

1. 서 론
1.1 콘크리트 구조물에 대한 유지관리의 필요성
1.2 콘크리트 표면 손상 탐지를 위한 선행연구
2. 학습용 콘크리트 손상 영상
2.1 콘크리트 박락 영상의 확보
2.2 학습을 위한 데이터 구성
3. 박락 탐지를 위한 심층 신경망 알고리즘
3.1 심층 신경망의 구조
3.2 향상된 손실 함수
3.3 영상 데이터 증강
4. 실험 결과 및 분석
4.1 평가 기법 및 실험 환경
4.2 인식 성능 비교
4.3 인식 결과 비교
5. 결 론
1. 서 론
1.1 콘크리트 구조물에 대한 유지관리의 필요성
콘크리트 구조물에 대한 유지관리를 위해서는 우선적으로 표면에 발생하는 손상을 점검하는 것이 중요하다. 특히 터널 라이닝 콘크리트에 대한 유지관리가 올바르게 되지 않을 경우 안전사고의 요인으로 작용할 수 있어 그 중요성은 더욱 커진다(Fujino and Siringoringo, 2020). 이러한 콘크리트 구조물은 주로 노후화, 열에 의한 팽창과 수축, 그리고 지형 변화와 같은 요인으로 인해 상태가 훼손된다(Zhang et al., 2014). 무엇보다 파손은 가장 먼저 균열의 형태로 나타난다. 다음으로 훼손이 점진적으로 진행되며 박락의 형태로 변형되어 내부 철근이 일부 노출된다. 이러한 손상은 사용자에게 불편을 야기할 뿐만 아니라 구조적인 안정성에도 부정적 영향을 미친다(Hoang, 2018). 따라서 이러한 손상은 필연적으로 보수가 진행되어야 한다. 이를 위하여 콘크리트 표면에 발생하는 손상을 명확히 탐지하는 방법이 필요하다. 더불어 이러한 방법은 주기적인 점검 및 검사를 수행하여 콘크리트 구조물의 상태를 정확히 평가하는 곳에 활용되어야 한다(Hoang et al., 2019).
본 논문에서는 구조물의 손상 종류 중 박락을 탐지하는 방법에 관해 연구를 수행하였다. 박락은 충격과 내부 스트레스로 인하여 콘크리트 표면의 일부가 떨어져 나간 현상을 지칭한다. 이 같은 현상은 갑작스럽게 콘크리트 내부로 침투된 수분으로 인하여 입자 간의 접착력이 소실되며 발생한다. 박락은 아무리 표면에서 보이는 크기가 작은 편에 속한다고 하더라도 콘크리트 내부에도 손상이 발생한 것이므로 심각한 상태를 의미한다(Wu et al., 2019). 따라서 콘크리트의 박락은 구조물의 신뢰성과 성능을 현격히 저하시키는 원인이 되어 신속한 보수가 필요한 손상 중 하나라고 할 수 있다. 이 같은 시급성과 중요성을 고려하여 본 논문에서는 콘크리트 박락을 탐지할 수 있는 딥러닝 기반의 영상 인식 기술을 개발했다.
1.2 콘크리트 표면 손상 탐지를 위한 선행연구
콘크리트 시설물 유지관리를 위해 콘크리트 손상을 탐지하는 연구는 크게 균열을 탐지하는 알고리즘과 그 외의 손상을 탐지하는 연구로 구분할 수 있다. 우선 균열을 탐지하기 위해 Fujita and Hamamoto (2011)는 전통적인 영상처리 기법을 적용하여 균열을 탐지했다. 그들은 영상에서 발생하는 잡음을 제거하기 위하여 중간값 필터를 사용하였고, 균열 영역을 강조하기 위해서 다중 선형 필터(multi-scale line filter)를 적용하였다. 또한 확률적 완화와 동적 임계값 기법을 적용하여 균열을 최종적으로 탐지했다. Nishikawa et al. (2012)은 여러 종류의 필터를 순차적으로 적용하여 균열을 탐지했다. 그들의 알고리즘은 크게 두 가지로 구분되는데, 유전자 프로그래밍을 사용하는 방식과 영상 잡음을 효과적으로 제거하는 방식이다. 이와 함께 그들은 탐지한 결과를 기반으로 하여 균열의 폭을 측정할 수 있는 방법을 제안하였다. Dung and Anh (2019)은 완전 합성곱 신경망(fully convolutional network, FCN)을 통한 균열 분류 및 탐지 알고리즘을 제안했다. 그 결과 영상 내에 콘크리트 균열의 존재 여부를 판단할 수 있었고, 더 나아가 균열의 영역까지 화소 단위로 추출할 수 있는 기법을 제안했다. 끝으로 Liu et al. (2019)은 U-Net을 적용하여 균열을 탐지하는 알고리즘을 제시했다. 그들은 총 57장의 영상을 이용하여 학습하고 성능을 검증했다. 그 결과 0.9의 정확도를 얻었고 U-Net의 탐지 성능이 FCN을 사용한 경우보다 더 높다는 것을 보여주었다.
