

1. 서 론
2. 실험 방법
2.1 학습 데이터 수집
2.2 터널 영상 취득 시스템 데이터셋 가공
2.3 딥러닝 모델 학습
3. 실험 결과
3.1 딥러닝 모델별 성능 평가
3.2 손실함수별 성능 평가
4. 결 론
1. 서 론
현재 우리나라 지하 시설물 안전점검은 점검자가 육안검사를 통해 해당 시설물의 이상 유무를 파악하고 기록하는 방식으로 이루어진다. 인력기반 시설물 점검 결과는 검사자의 기술이나 경력에 따라 신뢰도 차이가 발생하여 지속적인 이력 관리가 어렵다. 이러한 한계를 극복하고자 터널 내부 점검 영상을 취득하고 영상 기반으로 전문가 검사와 이력 관리가 이루어지는 방식이 도입되었다. 하지만 취득한 영상을 전수검사하기 위해서는 여전히 많은 시간과 비용이 소요된다. 이에 이를 자동화하기 위한 연구들이 많이 수행되고 있고, 특히 균열을 자동으로 검출하는 연구들이 시도되고 있다. 전통적으로 머신러닝 기법을 적용해왔는데, 높은 수준의 학습이 어렵고 영상에 포함된 복잡한 정보를 처리하기 어려운 한계가 존재했다(Hsieh and Tsai, 2020). 최근에는 딥러닝 기법으로 적용하여 다양한 환경과 조건에 따른 높은 수준의 복잡한 균열의 특징을 자동으로 학습하여 성공적으로 균열을 검출하고 있다. 이때 균열 탐지에 적용하는 딥러닝 모델로 객체 탐지 모델이나 의미론적 분할 모델을 활용한다. 객체 탐지 모델의 경우 균열은 사람이나 차량처럼 정형화된 개별 객체로 정의되지 못하기 때문에 탐지 성능의 한계를 보인다. 이에 최근에는 의미론적 분할 모델을 적용하여 영상의 모든 개별 픽셀별로 균열 여부를 추정하여 균열의 위치와 형태를 정교하게 탐지한다. 그 중 Hadinata et al. (2021)은 콘크리트 표면의 균열 탐지를 위해 인코더와 디코더 구조의 심층 신경망인 U-net과 DeepLabv3+을 적용하여 그 성능을 비교하였다. Li et al. (2021)은 도로포장의 균열탐지를 위해 차량 탑재 카메라로 취득된 영상에 U-net을 적용하였다. 특히 U-net의 skip connection을 짧게 연결하여 성능을 개선했다. Ji et al. (2020)은 아스팔트 포장도로 영상과 DeepLabv3+ 모델을 사용하여 균열을 탐지하였다. Crack W-Net (Han et al., 2021), DeepCrack (Zou et al., 2018), Tiny-Crack-Net (Chu et al., 2022) 등 기존 U-net을 변형하여 탐지 정확도를 높이고자 하는 연구들도 진행되었다.
또한 딥러닝 모델의 성능은 입력 데이터에 큰 영향을 받는다. 특히 균열 영상은 전체 화소 대비 균열에 해당하는 화소가 차지하는 비율이 배경(background)에 비해 현저히 적은 특징을 가진다. 이러한 데이터 불균형으로 인해 딥러닝 모델 학습이 적절하게 이루어지지 않을 수도 있다. 데이터 불균형은 학습의 편향을 야기하여 딥러닝 모델의 성능을 낮추는 원인이 되기 때문에 딥러닝 분야에서 매우 중요한 문제이다(Johnson and Khoshgoftaar, 2019). 따라서 이를 보완하여 균열 탐지 성능을 높이고자 하는 연구들이 있다. 예를 들어, 고해상도 영상을 전부 딥러닝 학습에 사용하기보다 상대적으로 균열이 많이 포함된 영상을 선별하여 사용한다. 이러한 방식은 한 영상 내에서 균열에 해당하는 픽셀의 비율을 늘려 데이터 불균형을 감소시키는 효과가 있다. Kim et al. (2018)에서는 영상을 패치 단위로 분할하여 균열 비율이 높은 영상만 선택하거나, Han et al. (2022)에서는 슬라이딩 윈도우(sliding window) 방식으로 검토하여 균열이 많이 포함된 영상만을 선택하여 딥러닝 학습에 사용하였다. 추가적으로 균열이 있는 영상만을 증강하기도 한다. Kisantal et al. (2019)은 학습 데이터셋 중 균열이 포함된 데이터에 대해서만 오버샘플링(over-sampling) 방식을 적용하여 데이터를 증강하였다. 이러한 방식들을 통해 균열 탐지 모델 학습에 필연적인 데이터 불균형 문제를 완화하여 탐지 성능을 제고하였다.
