

1. 서 론
2. 딥러닝 알고리즘의 이론적 배경
2.1 적용된 딥러닝 알고리즘의 이론적 특성 고찰
2.2 딥러닝 알고리즘의 운용
3. 딥러닝 기반 터널 영상유고 프로세스 설계
4. 딥러닝 기반 CCTV 영상 빅데이터의 학습
4.1 영상 빅데이터 구성 및 특성 분석
4.2 딥러닝 학습 환경 설정
4.3 딥러닝 학습 모델 설정 및 학습 결과 분석
4.3 해석결과 및 분석
5. 결 론
1. 서 론
터널은 차량 충돌사고나 화재 발생 시 폐쇄된 터널 내부의 특수한 환경으로 인해 대피할 공간이 여의치 않고, 주변 이동 차량들이 보행자 출연 및 역주행 등과 같은 돌발상황에 대해 적시에 인지하고 회피운전을 하기 어렵다. 또한, 폐쇄된 터널 내부에서는 사고나 돌발상황이 경미하다 하더라도, 대형 후속 2차 사고로 이어질 가능성이 매우 커서 사고나 돌발상황의 실시간 인지와 초동 대응이 어떠한 교통상황보다도 중요하다. 이에, 정부에서는 도로터널 방재시설 설치 및 관리지침(MOLIT, 2016b)을 통해 방재등급 3등급 이상의 터널에서는 200~400 m 간격으로 CCTV 설치를 의무화 하였으며, 영상유고감지 설비의 설치를 권고하고 있다. 기존 2009년 방재시설 설치 및 관리지침에서 연장등급 2등급 이상의 터널에 의무화 했었던 규정이 강화된 경우이며, 영상유고감지 설비의 설치시에는 CCTV 설치기준은 100 m간격으로 더욱 조밀하게 설치하는 것으로 규정되었다.
2014년 기준으로 도로터널은 총 1659개소(튜브수 기준)가 운영 중이며, 이중 CCTV를 의무적으로 설치해야 하는 방재등급 3등급 이상에 해당하는 터널은 약 909개소로 전체 도로터널의 54.8%에 해당한다(KTA, 2015). 이중 2014년도 기준으로 방재등급 2등급 이상이었던 터널은 약 20%에 해당되는 323개 터널로 약 580여개 터널이 CCTV가 설치되어 있지 않아 신규로 추가 설치해야 하는 대상 터널이다. 2016년 국토교통부(MOLIT, 2016a)에 의하면 전체 국도터널의 약 17%에 해당하는 터널들에 영상유고감지 설비가 설치되어 있고, 한국도로공사가 관할하고 있는 총 925개소 고속국도 터널들은 73%에 해당하는 678개소에 사고자동 감시 시스템이 설치되어 있는 것으로 파악된다. 한국터널지하공간학회(KTA, 2015)에서는 이러한 영상유고감지 설비가 설치되어 있는 터널들 중 선별된 8개의 터널들을 대상으로, 지침에서 요구하는 기능을 유지하고 있는지에 대해 현장점검을 실시한 바 있다. 결론적으로 국도터널의 영상유고감지 설비의 정상검지율은 발생된 이벤트 2213건에 대해 46%로 나타났고, 고속국도 터널에서는 정상검지율이 1.3%로 거의 검지가 되지 않는 것으로 보고 된 바 있다(Kim, 2016; National Committee for Land and Transport, 2016).
현재 운용중인 국내 도로터널현장에 설치되어 있는 영상유고감지 설비의 구성은 일반적으로 동영상 수집 카메라 부문, 수집된 동영상의 분석을 통한 유고상황 판단 분석 부분(영상처리부와 유고감지분석서버) 그리고 분석된 정보를 기반으로 운영자에게 그 결과를 제공하는 정보운영 및 제공부문(운영소프트웨어)으로 구성된다. 대부분 해외제품이며, 터널환경에 특화된 시스템이 아닌 일반 범용 영상유고감지 설비로 개발되어, 매우 열악한 조건의 터널 내에서는 오감지율이 매우 높은 것으로 파악되었다. 이는 개방된 일반도로에 비해 낮은 조도, 먼지 등으로 인해 선명한 영상 확보의 곤란, 낮은 CCTV 설치위치로 인한 좁은 가시범위와 가시권내에서 심한 이동객체간의 겹쳐 보임 현상이 상용 알고리즘 기반의 영상유고감지 설비의 오탐율을 높게 하는 원인으로 보이며, 그럼에도 점차 강화되고 있는 터널 방재시설 설치 및 관리 기준에 적절히 부응하기 위해서는 매우 열악한 터널 내 환경조건 및 제한된 CCTV 설치조건에서도 대응력이 좋은 새로운 개념의 영상유고감지 시스템의 개발이 시급한 실정이다(Roh et al., 2016).
이렇게, 터널 발생 가능한 다양한 사고에 대한 방재시설 설치 및 관리 기준이 강화됨에 따라 다방면의 현장 상황 자동 감지에 대한 중요성이 높아지고 있다. 또한, 고화질의 CCTV 제품의 대중화와 방대한 영상 빅데이터와 연계된 실시간 인공지능 영상감시 시장은 수년 이내에 37% 이상까지 급속도로 성장할 것으로 전망된 바 있다(Choi and Kwon, 2010). 하지만, 영상 자동 감지는 방대한 영상자료에서 인식하고자 하는 객체를 뽑아내고 그 객체의 현상 정보를 추론하는 것까지를 의미하며, 영상 빅데이터 내 개별 영상들의 조건이 거의 무한대에 가까워 기존 수학 알고리즘 기반의 영상처리 방식으로는 한계가 있는 것이 현실이다(Park et al., 2015). 이와 같이, 영상 빅데이터를 대상으로 하고 있는 영상처리 기술 분야의 한계와 현재 매우 낮은 정상 감지율로 애로를 겪고 있는 터널 영상유고감지 분야와 상황이 유사하다 하겠다. 이에 대한 기술적 돌파구로 인공지능 딥러닝 기반의 영상 빅데이터 처리 방식이 활발히 고찰되고 있으며(Karpathy et al., 2014), 다양한 영상처리 수요와의 기술적 접목이 시도하고 있다. 이러한 영상처리분야의 기술 기조로 볼 때, 터널 영상유고 분야에서도 인공지능 딥러닝 기법을 도입한 시스템의 개발은 적시적이라 할 수 있다. 이러한 배경에서, 본 연구에서는 기 발표된 머신러닝 기반의 터널 영상유고를 위한 사전검토 연구(Shin et al., 2017)에 이어 영상처리를 위한 최신 딥러닝 알고리즘인 Faster Regional Convolution Neural Network (Faster R-CNN)을 도입하여 코드화였고, 터널 현장에서 직접 얻어진 터널 유고상황이 포함된 CCTV 영상들을 확보하여 터널 영상유고감지 시스템을 구축하였다.