콘크리트에서 발생하는 손상에는 균열 외 다른 종류의 손상들도 있고, 이를 탐지하는 연구들은 지속적으로 수행되어 왔다. German et al. (2012)은 지진 후에 발생한 콘크리트 박락을 영상으로 측정하는 연구를 수행하였다. 그들은 국소 엔트로피 기반의 임계값 알고리즘, 전역 적응형 임계값 알고리즘, 그리고 템플릿 매칭 방식을 활용하여 박락을 탐지하였다. Kim et al. (2015)은 3차원 스캐너를 사용하여 콘크리트 벽면을 스캔하여 포인트 클라우드 형태의 데이터를 취득했다. 이 포인트들을 활용하여 두 가지 연산을 적용했다. 첫째는 연속된 포인트가 이루는 각도 연산이고, 둘째는 정합 평면과의 거리 연산이다. 이를 통해서 포인트 클라이드 내에서 박락 영역의 위치를 탐지하고 물리적인 정보를 측정하였다. 그 결과 3 mm 이상의 박락을 탐지할 수 있는 기술을 개발했다. Dawood et al. (2017)은 비전 기반의 알고리즘을 통해 박락을 탐지하는 방법을 제안했다. 그들은 영상 평활화 기법, 임계값 기법, 그리고 필터 기법 등을 적용하여 탐지 알고리즘을 개발했다. 이 알고리즘을 75장의 영상에 적용하여 실험해 본 결과 89.3%의 정확도를 얻었다. 끝으로 Li et al. (2019)은 딥러닝 알고리즘을 적용하여 콘크리트 손상을 탐지하고 여러 종류로 구분하는 기술을 개발했다. 의미론적 분할 기법을 적용하여 균열, 박락, 백화, 구멍을 화소 단위로 탐지하였다. 그들은 총 2,750장의 영상으로 심층 신경망을 학습하였고, 그 결과 84.53%의 평균 중첩 정확도를 갖는 알고리즘을 완성했다.
이처럼 콘크리트에서 발생하는 손상을 점검하기 위하여 균열과 박락을 탐지하는 연구가 활발하게 진행되고 있다. 본 논문에서는 이 중에서도 관리의 시급성이 높은 박락을 탐지하는 연구에 주안점을 두고 두 가지 기법을 적용하여 인식 성능을 향상시킬 수 있는 방법을 제안했다. 첫째는 향상된 손실 함수를 적용했다. 딥러닝 알고리즘은 손실 함수를 최소화하도록 심층신경망의 가중치를 업데이트하는 방식으로 개발된다. 따라서 손실 함수의 종류와 형태에 따라 심층 신경망의 가중치가 달라져 인식 성능에 차이가 발생한다. 이러한 점을 고려하여 손실 함수를 통해 인식 성능을 향상시키는 방법을 제안했다. 둘째는 영상 데이터 증강 기법을 적용하였다. 심층 신경망은 다양한 데이터를 통해 학습이 가능하도록 인식 성능이 향상된다. 이러한 점을 감안하여 동일한 영상을 두고 여러 기법을 통해 다양한 데이터처럼 인식되도록 했다. 이를 통해 콘크리트에서 발생하는 박락을 탐지하는 성능을 향상시켰다. 결과적으로 본 논문에서는 두 가지의 기법을 적용하여 인식 성능을 향상시키는 알고리즘을 제안했다.