대부분의 딥러닝 기반 균열 분할 선행연구는 대규모 공개 데이터셋이나 정교하게 작성된 고품질 균열 레이블을 활용한다. 하지만 공개 균열 데이터셋은 터널 내부에서 발생하는 균열의 특징과 정확하게 부합하지 않는다. 만약 대규모 공개 균열 데이터셋만을 사용하는 경우, 터널 내부에서 발생하는 균열의 특성을 반영하지 못하기 때문에 딥러닝 모델 학습과 추론 시 높은 성능을 기대하기 어렵다. 이에 정교하게 작성된 고품질 데이터를 이용하려면, 이를 구축하기 위해 많은 시간과 비용이 소요된다. 이와 같이 대규모 공개 데이터를 이용하거나 정교한 고품질 데이터를 이용하는 것은 모두 한계가 있다. 이에 대한 대안으로 기존에 영상기반으로 터널 점검을 위해 육안검사를 통해 작성된 균열 자료를 활용할 수 있다. 다만, 균열의 형태를 정교하게 표현하지 않고, 개략적으로 단순화하여 작성된다. 현행 시설물 점검 지침에 따라 균열 발생 부위, 폭을 정량적 지표로 하여 안전등급을 평가하기 때문에 균열의 정확한 형상을 반영하기보다는 영상 내 균열의 위치, 폭과 길이 정보를 중점적으로 포함하는 것이 중요하기 때문이다. 고품질 데이터만큼 정교하지 않지만, 공개 데이터셋보다 훨씬 점점 대상인 터널 균열과 유사한 특성을 가지며 이미 구축되어있기 때문에 레이블링에 추가 비용 없이 대량으로 확보할 수 있다.
균열 탐지에 있어 균열의 정교한 형태를 반영한 고품질 데이터셋을 대량으로 구축하기 어려운 한계를 극복하고자 여러 선행연구에서는 상대적으로 취득이 용이한 저품질 데이터를 활용하는 방법을 제안하고 있다. Rolnick et al. (2017)은 의도적으로 생성한 noisy labeled data를 딥러닝 모델에 입력하여 충분한 성능을 달성할 수 있음을 확인하였다. Kaiser et al. (2017)은 대규모 저품질 데이터를 사용하여 도로 분할 성능 향상을 확인하였고, Maggiori et al. (2016)은 불완전한 데이터로 사전학습한 모델에 소량의 수작업 레이블링 데이터를 파인튜닝(fine-tuning)하여 분할 성능을 개선하였다.
따라서 본 연구에서는 터널 균열 점검을 위해 구축된 기존 균열 자료를 딥러닝 학습에 활용하는 방법을 제안한다. 사람이 직접 영상에서 균열을 확인하고 위치와 형상을 그려내는 기존 방식을 자동화하기 위해 효과적인 딥러닝 모델, 데이터셋의 구성, 손실함수를 확인하고 적용하고자 한다.
2. 실험 방법
본 연구는 터널 영상 취득 시스템의 데이터로부터 딥러닝을 적용하여 균열을 자동으로 탐지하고자 한다. 다만 터널 영상 취득 시스템은 터널 점검에 있어 영상 기반 육안검사를 위한 목적으로 설계되었기 때문에, 취득된 데이터를 딥러닝에 적합한 데이터로 변환하기 위해 일련의 데이터 가공과정을 거쳐야 한다. 정교한 균열 레이블을 새로 생성하는 시간을 단축하고 탐지 성능을 높이기 위해 기존 균열 자료를 활용하는 방안을 제안한다. 기존 균열 자료는 일반적으로 딥러닝에서 사용하는 정교한 레이블은 아니지만 탐지하고자 하는 터널 균열과 동일한 환경에서 취득되었기 때문에 딥러닝 모델 학습에 도움이 되리라 예측할 수 있다. 이를 검증하기 위해 학습 데이터셋을 레이블 성격에 따라 구분하고 성능을 비교하고자 한다. Ham et al. (2021)의 터널 영상 취득 시스템으로 취득한 고해상도 영상을 딥러닝 모델에 입력할 수 있도록 전처리하고 512 by 512화소로 자른다. 이에 데이터 증강 기법을 적용하여 딥러닝 모델 성능을 향상하고자 한다. 터널 영상 취득 시스템의 데이터는 균열의 특성을 고려한 일련의 가공을 통해 딥러닝용 데이터셋으로 생성한 후 레이블에 따라 구분한다. 총 5가지 조합의 학습 데이터셋을 구축하고 딥러닝 모델에 입력한 후 터널 영상 취득 시스템의 데이터를 이용하여 성능을 평가하고 비교한다. 연구는 Fig. 1과 같이 진행한다.