본 논문에서는 도입된 딥러닝 알고리즘을 우선적으로 소개하고, 터널 내 이동차량의 CCTV 영상들을 적절하게 학습하기 위한 이론적 연구와 학습에 반영된 학습환경에 대해 고찰하였다. 이러한 딥러닝 학습 및 추론 코드를 활용하여 터널 현장의 CCTV에서부터 터널관리동의 서버 및 현장관리자에게 유고상황을 알려주는 경보단계까지 통합된 터널 영상유고 감지 및 운영 프로세스가 설계되었다. 본 시스템에서는 초기 터널 영상 빅데이터가 수동으로 구축되어 학습이 진행 된 후에는, 시스템 운용과 딥러닝 추론에 의해 CCTV영상 빅데이터가 자동으로 누적되고 성장함에 따라 영상유고감지 성능이 스스로 향상된다. 이에 대한 검토를 위하여 터널 유고 영상 학습 및 추론 시나리오를 설정하였으며, 기 확보된 유고 영상 빅데이터의 일부를 발췌하여 구축 시스템의 운영 절차와 그 타당성 검토에 활용하였다. 총 4개의 영상유고 항목(보행자, 화재, 정지/충돌차량, 역주행 차량) 중 하나인 ‘보행자 출몰’ 상황 인식에 초점을 맞추어 검토하였다. 사실상, 시스템 상에서는 다른 주요 유고상황인 ‘화재’도 하나의 객체로 인식되어 보행자와 동일한 방식으로 감지되어 처리되므로 본 논문에서는 생략하였다. 정지 및 역주행 차량은 딥러닝 알고리즘으로 인지된 차량 및 차량정보(크기 및 영상 내 위치)를 활용하여 시간 이력별 차량의 이동 벡터 계산을 통해 쉽게 판별된다. 따라서, 본 논문에서는 이동차량 벡터 계산의 기초자료인 차량 객체의 인식률 검토에 초점을 맞추어 그 성능을 논하였다.
2. 딥러닝 알고리즘의 이론적 배경
2.1 적용된 딥러닝 알고리즘의 이론적 특성 고찰
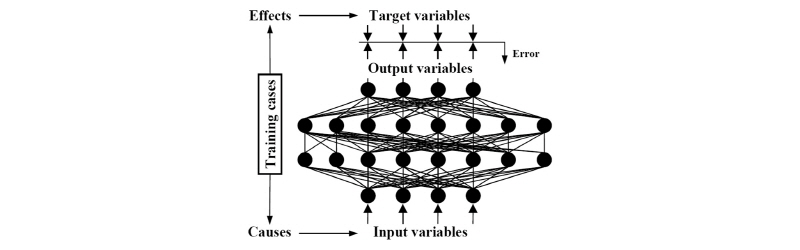
딥러닝의 전단계인 기계학습분야는 “기계가 일일이 코드로 명시하지 않은 동작을 데이터로부터 학습하여 실행할 수 있도록 하는 알고리즘을 개발하는 연구분야”를 말한다(Samuel, 1959). 즉, 일반적인 알고리즘이 주어진 규칙에 의하여 동작을 수행하는 것과 달리 기계학습으로 개발된 알고리즘은 주어진 규칙없이 동작을 수행한다. 딥러닝은 기계학습이 가진 단점을 개선하여 빅데이터의 활용을 최대한 끌어올릴 수 있도록 발전된 분야이다. 기존의 기계학습에서는 은닉층의 수가 여러층으로 깊어짐에 따라 과학습(overfitting)에 빠질 가능성이 높아지며, 학습과 추론하고자 하는 대상 문제에 대해 영향(원인, causes)과 결과(effect) 인자들이 사전에 명확히 정의되어야 하고, 정의된 항목에 따라 갖추어진 많은 수의 학습자료들이 준비되어야 하는 어려움이 있었다. 하지만 2006년 토론토대학의 Hinton교수에 의해 딥러닝으로 명명한 알고리즘이 제안이 되면서 기존의 기계학습의 한계를 뛰어 넘는 계기가 되었다(Hinton et al., 2006). 층구조가 깊어짐에 따른 과학습의 가능성은, 깊은 구조의 방대한 연결선들(connection)에 LeRu라는 새로운 활성화 함수의 적용과 Dropout이라고 하는 개념을 도입하여 각 학습단계마다 통계적으로 선택된 연결선들 만을 학습에 반영하고, 매 학습단계마다 학습에 반영되는 연결선을 통계적으로 달리 선택하여 반영하는 개념으로 극복할 수 있었다(Srivastava et al., 2014). 사전에 정의되었어야 하는 추론항목에 대한 영향인자들이 자동으로 기초자료(이미지)로부터 특성화지도(feature map)이라는 형태로 자동 추출되는 방식인 컨벌루션 방법이 제안되면서 극복되었다(Yann et al., 1990). 이때, 매우 방대한 구조의 딥러닝 개념의 활성화는 기존 CPU기반 병렬처리 계산보다 몇 배 빠른 GPU라는 하드웨어의 발전에도 기반을 둔다(Yoshua et al., 2013).