우선적으로 본 논문은 콘크리트의 박락을 포함하고 있는 콘크리트 영상 데이터의 구성에 대하여 설명한다. 다음으로 본 논문에서 사용한 손실함수와 데이터 증강 기법에 관하여 기술한다. 마지막으로 본 논문에서 제안한 방식과 기존 방식의 차별점을 비교하고, 그 성능에 관해 분석한 결과를 서술한다.
2. 학습용 콘크리트 손상 영상
2.1 콘크리트 박락 영상의 확보
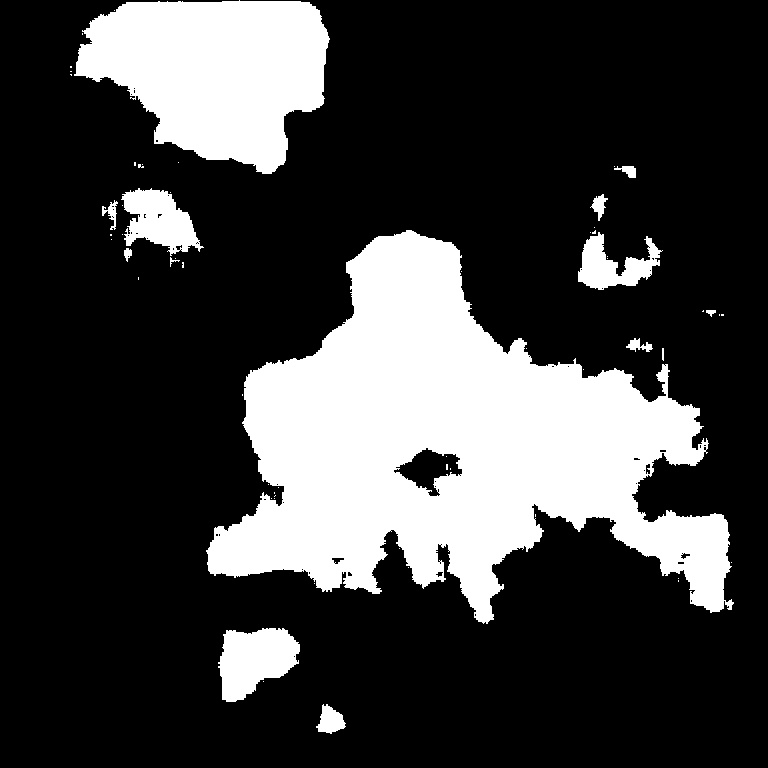
본 논문에서 사용한 박락 영상은 Fig. 1과 같다. 이처럼 콘크리트의 손상은 다양한 지점에서 발생한다. Fig. 1(a)와 Fig. 1(b)처럼 박락은 교량을 받치고 있는 교각의 기둥에서 발생한다. 교각의 기둥은 상부의 하중을 지지하고 있는 구조물로 손상이 발생했을 때 원래의 설계 지지력을 잃게 되어 안전사고를 유발할 수 있는 원인이 된다. 더욱이 Fig. 1(c)와 Fig. 1(d)처럼 콘크리트 구조물의 표면에서도 박락은 발생한다. 콘크리트 구조물 또한 상부 하중을 견디도록 설계되어 있다. 하지만 이 같은 손상은 내부적으로 붕괴사고의 잠재적 위험 요소가 되며, 외부적으로 도시 미관을 해치는 요인이 된다. 따라서 본 논문에서는 이러한 종류의 손상을 영상으로 탐지하기 위해 Yang et al. (2017)이 제공한 데이터를 활용했다.