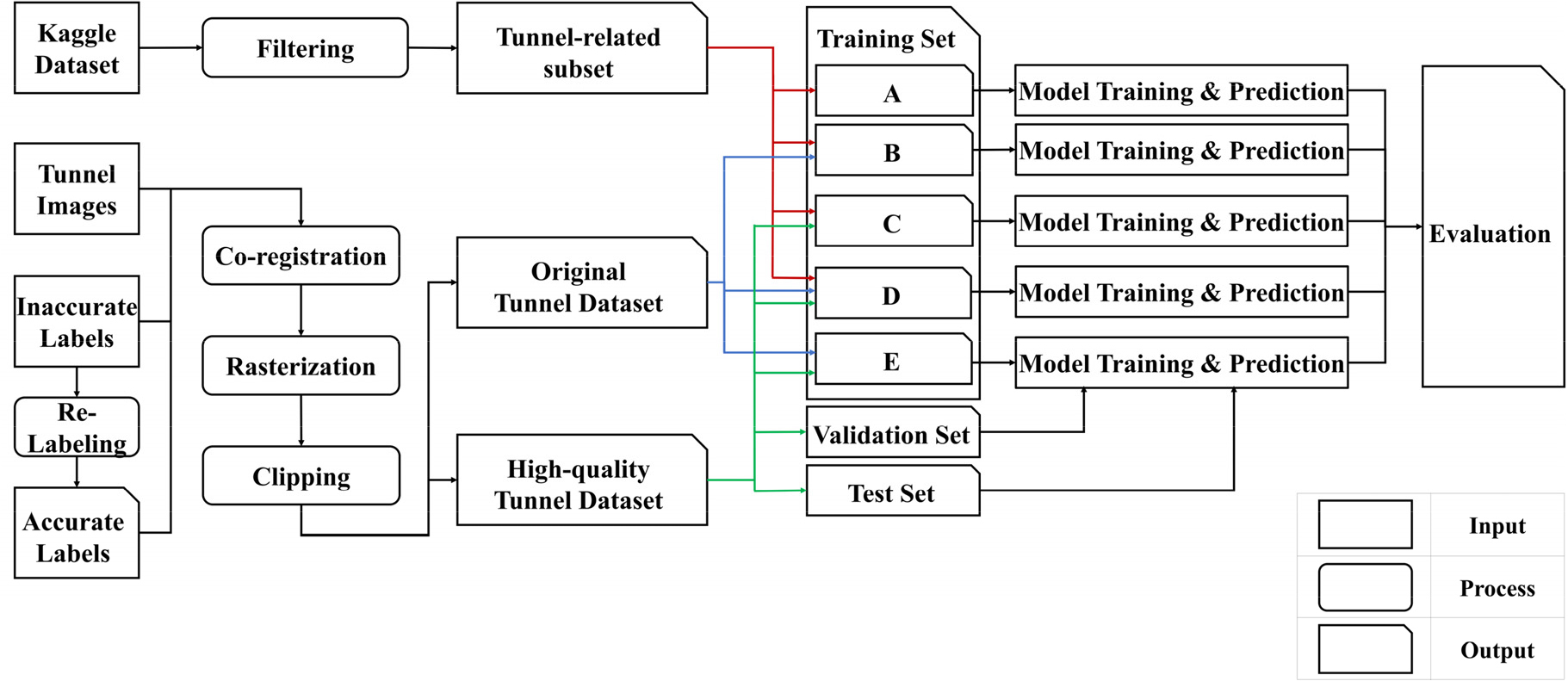
2.1 학습 데이터 수집
딥러닝 모델 학습을 위한 공개 데이터셋으로는 예측모델 및 분석 대회 플랫폼인 Kaggle에서 제공하는 Crack Segmentation Dataset (Middha, 2022)을 사용한다. 이는 CFD (Shi et al., 2016), cracktree (Zou et al., 2012), GAPs384 (Eisenbach et al., 2017) 등 12종류 세부 균열 데이터셋을 모아놓은 것으로 균열 영상과 레이블 쌍으로 구성되어 있다. Ham et al. (2021) 연구에서 공개 데이터셋을 전부 학습할 때보다 터널 영상과 유사한 데이터셋을 선별하여 학습하였을 때 균열 탐지 성능이 개선되었기 때문에 본 연구에서도 관련성에 따라 공개 데이터셋을 분류하였다. 터널 영상 취득 시스템의 영상은 큰 골재가 포함되지 않은 콘크리트 표면에서 촬영되었다. 이에 따라 골재가 섞인 아스팔트 표면과 벽돌 혹은 타일로 이루어진 표면 등은 관련성이 없는 것으로 판단하고 선별하였다.
서론에서 기술한 바와 같이 터널 영상 취득 시스템의 균열 자료는 균열의 형상은 다소 단순하게 반영한다. 하지만 딥러닝 학습과 추론을 위해서는 입력으로 균열의 형상이 정확하게 표현된 레이블이 필요하다. 따라서 본 연구에서는 일부 영상에 대해서 추가 레이블 작업을 수행하고 정교한 정답 레이블을 가진 데이터셋을 구축한다. 본 연구에서 사용한 데이터셋별 구분을 용이하게 하기 위해 시설물 안전점검 목적으로 기 구축된 균열 자료를 가공한 데이터셋은 기존 터널 데이터셋, 추가 작업을 통해 생성한 정교한 레이블이 포함된 데이터셋은 고품질 데이터셋으로 정의하였다. 기존 터널 데이터셋과 고품질 터널 데이터셋의 예시는 Fig. 2와 같다.

Table 1과 같이 고품질 데이터 중 일부는 독립적인 검증과 추론 데이터셋으로 구분하여 각 데이터셋으로 학습한 딥러닝 모델의 검증과 추론을 진행한다. 기존 터널 데이터셋은 전부 학습 데이터셋으로만 활용한다.
Table 1.