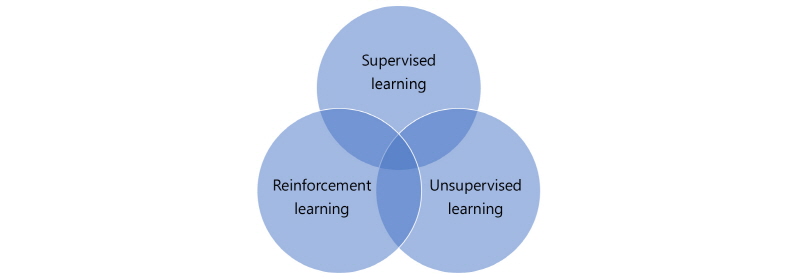
딥러닝은 기계학습의 한 분야이며, Fig. 1과 같이 학습의 종류에 따라 입력항목이 정의된 입력값과 추론항목에 대한 출력값을 이용하여 학습자료 모델이 제시되어 학습하는 지도학습(supervised learning), 입력값만을 이용하여 군집간 특성을 찾아내 그룹핑을 하는 비지도학습(unsupervised learning), 어떠한 상태에 대하여 행동을 취하면서 보상을 받는 쪽으로 학습하는 강화학습(reinforcement learning)이 있으며(Yann et al., 2015), 본 논문에서는 지도학습에 속한 Faster R-CNN을 사용하였다.
Faster R-CNN은 CNN (Convolutional Neural Network)의 발전형인 R-CNN (Regional CNN)의 종류 중 하나이며, CNN은 합성곱(convolution), 통합(pooling)을 이용한 전처리를 사용하는 지도학습 알고리즘이다(Ren et al., 2015). 이를 이용하여 2차원 구조의 입력 데이터에 활용 가능하며, 영상 구별(image classification)과 음성 분야에서 활발히 활용되고 있다. R-CNN은 CNN에서 파생된 방법으로, 영상 내에 존재하는 객체(object)의 정확한 위치를 직사각형 박스로 찾기 위해서 고안된 방법이다(Girshick et al., 2014). 여기서, 이미지 내에서 객체 박스(object box)를 찾는 분야를 객체 인식(object detection)이라고 한다. 딥러닝 학습에 적용되는 데이터셋은 객체들이 박스형태로 명시된 정지영상 이미지와 명시된 객체와 대응되는 객체의 종류나 이벤트 정보로 구성되는 출력값으로 구성된다. 본 연구에서는 출력값으로 정지영상 내 객체의 종류(차량 또는 보행자)를 사용한다.
우선 본 연구에서 적용된 알고리즘인 Faster R-CNN의 근간이 되는 R-CNN은 다음 Fig. 2와 같이 정지영상에 대하여 먼저 객체에 대한 직사각형의 박스(bounding box, BB)를 찾는 Region Proposal Network (RPN)을 이용해 찾은 다음, 각각의 BB에 존재하는 이미지에 대하여 CNN을 수행해서 BB가 어떤 객체인지 추론한다.

Fast R-CNN은 R-CNN의 단점인 계산시간이 크게 소요된다는 단점을 해결하기 위해 고안된 알고리즘이다(Girshick, 2015). Fig. 3에서와 같이, 먼저 정지영상에 대해서 CNN을 수행하여 작은 크기의 특성화지도(feature map)를 얻은 다음, 이 특성화 지도에 대하여 RPN으로 BB를 찾는다. 그리고 BB에 대한 정보와 특성화 지도의 정보를 받은 관심영역(Region of Interest, RoI)내의 Pooling Layer에서 각각의 BB에 속한 특성화 지도 부분들을 한번에 전통적인 인공신경망(fully connected neural networks)으로 계산하여 각각 특성화 지도 부분의 객체 종류와 위치정보를 추론해 낸다. R-CNN과 비교하면 학습시간이 25배 정도 빠르다.
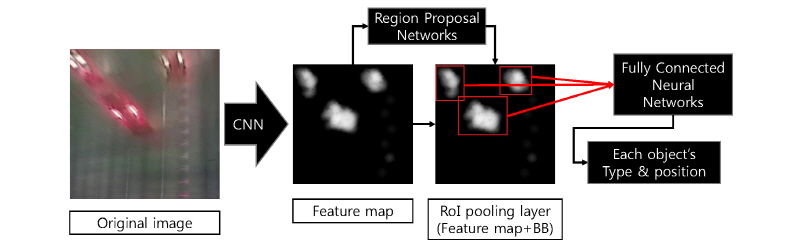
Faster R-CNN은 Fast R-CNN과 전체적인 절차는 동일하지만, RPN을 논리에 의한 알고리즘을 이용하는 것이 아닌 CNN에도 추출된 특성화 지도상에서 RPN을 이용해 객체를 인식 한 후, 전통 인공신경망과 연계되어 객체의 종류와 위치정보를 추론해 낸다(Fig. 4). 기존 R-CNN과 비교하면 250배 빨라서 실시간 객체 인식이 가능하며, 이러한 장점으로 인해 현재 객체 인식분야에서 가장 많이 사용되고 있는 알고리즘이다.
2.2 딥러닝 알고리즘의 운용
Faster R-CNN의 운용은 크게, 학습하여 추론 모델을 얻는 학습단계, 학습하여 얻은 추론 모델을 평가하는 검증 단계로 나눌 수 있다. 딥러닝 학습은 Fig. 4와 같이 크게 정연산 과정, 딥러닝 네트워크의 그래디언트(gradient) 계산 과정 그리고 딥러닝 네트워크내의 모든 연결선의 가중치(connection weight) 갱신과정으로 진행된다. 처음 정연산 과정에서는 현 학습수준의 딥러닝 네트워크의 연산으로 각 객체의 종류와 위치정보를 얻고, 이를 바탕으로 원본 정지영상 내 객체의 종류와 위치정보와 비교하여, Fig. 4의 4개의 오차값(loss)들을 계산한다. 그 다음 그래디언트값을 이 4개의 오차값을 이용하여 기 설정된 최적화 알고리즘을 이용하여 계산하며, 계산된 그래디언트값을 이용 CNN, RPN과 전통 인공신경망(fully connected NN) 들의 가중치들을 갱신한다. 이 전체 과정이 1회의 학습회차이다. 이를 반복해 나가면서 객체가 정지영상 내에 존재하는지, 존재한다면 어디에 존재하는지, 또 어떤 종류의 객체인지 추론할 수 있게 된다.