2.2 학습을 위한 데이터 구성
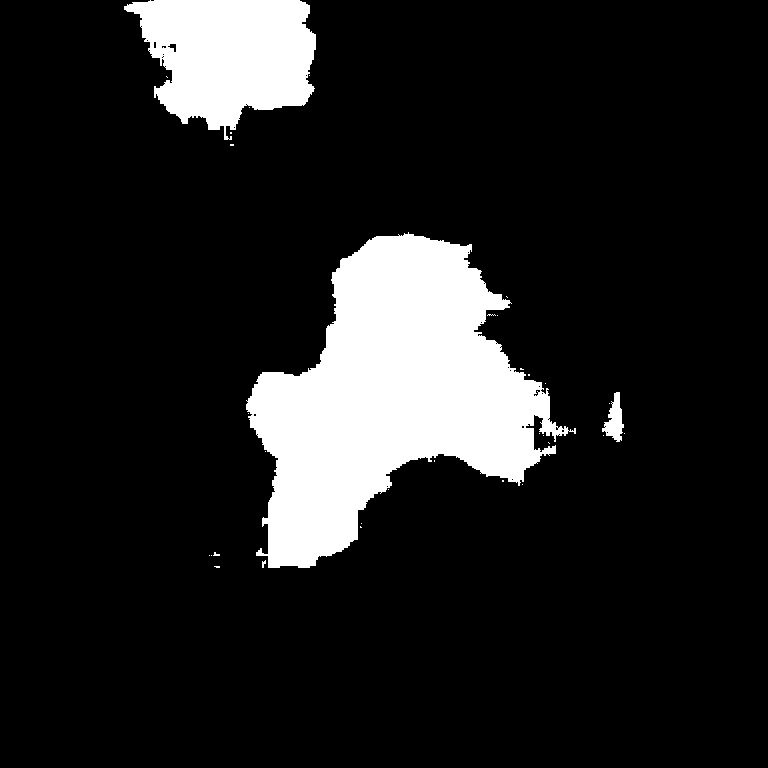
심층 신경망을 학습하기 위하여 Fig. 2와 같이 라벨 영상을 사용했다. 이 라벨 영상은 Fig. 1의 영상에서의 박락 영역을 표시한 것이다. 본 논문에서는 의미론적 분할 방식을 이용하여 박락을 추출하기 때문에 이진 영상을 사용하였다. 따라서 검은색 영역은 배경이고 흰색 영역은 박락 영역이다. 학습을 위하여 사용한 입력 영상의 크기는 768 × 768의 크기를 갖고 라벨 영상의 크기도 이와 동일하다. 전체의 영상 수는 298장이고 이 중에서 253장은 학습을 위해 사용했고 45장은 테스트를 위해 사용했다. 이 같은 라벨 영상을 통해 박락 영역을 화소 단위로 추출할 수 있는 알고리즘의 개발이 가능함을 확인했다.

3. 박락 탐지를 위한 심층 신경망 알고리즘
3.1 심층 신경망의 구조
박락을 탐지하기 위해 사용한 심층 신경망의 구조는 Shim et al. (2020)이 제안한 모델을 사용하였다. 이 모델은 계층적 구조를 갖고 있으므로 기존의 자기부호화 구조보다 인식 성능이 상대적으로 더 우수하다. 계층적 구조는 콘크리트 손상 영상으로부터 multi-scale feature를 추출한다. 이를 통해서 손상 영역의 크기와 무관하게 보다 정확한 탐지가 가능하다. 또한 각각의 계층으로부터 얻은 여러 개의 탐지 결과로부터 평균을 구하므로 영상 잡음에 대해 강인한 특성을 가지고 있다. 끝으로 알고리즘의 계산량 또한 다른 알고리즘과 비교했을 때 작으므로 메모리 사용 용량 또한 작다는 장점이 있다. 이러한 점들을 고려하여 본 논문에서는 박락을 탐지하기 위한 계층적 구조의 심층 신경망을 사용했다.
3.2 향상된 손실 함수
심층 신경망의 가중치를 업데이트하기 위해서는 손실 함수가 필요하다. 손실 함수는 심층 신경망의 출력 영상과 라벨 영상의 차이를 나타내는 지표다. 따라서 출력 영상과 라벨 영상이 동일하면 손실 함수의 값은 0이고 그렇지 않으면 값이 커지게 된다. 이 지표를 바탕으로 손실 함수의 값이 0에 가까워지도록 심층 신경망의 가중치를 업데이트하는 과정이 학습이다. 결과적으로 손실 함수가 나타내는 값에 따라 심층 신경망은 다른 출력을 생성한다.