Tunnel datasets split in training, validation and test sets
| Training | Validation | Test | |
| Original tunnel dataset | 1,176 | ||
| High-quality tunnel dataset | 244 | 80 | 80 |
본 연구에서는 선별한 공개 데이터셋과 두 종류의 터널 데이터셋을 조합하여 Table 2와 같이 5가지 학습 데이터셋을 구축하였다. Dataset-A는 대규모 공개 데이터셋 중 터널 영상과 관련성이 높은 데이터만 선별한 학습 데이터셋이다. Dataset-B는 선별한 공개 데이터셋과 균열 형상을 단순하게 표현하고 있는 기존 터널 데이터셋으로 구축한 학습 데이터셋이다. Dataset-C는 선별한 공개 데이터셋과 새로 레이블 작업을 진행한 정교한 고품질 터널 데이터셋을 포함하는 학습 데이터셋이다. Dataset-D는 선별한 공개 데이터셋, 기존 터널 데이터셋과 고품질 터널 데이터셋을 모두 포함한 학습 데이터셋이다. Dataset-E는 공개 데이터셋 없이 터널 영상 취득 시스템으로부터 만들어진 기존 터널 데이터셋과 고품질 터널 데이터셋이 포함된 학습 데이터셋이다. 각 학습 데이터셋의 크기와 구성은 Table 3과 같다.
Table 2.
Training datasets description
| Dataset | Description |
| A | The tunnel-related subset among Kaggle Crack Segmentation Dataset (Middha, 2022) |
| B | Original tunnel dataset + Dataset-A |
| C | High-quality tunnel dataset + Dataset-A |
| D | Both original and high-quality tunnel datasets + Dataset -A |
| E | Both original and high-quality tunnel datasets |
Table 3.
Statistics of the training datasets
2.2 터널 영상 취득 시스템 데이터셋 가공
딥러닝 모델을 학습하고 추론하기 위해서는 영상과 레이블 쌍이 필요하다. 본 연구의 터널 영상 취득 시스템 최종 산출물은 Fig. 3과 같은 BMP 형식의 스판 영상과 DXF 형식의 균열 자료이다. 따라서 취득한 스판 영상과 균열 자료를 딥러닝용 데이터로 가공해야 한다. 벡터 형태인 스판 영상과 래스터 형태인 균열 자료를 동시에 처리하기 위해 Ham et al. (2021)이 제안한 가공과정을 적용한다. GIS 소프트웨어를 활용하여 스판 영상과 균열 자료를 상호정합하고 균열에 해당하는 화소값은 1, 배경(background)에 해당하는 화소값은 0이 되도록 래스터화한다.
고해상도 스판 영상 원본에서 전체 화소 대비 균열 화소의 비율은 약 0.006%이다. 이러한 데이터 불균형은 딥러닝 모델 학습과정에서 상대적으로 적은 양을 차지하는 균열을 배제하고, 배경에 치우친 학습이 이루어지게 하여 모델 성능 저하의 원인이 된다(Wang et al., 2020). 본 연구에서는 데이터 불균형을 감소하기 위해 Fig. 4와 같은 과정을 거쳐 학습 데이터를 생성하였다. 우선 고해상도 스판 영상에 균열이 존재하는 패치만 분류하여 작은 영역으로 잘라낸다. 50%의 중첩도를 갖도록 패치를 분할하고 그 중에서 균열이 존재하는 영역만을 골라내어 512 by 512화소의 영상 데이터 4,210쌍을 생성하였다. 또한 데이터 증강 기법 중 상하좌우 회전과 반전을 사용하여 1,176쌍의 기존 터널 데이터와 404쌍의 고품질 터널 데이터를 생성하였다. 이를 학습, 검증, 추론 데이터셋으로 나눈 결과는 Table 3과 같다.


또한 균열 자료는 폴리라인(polyline)으로 구성되어 있기 때문에 래스터화를 통해 생성한 레이블에서 균열은 실제 균열의 폭과 관계없이 1화소로 표현된다. 이를 해결하기 위해 모폴로지 연산(morphological operation) 중 팽창(dilation)의 반경(disk)을 3으로 적용한다. 그 결과는 Fig. 5와 같다.

하나의 영상에서 전체 화소 대비 균열 화소의 비율을 계산하고 Fig. 6과 같이 히스토그램으로 표현하였다. 제안된 기법을 적용한 영상별 균열 화소의 비율은 주로 2~3%에 분포하였다. 균열 탐지 학습에 범용적으로 사용되는 Kaggle Crack Segmentation Dataset에서 영상별로 균열에 해당하는 화소 비율이 2%대에 가장 많이 분포하는 것으로 보아 터널 데이터셋의 가공 결과가 딥러닝용 데이터셋으로 활용되기에 적합하다고 볼 수 있다.

Fig. 6.
The percentage of crack pixels in (a) Kaggle Crack Segmentation Dataset (Middha, 2022), (b) The tunnel images
2.3 딥러닝 모델 학습
딥러닝 기반 균열 분할 성능 비교를 위해 균열 탐지에서 대표적으로 사용되는 의미론적 분할 딥러닝 모델인 U-net (Ronneberger et al., 2015)과 DeepLabv3+ (Chen et al., 2018)를 사용한다. U-net은 Contracting Path와 Expanding Path가 ‘U’자형으로 구성되어 있어 기존 분할 모델보다 빠르고 정확한 분할을 수행하도록 설계되었다. DeepLabv3+는 인코더-디코더 구조와 피라미드 풀링 모듈을 결합하여 분할 결과를 개선하도록 설계되었다. 본 연구에서 U-net을 학습하기 위해 배치 크기는 4로 설정하고 Adam 최적화기로 학습을 수행하였다. 학습률(learning rate)은 0.0001부터 시작하여 1e-06까지 학습 진행에 따라 감소하도록 하였다. ResNet-50을 백본(backbone)으로 사용하는 DeepLabv3+도 같은 학습률, 배치 크기, 최적화기를 설정하였다. 학습은 각 모델과 데이터셋별로 총 100 에폭(epoch)을 수행하였다.