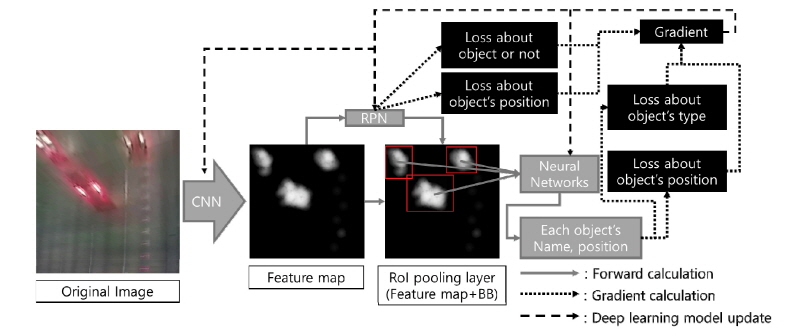
일정 횟수의 학습 반복횟수만큼 학습을 진행하여 추론모델을 얻었다면, 추론모델이 학습이 잘 되었는지 평가하기 위하여 검증해야 한다. 학습의 검증은 Fig. 4에서 정연산 과정만을 거치며, 추론모델의 연산을 통해 각 객체의 이름과 좌표를 얻는다. 그 다음, 원본 정지영상의 객체 종류의 위치정보를 비교하여, 객체인식 알고리즘의 성능을 나타내는 지표인 평균 추론정확도(Average Precision, AP)을 계산할 수 있다(Mu, 2004).
상기에서 언급하였던 AP값은 영상 객체인식 알고리즘의 학습 성과 및 추론 성능을 표현하기 위해 설정된 지표이다. 객체인식에서 오차율(loss)을 이용하여 평가하지 않는 이유는, 영상의 객체인식 성능을 평가하기 위해서 다음의 두 가지 평가 척도인 recall값과 precision값을 함께 고려해야 하기 때문이다.
Recall값은 검출율이라고 부르며, 대상 객체들을 얼마나 잘 잡아내고 있는지 평가하는 지표이다. 즉, 정지영상 내에서 대상 객체들이 5개가 존재할 때, 알고리즘이 5개 모두 잡아낼 수 있으면 Recall은 100%가 된다. 하지만 대상 정지영상에서 객체들이 100개가 있다고 판단해도 Recall은 100%인데, 정확한 것과 상관없이 존재하는 5개의 객체를 모두 검출하였기 때문이다.
Precision은 정확도라고 부르며, 알고리즘이 객체라고 인식한 결과들 중, 실제로 정확히 객체의 종류를 추론하였는지 평가하는 지표이다. 위에서 언급한 바와 같이, 대상 객체들이 5개가 존재할 때, 알고리즘이 대상 물체가 10개가 존재한다고 판단한다면 Precision은 50%이다. 10개 중 나머지 5개는 실제로 대상 물체가 아니고, 배경 또는 다른 물체이기 때문이다. 반면, 이미지에서 1개의 물체가 존재하고, 대상 물체가 1개라고 판단한다면 Precision은 100%이 된다.
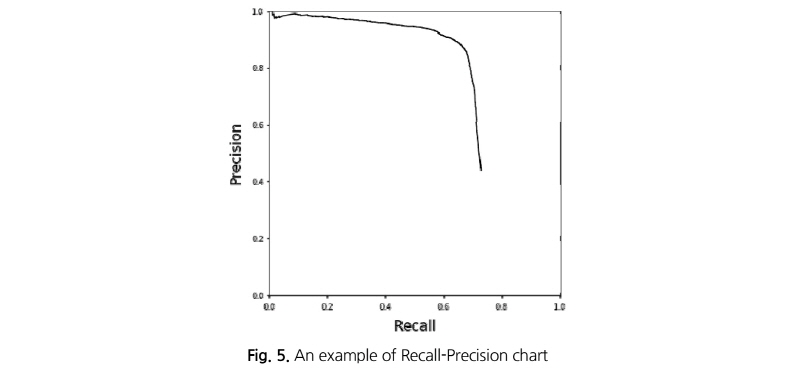
객체인식 알고리즘에서 두 지표를 고려해야 하는 이유는 Recall만으로 정확한지 판단할 수 없고, Precision으로 얼마나 검출되었는지 판단할 수 없기 때문이다. 즉, 두 지표는 서로 상호 보완적인 지표이다. 따라서, AP값은 Recall-Precision 그래프를 나타내고 그 면적을 계산해 산정한다. 먼저 하나의 데이터셋에 대해서 객체인식 알고리즘이 연산하여 나온 N개의 객체정보(종류와 위치정보)가 있을 때, 처음 1개의 객체에 대해서 Recall과 Precision을 계산한다. 그 다음은 2개의 객체에 대해서 계산을 하면서 점점 계산할 객체의 수를 늘려나간다. 마지막으로 N개에 대한 Recall-Precision을 구함으로써 다음과 같은 Recall-Precision의 집합을 얻을 수 있으며, 이를 도시하면 Fig. 5와 같다.
AP는 Precision의 평균값이며, Recall-Precision 그래프에서 곡선의 면적인 적분값으로 나타낼 수 있다. 식으로 나타내면 다음의 식 (2)와 같다.