본 논문에서는 이런 점을 고려하여 박락 탐지의 성능을 향상시키기 위해 기존의 cross-entropy (CE) 함수를 사용하는 대신 focal loss (FL) 함수(Lin et al., 2017)를 사용하였다. 이 손실 함수는 식 (1)과 같이 정의된다.
p는 prediction의 결과로 classification의 확률 값이다. 이는 해당 화소가 박락 영역이 될 확률을 의미한다. y는 ground truth의 값으로 0 또는 1의 값으로 이루어졌다. 그리고 이에 focusing parameter인 gamma가 지수로 적용되어 있다. 이 gamma 값에 따라 성능이 달라지는데, Lin et al. (2017)의 실험에 따르면 gamma를 2로 하였을 때 가장 높은 성능을 보이는 것으로 나타났다. 이 근거로 본 논문에서도 동일한 설정 값을 사용하였다.
3.3 영상 데이터 증강
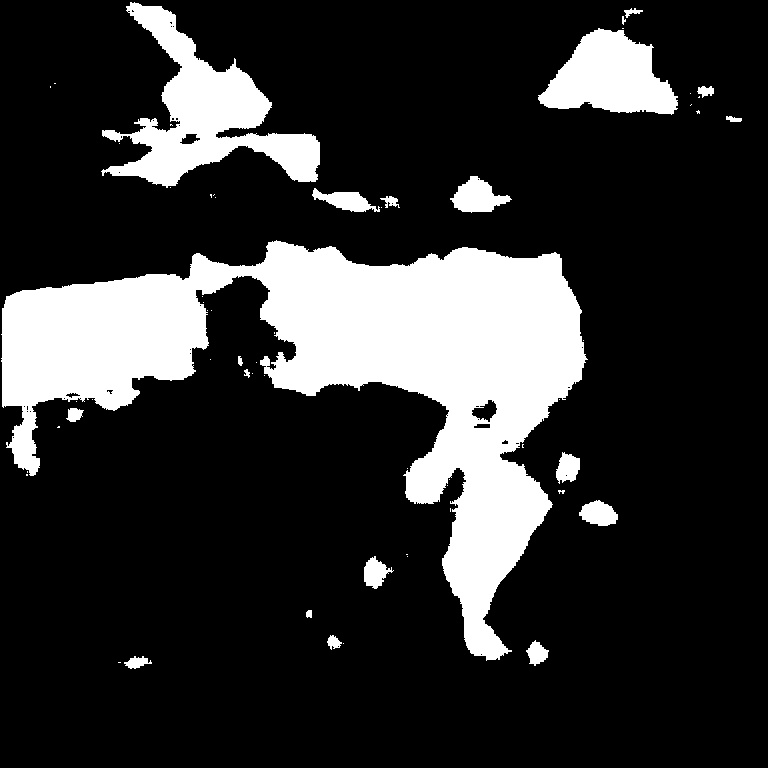
다양한 영상 데이터를 통한 심층 신경망 학습을 위해 본 논문에서는 두 가지 방법을 적용하였다. 첫째는 대칭 기법을 적용한 것이고, 두 번째는 크기 조절 기법을 적용했다. 대칭 기법은 50%의 확률로 영상의 좌우 대칭 변환을 수행한다. 이를 통하여 영상 내에서 손상 영상이 존재할 수 있는 경우의 수를 늘리는 역할을 수행한다. 크기 조절 기법은 영상의 크기를 조절하는 것으로 0.5배에서 1.5배까지 임의의 배수로 영상의 크기를 조절한다. 이와 함께 손상 영역이 확대될 수도 있고 축소될 수도 있다. 이 기법의 목적은 손상 영역의 크기가 실제 촬영하는 거리에 따라 달라지기 때문에 이와 같은 현상을 학습에 반영하기 위함이다.
이 두 가지의 기법을 동시적으로 반영한 결과는 Fig. 3과 같다. Fig. 3에서 첫 번째 행은 데이터 증강 기법을 적용한 박락 영상이고 두 번째 행은 그에 해당하는 라벨 영상이다. Fig. 3(a)는 작은 크기로 축소되고 좌우 대칭 변환을 시켜 영상데이터를 확장시킨 경우이고, Fig. 3(b)는 작은 크기로 축소시켰지만, 대칭 변환을 시키지 않았다. 더욱이 Fig. 3(c)는 영상을 확대시키고 좌우 대칭 변환을 시켰고, Fig. 3(d)는 영상을 확대만 시켰다. 이 같은 기법은 학습이 반복될 때마다 계속해서 다르게 적용되어 학습의 다양성을 확보하게 해준다.