딥러닝은 학습 과정에서 모델의 예측값과 정답의 오차를 계산하고 최소화하도록 학습한다. 따라서 오차를 구하는 손실함수는 필수적인 요소이다. 본 연구에서는 Cross Entropy (CE)와 Focal Loss (FL)를 손실함수로 사용하고 데이터셋별 대한 딥러닝 모델 성능을 비교한다. 본 연구에서 사용한 Cross Entropy 손실함수의 식은 식 (1)과 같다. 각 클래스의 손실 비율을 조절하는 가중치()를 곱하여 클래스 불균형을 해결하고자 한다. Focal Loss 손실함수는 식 (2)와 같이 정의되며, Cross Entropy 손실함수에 를 곱하여 학습에 기여하지 않지만 분류하기 쉬운 객체(easy negatives)에 할당되는 가중치를 낮춤으로써 객체와 배경의 학습량을 조절한다(Lin et al., 2017).
Cross Entropy 손실함수에서 는 예측의 결과값이고, 는 클래스별 가중치이다. Focal Loss 손실함수에서 𝛼는 전체적인 손실함수 값을 조절하는 파라미터이고, 𝛾는 easy negative의 가중치를 줄이는 파라미터이다. Lin et al. (2017)에서는 𝛼=0.25, 𝛾=2로 설정하였을 때 가장 높은 성능을 보인 것으로 나타나 본 연구에서도 동일하게 사용하였다.
3. 실험 결과
3.1 딥러닝 모델별 성능 평가
본 연구에서 U-net과 DeepLabv3+의 균열 분할 성능을 비교하기 위한 실험에서 손실함수는 Cross Entropy 손실함수를 사용하였다. 학습된 각 모델의 성능을 비교하기 위해 본 연구에서는 정밀도(precision)와 재현율(recall)을 평가지표로 사용하였다. 정밀도는 딥러닝 모델이 영상 내에서 균열이라고 인식한 모든 부분 중에 실제 균열을 제대로 탐지한 부분의 비율이고, 재현율은 실제 균열 부분 중 딥러닝 모델이 균열이라고 옳게 탐지한 부분의 비율이다. 본 연구의 목적은 실제 균열을 놓치지 않고 탐지하여 시설물의 유지보수에 활용하고자 하기 때문에 재현율이 상대적으로 더 중요한 지표라고 볼 수 있다.
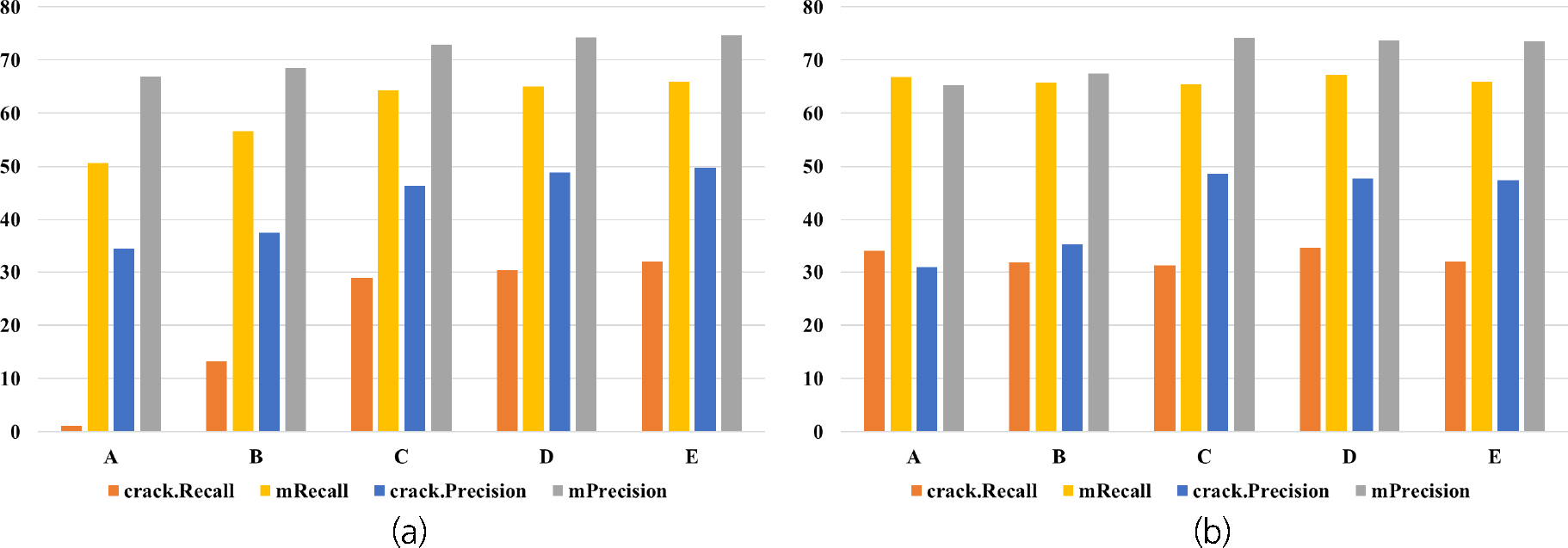