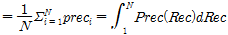
여기서, Rec는 recall값, Prec는 precision값, 그리고 N은 Recall-Precision 값의 포인트 수를 나타낸다. Recall- Precision 그래프는 AP와 비교해 알고리즘의 학습 수준 및 추론 정확도를 좀 더 자세히 알 수 있지만, 매 학습반복 횟수마다 학습 수준을 평가하기 위해 그래프를 생산하여 평가하는 것은 용이치 않다. 반면 그 그래프를 통해 계산된 AP값은 0~1의 범위를 가진 값으로 표현할 수 있어서 객체인식 딥러닝 알고리즘의 학습 수준과 추론 정확도를 나타내는 표준 지표로 사용하기에 매우 용이한 면이 있다.
3. 딥러닝 기반 터널 영상유고 프로세스 설계
본 연구에서는 상기에서 언급된 딥러닝 알고리즘과 터널 CCTV 영상 및 유고정보로 구성된 영상 빅데이터와 연계하여 딥러닝 기반 터널 영상유고 학습 및 추론 서버를 개발하고, Fig. 6과 같이 터널 현장내의 CCTV 촬영장치에서부터 터널관리동의 CCTV 모니터링 시스템까지 연결된 통합 터널 영상유고감지 시스템을 설계하고 구축하였다.
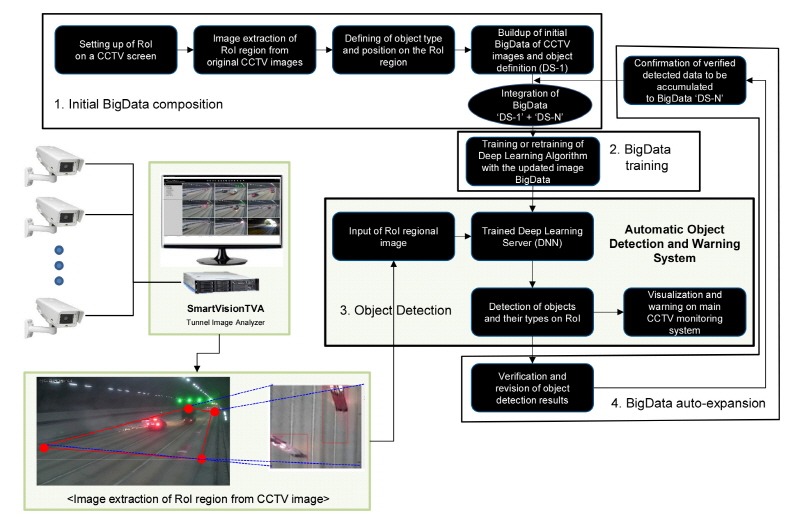
통합시스템의 첫번째 단계는 딥러닝 학습을 위한 터널 초기 CCTV영상 빅데이터 구성 단계이다(Fig. 6). 본 단계에서는 터널 내 설치된 CCTV영상에서 인지코자 하는 관심영역(ROI)의 영상을 정지영상(30 frames/초) 형태로 추출한다. 추출된 각 정지영상 내에 포함되어 있는 객체들의 위치 및 크기 정보들을 좌표 형태로 뽑아내고, 각 객체들의 유형(일반이동차량, 사람, 화재발생, 작업차량, 낙하물 등)을 코드화하여 함께 텍스트형태로 파일에 저장한다. 따라서, 각 ROI내 정지영상과 각 영상 내 포함되어 있는 모든 객체들의 정보(위치, 크기 및 유형 정보)군이 쌍을 이루어, 방대한 양의 “영상-객체정보” 빅데이터를 구성한다. 본 초기 단계의 빅데이터 구성은 기존 수학기반의 이미지프로세싱 기법을 활용하여 각 영상정보의 특성을 감안하여 요구되는 객체 정보를 뽑아내고, 뽑아진 객체 정보는 해당 영상과 함께 유간으로 확인하며 수동으로 검증하고 자료를 교정하며 양질의 빅데이터를 완성한다. 본 단계의 빅데이터셋은 상기 그림에서 DS-1으로 표현하였다.
다음의 2단계는 빅데이터(DS-1)의 딥러닝 학습 단계이다. 상기 과정을 통해 작성된 초기 빅데이터(DS-1)을 대상으로 본 연구에서 도입한 Faster R-CNN을 이용하여 터널 내 CCTV영상 내 객체 위치 및 유형을 학습시킨다. 이때, 영상의 학습이라 함은, Fig. 7과 같은 기본 인공신경망의 입력정보(input variable)와 모든 유닛 간 연결선(connection)에 배정되어 있는 가중치(w)들과의 연산을 통해 ‘계산되는 객체 위치 정보와 객체 유형’과 ‘실제 영상 내에 존재하는 객체 위치 및 객체 유형’과의 오차(Error)가 최소가 되는 가중치값(w)들의 조합을 찾아내는 것을 의미한다. 이때, 터널 내부의 열악한 환경(먼지, 낮은 조도, 낮은 해상도)이 반영된 터널 내 설치되어 있는 CCTV 영상들이 사전 필터링 없이 있는 그대로 딥러닝 학습에 반영된다.
다음의 통합시스템 3단계는 딥러닝 학습결과(2단계)에 기초한 터널 CCTV 영상 내 실시간 객체 인식 및 유형 추론 단계이다. 터널 내에서 규정에 따라 설치되어 있는 CCTV로부터 실시간으로 촬영되어 얻어지는 영상에서 기 설정된 관심영역 영상을 추출한다. 추출된 ROI영상을 2단계의 딥러닝 학습단계를 통해 얻어진 초기 학습완료 DNN의 입력자료로 입력되어, 입력영상 내 객체들을 인식(사각박스형태로 위치와 규모를 인식)하고 인식된 객체들의 종류(차량, 사람, 낙하물, 지장물 등)와 유형(정주행, 정지상태, 역주행, 화재 등)를 추론한다. ROI영상 기준으로 추론된 인식 객체 및 특성들은 원 영상으로 역변화되어 실 CCTV영상에 가시화 되며, 인식된 객체의 유고상황이 인지되면 CCTV 모니터링 시스템에 알림과 동시에 관리자에게 경보를 알리게 된다.