4. 실험 결과 및 분석
4.1 평가 기법 및 실험 환경
콘크리트 박락을 탐지하는 심층 신경망의 인식 성능을 비교하기 위하여 본 논문에서는 평균 중첩 정확도 지표(mean intersection over union, m-IoU)를 사용했다. 이 지표는 탐지된 균열의 영역과 라벨 영상에 표시된 균열의 영역에 대한 중첩의 정도를 나타낸다. 예를 들어 탐지된 균열 영역이 라벨 영상의 균열 영역과 동일한 경우 정확도는 100%가 된다. 하지만 탐지된 균열 영역이 라벨 영상의 균열 영역과 다를수록 중첩의 정도가 낮아져 정확도는 떨어진다. 이 평균 중첩 정확도는 식 (2)와 같이 정의된다.
식 (2)에서 있는 는 class 에 속해 있을 것으로 예측된 class 의 모든 화소 수를 나타낸다. 아울러 는 class의 개수를 가리키고, 는 class 에 속해 있는 모든 화소 수를 지칭한다.
본 논문에서 실험을 위해 사용한 하드웨어의 사양은 Intel Xeon 6226R 2.9 GHz, 320 GB의 메모리, 그리고 NVIDIA Quadro 8000이다. 또한 소프트웨어는 Ubuntu 18.04의 운영체제와 Pytorch를 딥러닝 프레임워크로 사용하였다. 학습을 위해 사용한 파라미터로 batch의 수는 6이고, epoch의 수는 300이다. 이는 모든 실험에서 동일하게 적용하였다.
4.2 인식 성능 비교
탐지 성능의 비교를 위하여 4개의 경우를 고려하여 실험을 수행하였고, 그 결과는 Table 1과 같다. Case-0은 손실 함수를 CE로 사용하고 데이터 증강을 적용하지 않은 경우다. 이 방법을 통해 얻은 인식 성능 결과를 대조군으로 설정하였다. 다음으로 Case-1은 손실 함수로 FL만을 적용하여 학습한 경우다. 셋째로 Case-2는 대조군과 비교했을 때, 데이터 증강 기법만을 적용한 결과다. 끝으로 Case-3은 FL과 데이터 증강을 모두 적용한 결과를 나타낸다.
Table 1.
Performance evaluation results
| Methodology | Loss function | Data augmentation | m-IoU |
| Case-0 | CE | - | 78.09 |
| Case-1 | FL | - | 78.32 |
| Case-2 | CE | ○ | 80.12 |
| Case-3 | FL | ○ | 80.19 |
우선 Case-0을 통해 얻은 박락 인식 결과는 78.09%의 m-IoU다. 다음으로 Case-1과 같이 FL을 손실 함수로 사용했을 때는 탐지 성능은 78.32%의 m-IoU로 0.23%만큼 향상되었다. 또한 Case-2와 같이 데이터 증강 기법을 적용했을 때, 박락 탐지 성능은 80.12%의 m-IoU로 나타났다. 이는 대조군과 비교했을 때, 2.03% 만큼 향상되었음을 의미한다. 끝으로 Case-3과 같이 FL의 손실 함수와 데이터 증강 기법을 동시에 적용했을 때, 탐지 성능은 80.19%의 m-IoU로 드러났다. 최종적으로 2.10%의 성능 향상을 얻었다.
다음으로 본 논문에서 적용한 두 가지의 기법이 인식 성능 향상에 미치는 영향을 살펴보았다. 먼저 FL의 손실 함수를 적용한 효과는 Case-0과 Case-1을 비교했을 때와 Case-2와 Case-3을 비교했을 때 관찰된다. 각각의 m-IoU 변화량은 0.23%와 0.07%로 성능이 향상되는 것으로 나타났다. 이와 마찬가지로 데이터 증강을 적용한 효과는 Case-0과 Case-2를 비교했을 때와 Case-1과 Case-3을 비교했을 때 나타난다. 각각의 m-IoU 변화량은 2.03%와 1.87%로 탐지 성능을 높였다. 본 실험의 내용을 종합해보면 FL 손실 함수를 적용한 효과보다 데이터 증강을 통한 효과가 더 큰 것으로 나타났다.
