터를 직접 탐색하는 방식으로 구현하였다. 은닉층의 층수, 학습률, 드롭아웃 비율, 배치 크기(batch size) 등을 반복적으로 조정하였으며, 학습 과정에서는 최적화 알고리즘과 조기 종료 기법을 도입하여 과적합을 방지하였다.
마지막으로 TabPFN은 사전 학습된 거대 신경망을 기반으로 소규모 데이터셋에서도 별도의 하이퍼파라미터 조정 없이 즉시 예측이 가능하기 때문에, 본 연구에서는 별도의 최적화 과정을 수행하지 않고 기본 설정 그대로 예측 모델 성능을 비교·검증하였다.
모든 모델은 동일한 입력 변수와 출력 변수를 사용하였다. 성능 평가는 결정계수(R2)와 평균 제곱근 오차(root mean square error, RMSE), 평균 절대 오차(mean absolute error, MAE)를 기준으로 수행하였고, 결정계수는 식 (1), 평균 제곱근 오차는 식 (2), 평균 절대 오차는 식 (3)과 같이 표현된다. 결정계수는 모델의 설명력을, 평균 제곱근 오차는 예측값과 계측값 간의 평균적인 오차 크기, 평균 절대 오차는 예측값과 계측값 간의 절대적인 차이의 평균을 의미하는 지표이다. 세 지표를 통해 각 모델의 신뢰성과 예측 정확성을 종합적으로 검토하였다. 여기서, 는 계측된 값, 는 계측된 값의 평균값, 는 예측된 값이다.
4.2 예측 모델 학습 성능 분석 및 비교
각 머신러닝 모델(RF, XGBoost, KNN, DNN)을 구축하는 과정에서 탐색 된 최적 하이퍼파라미터를 Table 3에 정리하였다. TabPFN의 경우 세부 하이퍼파라미터의 조정이 별도로 이루어지지 않았다.
Table 3.
Machine Learning model hyperparameters
계측된 굴진속도와 예측된 굴진속도를 비교하기 위해 모델별 비교 산점도를 Fig. 10에 도시하였다. RF, XGBoost, KNN, DNN, TabPFN 모델의 결정계수를 확인하였을 때, 각각 0.63, 0.58, 0.56, 0.68, 0.72, 평균 제곱근 오차를 확인하였을 때, 각각 1.54, 1.63, 1.67, 1.43, 1.34로 산출되었다. 그리고 평균 절대 오차를 확인하였을 때, 각각 1.18, 1.30, 1.29, 1.04, 1.07로 산출되었다.
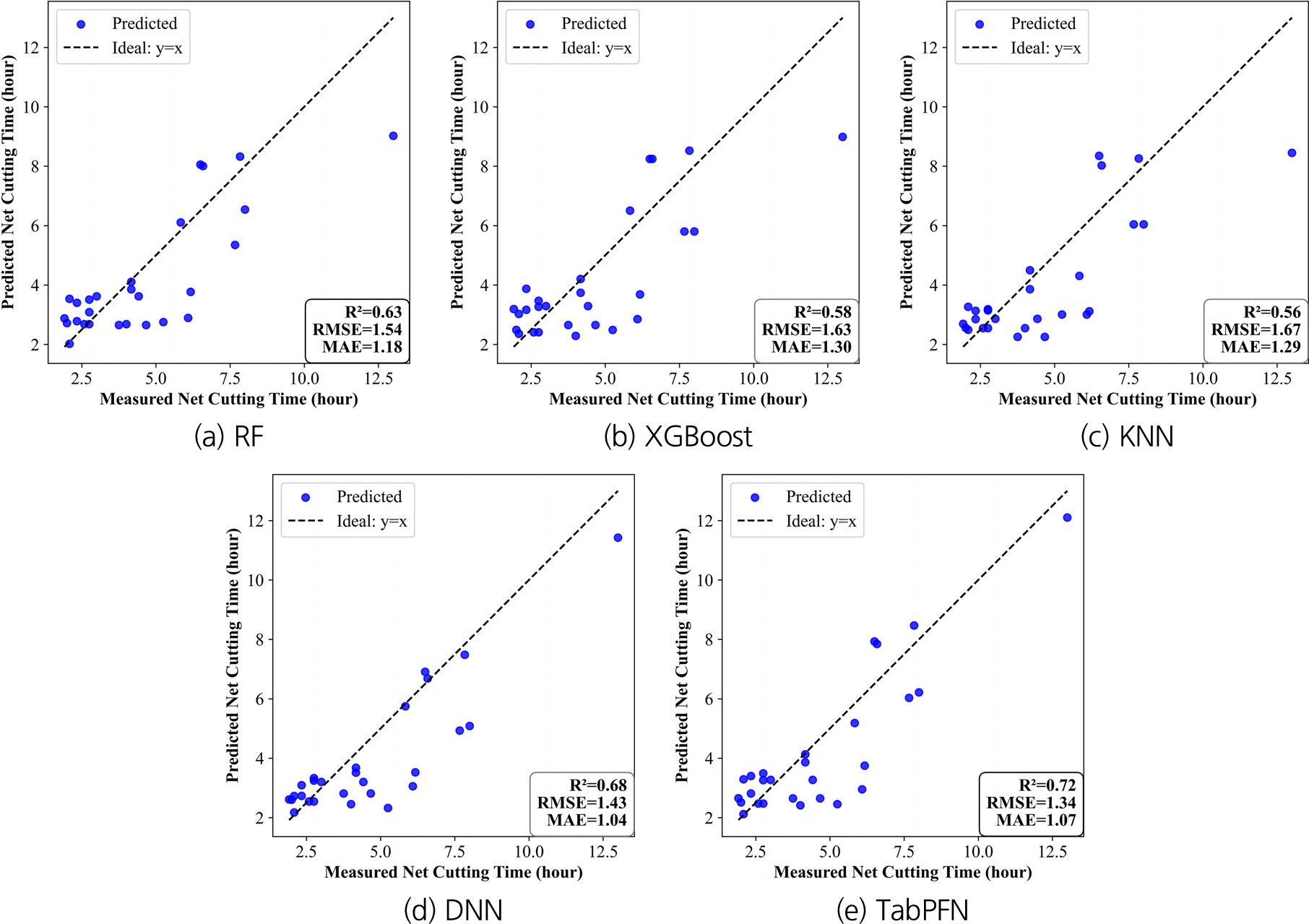
Fig. 10을 통해 모델 학습 성능을 비교해 보았을 때, RF, XGBoost, KNN 모델은 낮은 결정계수(R2 = 0.56–0.63)와 비교적 높은 오차(RMSE = 1.54–1.67, MAE = 1.18–1.30)를 기록하며 소규모 데이터셋에서 예측 성능이 제한적임을 확인하였다. 반면 DNN과 TabPFN 모델은 R2 = 0.68, 0.72, RMSE = 1.43, 1.34, MAE = 1.04, 1.07로 상대적으로 우수한 성능을 나타내었다. 이는 변수 간 비선형 상호작용을 효과적으로 학습한 결과로 판단된다. 특히 TabPFN 모델은 소규모 데이터셋에서 사전 학습 기반 모델을 활용하여 일반화 성능을 확보할 수 있음을 확인하였다.