다음의 4단계는 영상, 영상 내 객체 및 객체의 특성을 담은 딥러닝 빅데이터 자동 확장 단계이다. 3단계에서 추론된 영상 내 객체와 객체 유형 등의 정보들은 별도 저장공간에 저장되며, 저장된 객체 및 객체 유형 정보들은 개별적으로 별도의 검토과정을 거나 1단계에서 구성된 빅데이터 학습자료(DS-1)과 동일한 포맷으로 재 저장된다. 검증된 추론결과(DS-N, N은 빅데이터 확장 진행횟수)는 기존의 초기 영상 빅데이터인 DS-1과 합쳐져 확장되며, 확장된 빅데이터를 학습자료로 하여 다시 2단계 딥러닝 학습단계를 통해 동일 학습환경으로 학습이 진행된다. 이후, 2단계부터 4단계는 실시간으로 누적된 터널 내 CCTV영상자료와 함께 지속적으로 반복되며, 이에 따라, 터널 내 객체와 객체 특성으로 구성되어 있는 빅데이터는 자동으로 확장되어 반복적으로 학습자료로 활용된다. 또한, 자동으로 확장되는 학습자료의 반복적인 딥러닝 학습을 통해, 터널 내 이동 객체의 인식률 및 인식된 객체의 돌발상황 인지 성능이 자동으로 향상되어 진화된다.
4. 딥러닝 기반 CCTV 영상 빅데이터의 학습
딥러닝 기반으로 영상 데이터를 학습하기 위하여 우선 CCTV 동영상을 정지영상 이미지로 분리한 다음, 이미지 상에 존재하는 각 객체의 이름과 좌표 정보들로 구성된 레이블을 작성하여 저장하는 작업을 진행한다. 그리고 딥러닝을 학습하여 추론 모델을 얻어 검증하는 작업을 거친다. 본 절에서는 빅데이터의 구성, 딥러닝 학습을 위해 설정된 학습 모델과 학습 환경, 딥러닝 학습 결과 및 결과 분석 내용을 논한다.
4.1 영상 빅데이터 구성 및 특성 분석
4.1.1 Pascal VOC dataset
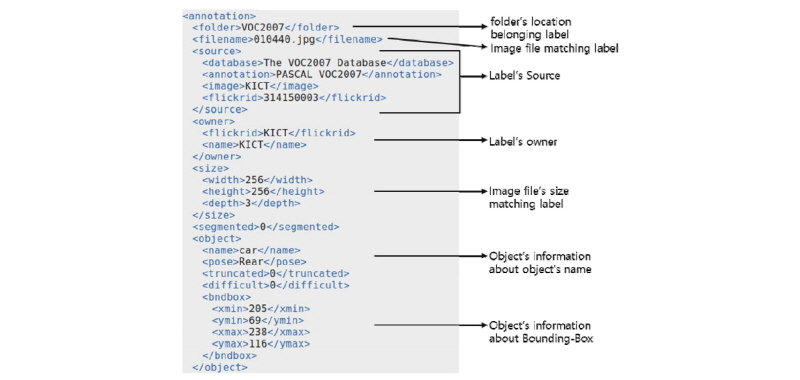
본 연구에 적용된 딥러닝 알고리즘인 Faster R-CNN을 포함한 객체 인식 딥러닝 알고리즘은 이미지와 레이블이 한쌍으로 구성된 큰 규모의 이미지-레이블 빅데이터셋을 요구한다. 현재 웹 상에는 범용 객체인식용 데이터셋인 COCO (Lin et al., 2014), Pascal VOC (Everingham et al., 2010), Kitti dataset (Geiger et al., 2013) 등과 같은 공개 데이터셋들과 그들의 규격들이 공개되어 있다. 객체인식의 용도가 다르다 하더라도 데이터셋의 규격을 맞춘다면 공개된 객체 데이터셋과 연계할 수 있다. 본 논문에서는 Pascal VOC dataset과 그 규격을 사용하였으며, 각 이미지와 쌍을 이루는 레이블의 구성은 Fig. 8과 같다.
본 연구에서 사용한 레이블 파일의 포맷은 xml형식이다. Fig. 8에서와 같이 레이블 파일 내에는 파일 및 이미지의 기본 정보가 기록되어 있으며, 이미지 상에 존재하는 각 객체의 이름이 기록되어 있고, 객체의 위치 및 크기 정보가 하나의 경계박스(bounding-box) 형태로 정의된다. 각 경계박스는 이미지 픽셀 기준으로 최 좌상단을 원점으로 한 이미지 좌표상에서 경계박스의 대각선 양 끝 단의 좌표로 정의된다. 한 레이블 안에 물체가 N개가 있으면 이러한 정보들이 각각 N개가 존재하게 된다.
4.1.2 CCTV 빅 데이터 현황
도로터널 방재시설 설치 및 관리지침(MOLIT, 2016b)에서는 터널 내 영상유고 감지 설비 설치 및 운영 시에는 다음의 4개의 영상유고상황을 감지 및 평가 대상 유고상황 항목으로 규정하고 있다. 이들은 (1) 터널 내 보행자, (2) 충돌 및 정지차량, (3) 역주행, (4) 화재 상황이다. 이러한 터널 내의 유고상황을 학습하기 위해서는 CCTV에서 촬영된 유고상황에 대한 영상데이터가 필요하다. 따라서, 학습자료 확보를 위해 현재 공용중인 터널 관리 현장들을 섭외하여, 영상유고상황이 포함된 방대한 양의 터널 CCTV 영상을 확보하였다. 본 논문에서는 도입된 딥러닝 기반 영상유고 학습 개념에 대한 고찰에 중점을 두기 위해 일반 이동차량과 주요 영상유고 대상객체인 ‘터널 내 보행자’가 존재하는 영상을 일부 발췌하여 딥러닝 학습에 활용하였다. 적용된 데이터는 Table 1과 같다.