본 논문에서 수행한 실험을 통해 FL 손실 함수를 사용하였을 때의 성능 향상은 데이터 증강 기법에 의한 것과 비교했을 때에 비하여 다소 작은 것으로 나타났다. 이는 본 연구에서 실험을 위해 사용한 영상의 수가 300여 장에 한정되어 있으므로 FL 손실 함수가 성능 향상에 미치는 영향이 크지 않은 것으로 보인다. 하지만 Lin et al. (2017)이 MS COCO DB를 사용하여 많은 수의 데이터를 통해 성능이 향상되는 결론을 얻었다. 이를 통해 손실 함수 기법이 인식 성능을 향상시킬 수 있는 하나의 방법임을 알 수 있다. 이와 마찬가지로 본 연구에서도 향후 다수의 박락 영상을 활용하여 학습할 경우 큰 인식 성능 향상을 기대할 수 있을 것이다.
4.3 인식 결과 비교
본 논문에서 제안한 박락 탐지 성능의 결과 영상은 Table 2와 같다. 첫 번째와 두 번째 행은 각각 콘크리트 박락 영상과 ground truth인 라벨 영상이다. 또한 세 번째와 네 번째 행은 각각 Case-0과 Case-3의 방법을 적용하여 박락을 탐지한 결과 영상들이다. 이 결과 영상들을 살펴볼 때, 라벨 영상과 중첩도가 높을수록 정확히 탐지한 것이고 반대로 중첩도가 낮을수록 오인식이 많은 것이다. 이러한 점을 고려하여 첫 번째 열을 살펴보면 영상 내 박락 영역의 왼쪽에는 콘크리트 표면 얼룩이 존재한다. 이 영역은 콘크리트 박락이 아님에도 Case-0의 방식은 이것을 박락 영역으로 인식하지만 Case-3의 방식은 정상 영역으로 올바르게 인식한다. 또한 나머지 영상에 대해서도 탐지 결과를 비교해 보면 Case-0의 방법은 박락 영역 외에도 다른 지점을 탐지하여 라벨 영상과의 중첩도가 떨어진다. 특히 정상적인 콘크리트 표면을 손상 영역으로 인식하는 현상이 나타나 부정확한 탐지 결과를 도출하는 것으로 관찰되었다. 이에 반해 Case-3의 방법은 라벨 영상과의 중첩도가 더 높아 정확한 탐지를 수행하는 것을 확인할 수 있었다.













5. 결 론
본 논문에서는 콘크리트 구조물의 유지관리를 위한 점검 기술의 일환으로 박락 탐지 알고리즘을 개발하였다. 콘크리트에서 발생할 수 있는 여러 손상 가운데 안전사고의 위험도가 높은 박락은 보수의 시급성 매우 높다. 따라서 이 같은 손상을 보수하기 위해서는 우선적으로 탐지할 수 있는 기술이 요구된다. 이를 위해 본 논문에서는 딥러닝을 이용한 영상처리 기술로 박락을 탐지하는 알고리즘을 개발했다. 아울러 본 논문에서는 인식 성능을 높이기 위해서 향상된 손실 함수와 데이터 증강 기법을 적용하였다. 그 결과 m-IoU 기준으로 2.10%의 성능을 향상시켰고, 최종적으로 80.19%의 탐지 정확도를 얻었다. 이 같은 성능 향상은 콘크리트 구조물의 손상 상태를 정확하고 객관적으로 진단함에 있어서 중요한 역할을 할 것이고, 최종적으로 터널 콘크리트 라이닝에서 발생하는 박락을 탐지하는데 활용될 것으로 기대한다.
향후 연구로 콘크리트 라이닝에 발생할 수 있는 균열, 백태, 누수, 박락과 같이 다양한 손상 형태를 탐지하고 구분하는 알고리즘 개발을 수행할 예정이다. 이를 위해서는 우선 백태와 누수 영상을 확보하고 그에 해당하는 라벨 영상을 만들고자 한다. 그리고 심층 신경망의 구조를 수정하여 각각의 손상 상태를 서로 다른 색상으로 표시되도록 할 계획이다. 끝으로 이와 같은 기술의 현장 테스트를 통해 완성도를 높이고 결과적으로 보다 정확한 시설물의 상태를 진단할 수 있도록 연구개발을 수행할 예정이다.