5. 결 론
본 연구에서는 국내 로드헤더를 사용한 터널 시공 현장에서 수집된 굴진 데이터를 기반으로, 5가지 머신러닝 기법(RF, XGBoost, KNN, DNN, TabPFN)에 적용하여 로드헤더 굴진속도 예측 모델을 개발하였다. 각 모델의 학습 성능을 비교·분석함으로써 현장에서 수집된 데이터에 적합한 머신러닝 기법을 검토하였다. 이를 통해 도출된 결론은 다음과 같다.
1. 현장에서 135개의 막장별 로드헤더 굴진 데이터를 수집하고, 피어슨 상관분석을 진행하였다. 이를 통해 순굴진시간과 수집 데이터 간의 상관관계를 확인하였으며, 암반 강도, 굴진장, 막장당 피크 소모량을 입력 변수로 선정하였다.
2. RF, XGBoost, KNN, DNN, TabPFN, 총 5가지 머신러닝 기법을 활용하였고, 수집된 데이터에 적합한 하이퍼파라미터를 탐색하여 로드헤더 굴진속도 예측 모델을 개발하였다. 본 연구에서 개발된 예측 모델은 단일 현장 데이터를 기반하여 통계적 신뢰도와 일반화 가능성 측면에서 한계가 존재한다. 소규모 데이터셋에 대한 한계를 인식하고, 자동 탐색 및 반복적 조정을 통해 각 모델의 하이퍼파라미터를 최적화하였으며, 다중 성능지표 평가를 통해 통계적 신뢰성과 예측 안정성을 확보하고자 하였다.
3. RF 모델은 데이터의 변동성에 강건한 특성을 보인다. 그러나 본 연구의 데이터셋 규모가 제한적이고, 입력 변수 간 상관성이 부분적으로 높은 특성을 보여 분산이 과대하게 반영되는 한계가 나타났으며, 비교적 낮은 일반화 성능을 보였다.
4. XGBoost 모델은 데이터셋 학습 표본의 수가 제한되고, 입력 변수의 분포 편차가 크기 때문에 과적합을 억제하는 과정에서 예측값이 보수적으로 수렴하는 양상이 나타났으며, 이로 인해 상대적으로 큰 예측 오차를 기록하였다.
5. KNN의 낮은 성능은 거리 기반 접근 방식의 한계로 인해 입력 변수 간의 복잡한 상호작용을 충분히 반영하지 못한 것으로 판단된다.
6. DNN 모델은 비선형적 관계를 효과적으로 학습하여 암반 강도, 피크 소모량 등 입력 변수 간의 복잡한 상관관계를 반영할 수 있었으며, 비교적 높은 일반화 성능을 확보하였다.
7. TabPFN 모델은 복잡한 하이퍼파라미터 튜닝 과정 없이도 소규모 데이터셋에서 높은 일반화 성능을 보였다. 사전 학습된 확률 분포를 기반으로 데이터를 추론하기 때문에, 데이터 수가 적거나 불균형한 상황에서도 과적합 위험을 줄일 수 있었다. 특히 주요 인자 간의 비선형·지수적 상관관계를 명시적인 함수식 없이도 효과적으로 포착하였으며, 이를 통해 데이터가 제한된 환경에서도 안정적이고 신뢰성 있는 예측이 가능함을 확인하였다.
8. 향후 연구에서는 동일한 로드헤더가 적용된 타 현장에서 지반 조건, 장비 운용 데이터 등을 추가 수집하고, 모델의 일반화 성능 검증 및 입력 변수의 확장을 수행할 계획이다.
9. 로드헤더의 굴진속도 예측 모델 개발은 실제 시공 단계에서 막장별 굴진시간의 변동을 사전에 예측하여 장비 운영계획을 최적화하고, 암반 강도 및 굴진조건 변화에 따른 공정 지연을 조기에 인지함으로써 불필요한 장비 대기시간을 최소화하며, 시공비 절감에 기여할 수 있을 것으로 기대된다.