각 딥러닝 모델에 대한 학습 성능은 Table 4와 같이 정리하였으며 Fig. 7은 딥러닝 모델에 대해 학습 데이터별 학습 성능을 막대 그래프로 표현한 것이다. 추론 성능은 Table 5와 같이 정리되며 Fig. 8은 각 딥러닝 모델의 학습 데이터별 추론 성능을 표현한 막대 그래프이다. crack.Precision과 crack.Recall은 균열에 해당하는 픽셀에 대한 정밀도와 재현율이고, mPrecision과 mRecall은 영상 내 전체 픽셀에 대한 정밀도와 재현율을 산출한 것이다. 실험 결과 DeepLabv3+를 사용한 Dataset-D 실험에서 83.82%의 학습 재현율과 67.22%의 추론 재현율을 보였다. 공개 데이터셋과 서로 다른 품질의 터널 데이터셋을 모두 모델 학습에 사용하였을 때, 실제 균열을 놓치지 않고 더 잘 탐지할 수 있음을 알 수 있다. 같은 데이터셋에 대한 딥러닝 모델별 재현율을 비교한 경우 DeepLabv3+를 사용하였을 때 U-net보다 최대 32.85%의 성능 향상 효과가 있었다. 다만 U-net의 경우 영상 전체로부터 충분한 정보를 획득하지 못하는 한계로 인해(Huang et al., 2020) 추론 데이터인 터널 영상 취득 시스템의 데이터와 성격이 크게 다른 공개 데이터셋만 학습하여 추론한 경우 성능이 떨어졌다.
Table 4.
Evaluation of training results
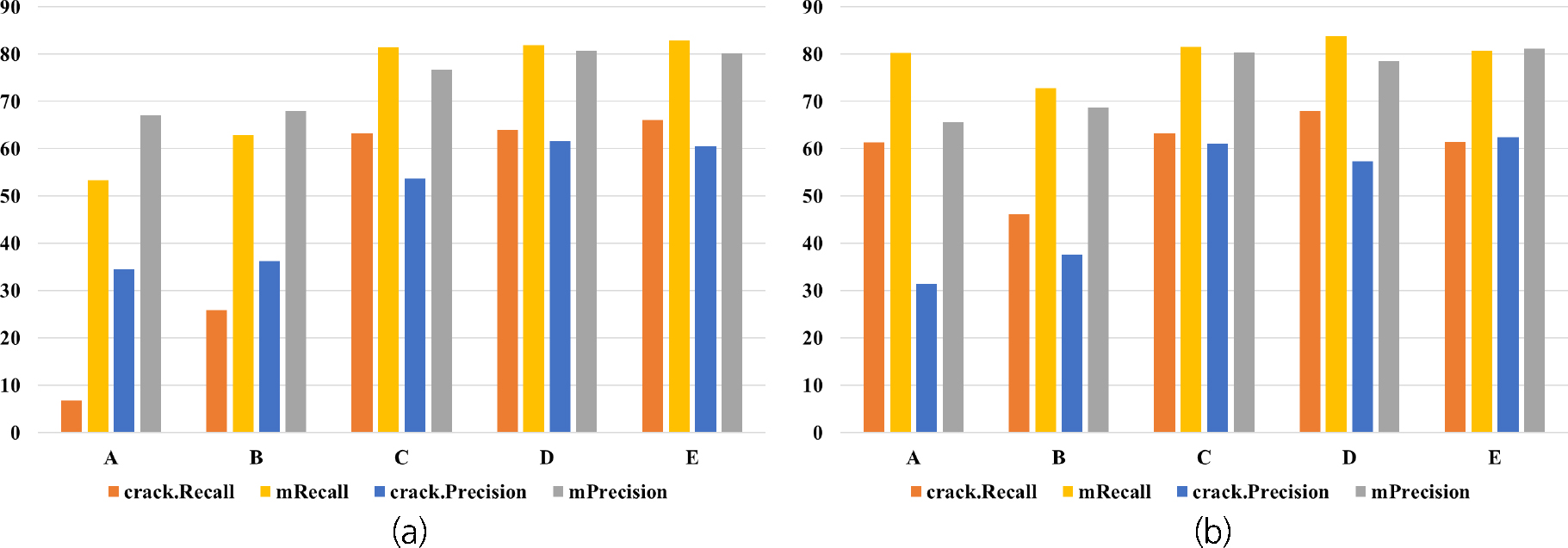
Table 5.
Evaluation of test results
U-net과 DeepLabv3+의 추론 결과 영상은 Fig. 9와 같다. 좌측은 학습된 모델의 추론을 위해 사용한 터널 균열 영상과 정답 레이블이다. 또한 표의 첫 번째 열은 각 데이터셋으로 U-net을 학습하였을 경우 추론 결과이고, 두 번째 열은 DeepLabv3+의 추론 결과이다. 공개 데이터셋만으로 학습하였을 때 터널 영상에 대한 추론 성능이 가장 낮음을 알 수 있다. Dataset-A와 Dataset-B의 경우 균열의 폭을 정답 레이블보다 넓게 추론하는 경향을 보였다. Dataset-E와 공개 데이터셋이 추가된 Dataset-D의 추론 결과는 큰 차이를 보이지 않았다. 따라서 공개 데이터셋을 대량으로 추가하는 것은 균열 분할 성능 향상에 미치는 영향이 크지 않은 것으로 보인다.