본 연구에서는 공식 영상유고 항목 중 정지차량과 역주행 차량의 감지는 일반 이동차량 객체를 인식한 후, 감지된 이동차량 객체의 위치와 크기 정보를 이용하여 차량의 이동 벡터를 계산하고, 현재 정지하고 있는지, 역주행을 하고 있는지를 판단토록 하였다. 따라서, 이동 중인 차량이 정확하게 인식된다면 정지차량 및 역주행 차량을 정확히 인식할 수 있다고 판단할 수 있다. 이와는 달리, 보행자 및 화재 상황은 각각을 별도의 객체로 정의하여 학습시키고, 일반 차량 경우와 같이 독립된 하나의 객체로 감지해 인식하게 된다. 본 논문에서는 상대적으로 많은 영상을 확보한 ‘보행자’ 영상에 초점을 맞추어 고찰하였다.
본 연구에서는 효과적인 학습 및 추론효과 고찰을 위해 Table 1과 같이 데이터셋을 구분하여 명명하였다. 먼저 데이터셋 S1과 S2는 각각 다른 터널현장에서 수집한 데이터셋이며, 각 터널현장에서 얻어진 CCTV 동영상(약 30 frames/sec)들은 1초에 1개의 정지영상(frame)만을 발췌하여 이미지 데이터셋을 구성하였다. 그리고 동일 터널구간에서는 시간이력별로 A(선)와 B(후)로 나누어 데이터셋을 구분해 명명하였다. 이는 현장 CCTV 운영상황을 감안하여, 학습과 추론 시점에 대한 영향을 고찰하기 위함이다.

4.2 딥러닝 학습 환경 설정
4.2.1 학습환경
Faster R-CNN을 학습하기 위한 딥러닝 알고리즘 코드는 파이썬2 (Python2) GPU버전의 텐서플로우(Tensorflow) 딥러닝 프레임워크를 이용하여 작성하였으며, 본 코드를 활용한 딥러닝 학습 환경은 Table 2와 같다.

운영체제는 파이선 2 버전의 텐서플로우를 효과적으로 사용하기 위하여 리눅스 환경을 채택하였으며, 적용된 리눅스는 Linuxmint이다. 학습에 사용된 GPU (Graphic Processing Unit)은 엔비디아의 그래픽카드인 GTX 1070을 사용하였고, 딥러닝 프레임워크는 구글에서 제작한 텐서플로우를 사용하여 딥러닝 코드를 제작하였다. 그리고 Faster R-CNN의 학습속도는 측정 결과, 시간당 약 20,000회 반복할 수 있는 학습속도 성능을 보였다. 이는 도입된 딥러닝 알고리즘의 속성상 정지영상 내 포함된 객체의 수와 무관하게 유사한 학습속도를 기대할 수 있다.
4.2.2 Faster R-CNN 및 RPN의 설정 상수
Faster R-CNN과 RPN은 학습을 용이하게 하기 위하여 사전에 보정이 완료된 상수를 사용하며, 본 연구의 학습에 적용된 대표 학습상수들과 적용 값들은 Table 3과 4와 같다.


Table 3에서 학습률(learning rate)은 Fig. 4의 딥러닝 모델 갱신과정에서 갱신 속도를 조절할 수 있는 상수로, 너무 높으면 모델의 수렴이 잘 되지 않으며, 너무 낮으면 모델의 수렴은 되나 수렴 속도가 느려진다. 학습이 종료되는 최대 학습반복회수(maximum iteration)는 5만 번으로 설정하였다. 이미지 크기(image scale)은 이미지를 학습에 반영할 때, 촬영된 CCTV 원영상의 해상도로 학습되는 것이 아니라, 원해상도를 학습 시스템에 설정된 이미지 크기로 일괄적으로 조정하여 학습에 반영된다. CNN은 VGG network를 이용하여 학습하였는데, 이는 VGG network의 구조가 비교적 간단하면서도 모델의 성능이 우수하기 때문이다(Karen and Andrew, 2014).
Positive overlap과 Negative overlap은 영역 제안 네트워크(Regional Proposal Network, RPN)에서 요구되는 학습상수이다. 각 이미지 상에서 수 만개의 경계박스가 각 이미지 내 픽셀을 옮겨가며 무작위로 제안되며, 각 경계박스 내에서 객체의 존재 가능성을 0에서 1 사이의 값으로 계산하게 되는데, 계산된 존재 가능성 값을 가지고 제안 경계박스 내 객체가 존재하는지, 아니면 그냥 배경인지를 판단하여야 한다(Ren et al., 2015). Positive overlap은 이 값 이상일 때 해당 경계 박스는 객체라고 판단할 수 있고, Negative overlap은 이 값 이하일 때 해당 경계 박스를 배경으로 판단한다. 이와 같이, 영역 제안 네트워크 학습과정 후에는 수 만개의 경계박스가 제안된 상태가 되며, 이 경계박스들을 전부 Faster R-CNN 알고리즘으로 전송하면 너무 과도한 계산이 수행되어야 하므로, 수 만개의 제안된 경계박스 중에서 가장 점수가 높아 객체일 가능성이 높은 N개의 경계박스만 Faster R-CNN 알고리즘으로 전송하여 학습을 진행하게 된다.
4.3 딥러닝 학습 모델 설정 및 학습 결과 분석
4.3.1 학습 모델 설정
학습 모델은 크게 같은 터널 내에서만 학습과 추론이 진행되는 시나리오(Test Scenario 1, TS1)와, 복수의 터널에서 학습이 진행되고 학습에 포함된 각각의 터널에 대해 추론이 진행되는 시나리오(Test Scenario 2, TS2)로 구분하여 설정하였다. 이러한 학습 및 추론 시나리오 모델을 Fig. 9에 도식화하여 나타내었다.