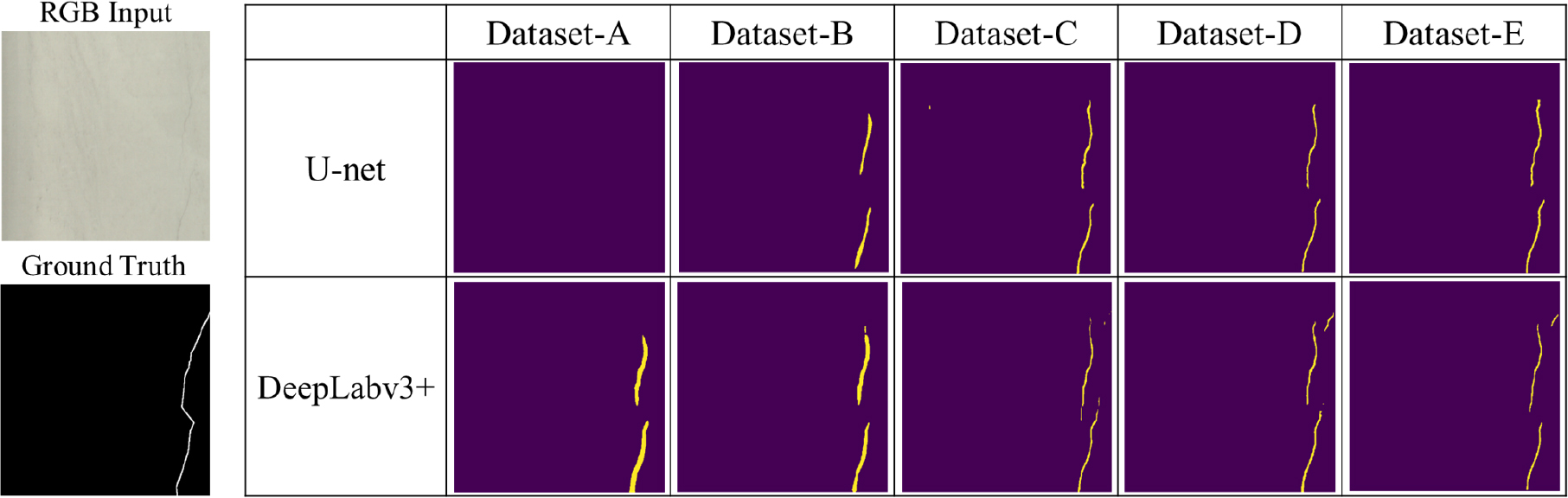
Dataset-B와 Dataset-C의 결과를 비교하여, 대량의 기존 터널 데이터셋을 추가한 경우보다 상대적으로 적은 양이지만 고품질 터널 데이터셋을 추가하였을 때 균열의 폭과 형상이 잘 추론됨을 알 수 있다. 하지만 Dataset -D와 같이 고품질 터널 데이터셋과 함께 대량의 기존 터널 데이터셋을 추가하는 것은 균열 분할 성능 향상에 큰 효과가 있었다. 따라서 어느 정도 고품질 레이블이 구축되었다면 많은 양의 기존 균열 자료를 사용하여 모델 성능 향상에 좋은 영향을 줄 수 있음을 알 수 있다.
Hadinata et al. (2021)에서는 776쌍의 공개 균열 데이터셋을 활용하여 U-net에서 DeepLabv3+에 비해 더 정확한 탐지가 수행되었다. 하지만 공개 데이터셋이 아닌 현장에서 취득하고 작성한 균열 자료를 활용하여 딥러닝 기반 균열 분할을 수행하기 위해서는 DeepLabv3+가 더 적합하다고 판단할 수 있다.
대량의 기존 터널 데이터셋과 소량의 고품질 터널 데이터셋을 모두 딥러닝 모델 학습에 사용한 경우에 균열을 가장 정확하게 탐지하였다. 따라서 기 구축된 균열 자료를 딥러닝 학습에 활용하기 위해서 소량의 고품질 데이터를 생성하는 것이 효과적이라고 생각된다.
3.2 손실함수별 성능 평가
딥러닝 모델 학습의 목적은 손실함수의 값을 최소화하는 매개변수를 찾아내는 것이며, 이러한 과정을 최적화(optimization)라고 한다. 본 연구에서는 최적의 가중치 갱신을 위한 학습률을 조정하고, 손실함수로 Cross Entropy (CE)와 Focal Loss (FL)를 사용하여 균열 분할 성능을 비교하였다. Table 6은 손실함수별 딥러닝 모델의 학습과 추론 성능을 비교한 것이다. 앞선 실험에서 상대적으로 높은 성능을 보였던 DeepLabv3+ 모델과 Dataset-C, D, E를 활용하였다. Fig. 10은 서로 다른 손실함수를 적용하였을 때 정밀도와 재현율을 표현한 막대 그래프이다.
Table 6.
Evaluation of results
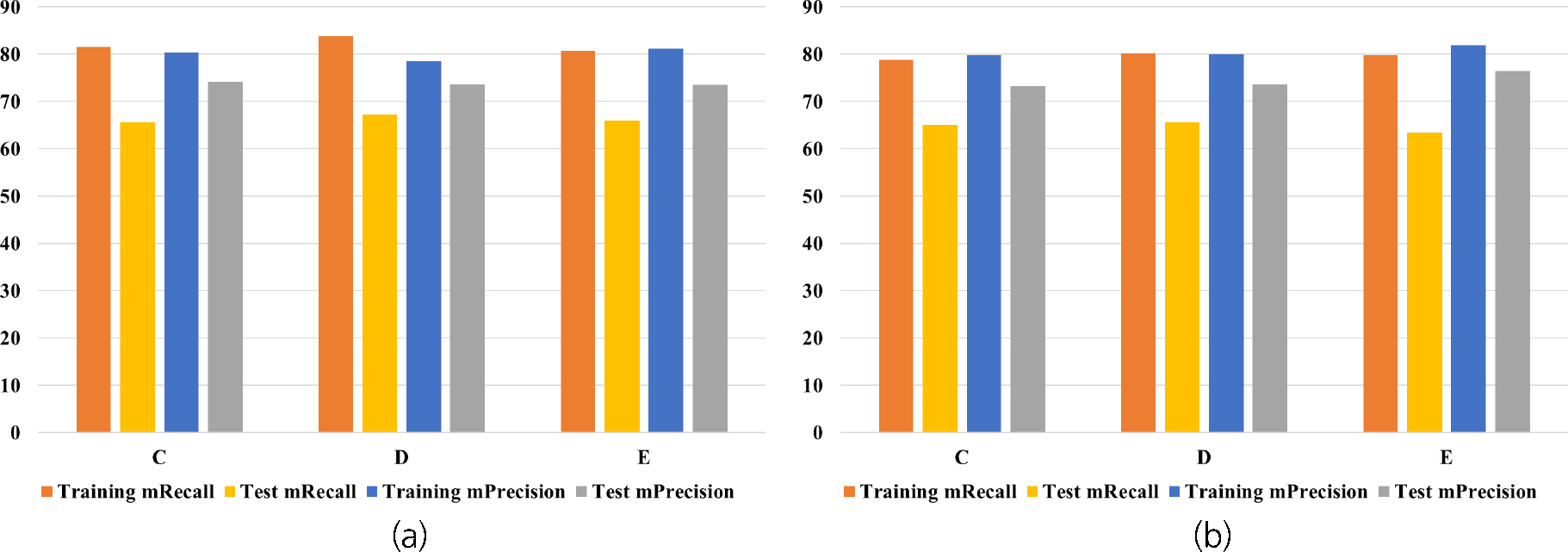
실험 결과 Cross Entropy (CE) 손실함수를 사용한 경우에 균열 재현율이 높았고, Focal Loss (FL)를 손실함수로 사용한 경우에 정밀도가 향상되었다. 이와 관련하여 Shim et al. (2021)에서는 Focal Loss 손실함수를 박락 탐지에 적용하였을 때, 데이터셋의 크기가 작아 Focal Loss 손실함수의 영향이 크지 않은 것으로 분석하였다. Lin et al. (2017)은 Focal Loss 손실함수를 적용하여 대규모의 공개 데이터셋을 학습하여 성능이 향상됨을 확인하였다. 하지만, 본 연구와 같이 대량의 고품질 데이터셋을 취득하기 어려운 경우 Cross Entropy 손실함수를 사용하여 계산 복잡도를 증가시키지 않고 충분한 성능을 달성할 수 있을 것이다.
4. 결 론
본 연구에서는 현행 터널 미세균열 안전점검 방식을 고려하여 기 구축된 균열 자료를 가공하고 딥러닝 기반 균열 분할에 활용하는 방법을 제안하였다. 균열의 특성에 따른 데이터 불균형을 해결하기 위해 패치 단위 분류와 오버샘플링 등 전처리 과정을 수행하였다. 5가지 조합의 학습 데이터셋을 의미론적 분할 모델인 U-net과 DeepLabv3+에 입력하고 추론 성능을 분석하였다. 학습 과정에서는 데이터 불균형을 해결하기 위해 고안된 Cross Entropy 손실함수와 Focal Loss 손실함수를 사용하였다. 그 결과 공개 데이터셋만을 학습에 사용한 경우보다 저품질이더라도 터널 영상 취득 시스템을 통해 생성한 데이터셋을 추가하여 높은 성능을 얻을 수 있었다. 고품질 터널 데이터셋과 기존 터널 데이터셋을 모두 추가하여 학습하였을 때 균열 재현율이 3.41% 향상되어 결과적으로 재현율 67.22%를 달성하였다. 따라서 상대적으로 적은 양의 정교한 균열 레이블을 생성한다면 기 구축된 대량의 균열 자료를 딥러닝 학습에 활용하여 효과적인 성능 향상을 이루어 낼 수 있음을 확인하였다. 향후 연구로는 딥러닝 기반 균열 분할 성능 향상을 위한 기법으로 전이학습을 수행한다면 좋은 성능을 얻을 수 있을 것이다.