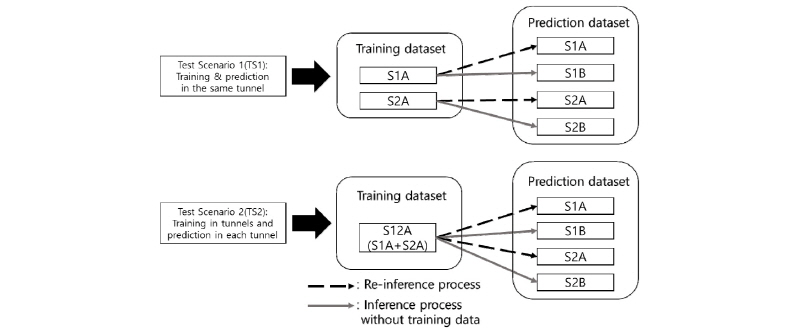
TS1은 S1과 S2 터널에서 수집한 영상자료의 선행 데이터셋인 S1A과 S2A을 각각 학습하고, 각각에 대한 학습 데이터셋을 재추론(re-inference)하여 학습이 충분히 되었는지를 확인한다. 학습되지 않은 후행 데이터셋에 대한 추론을 통해서는 동일 터널조건의 영상이지만 학습에 사용되지 않은 후행 영상에 대한 객체 및 유고상황 감지 성능을 검토해보고자 하였다. TS2는 일정시간(A) 구간에서 촬영된 가용한 영상 데이터셋 S1A와 S2A 모두를 학습에 사용하였고, 역시 학습에 사용된 각각의 학습자료의 재추론을 통해 학습이 충분히 이루러 졌는지 확인코자 하였고, 이어 학습에 사용되지 않은 시간 구간(B)의 데이터셋에 대한 추론을 통해 추론성능을 검토해 보고자 하였다.
4.3.2 객체인식 추론 성능 분석
본 논문에서는 설정된 각 학습 및 추론 시나리오에 대하여 결과한 학습 및 추론 성능을 2.2절에서 언급된 AP값을 이용하여 고찰하였다. AP값은 학습이 진행된 시점을 기준으로 추론대상 데이터셋에 대해 계산가능하며, 객체의 인식 성능과 인식된 객체의 유형 판단의 정확도를 종합하여 나타내는 지표로 활용될 수 있다. 그리고 각 추론대상 데이터셋마다 추론대상 객체인 ‘이동차량(car)’과 ‘보행자(person)’에 대해 각각 AP값을 계산하고 비교 검토될 수 있다.
Fig. 10에서는 S1 데이터셋에 대한 학습횟수에 따른 AP값의 변화추이를 나타냈었다. AP값이 1에 가까울수록 추론성능이 좋다고 판단할 수 있다. 학습에 대한 추론은 매 1만 번의 학습횟수 때마다 AP 평가를 진행하였고, 각각 추론할 데이터셋엔 차량 및 사람에 대한 레이블 정보가 모두 존재하므로 객체의 종류마다 AP를 평가하여 도시하였다.
S1터널 데이터셋의 경우에 대한 결과를 보면(Fig. 10(a)), 학습된 데이터셋에 대한 재추론은 AP값 0.9 이상 수준으로 매우 높은 추론성능을 보여 학습이 효과적으로 잘 수행되었음을 알 수 있다. 학습되지 않은 B시간구간에서는 차량의 경우, 학습이 되지 않았음에도 AP값이 0.8 이상으로 매우 높은 추론성능을 보여 객체인식이 이루어 졌음을 알 수 있다. 하지만 학습되지 않은 구간의 보행자 객체의 인식은 AP값 수준이 0.4 이상 0.6 이하정도로 나타나 상대적으로 낮은 추론성을 보였지만, 학습이 진행되면서 점차 AP값이 향상되고 있는 경향을 보이고 있다. 이와는 달리, 학습된 구간의 차량과 보행자, 그리고 학습에 사용안된 차량의 경우는 30,000회 이상의 학습이후에는 유사한 AP값 수준으로 추론성능이 수렴되고 있음을 알 수 있다.
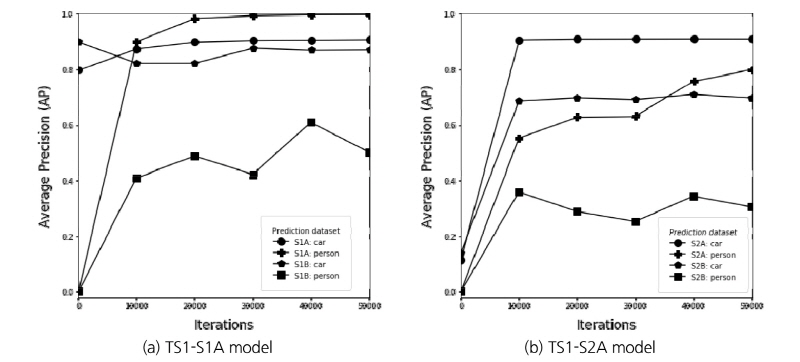
S2터널의 데이터셋에 대한 학습의 경우(Fig. 10(b)), 학습에 반영된 구간과 학습에 반영안된 시점 구간의 차량 객체의 추론성능은 AP값이 각각 0.9 이상, 0.7 이상으로 우수한 성능을 보였으며, 10,000회 이상의 학습회수 이후에는 추론성능이 수렴된 것을 알 수 있다. 보행자 객체에 대해서는 학습된 보행자에 대해서는 객체인식 추론성능이 학습이 진행됨에 따라 지속적으로 향상되고 있는 경향을 보이고 있어 궁극적으로 50,000회 이상의 학습단계에서는 0.8수준 이상의 추론성능을 보이고 있다. 하지만, 학습되지 않은 시간구간의 보행자 객체의 경우에서는 S1터널의 경우와 같이 0.4 이하 수준으로 상대적으로 낮은 수준의 추론성능으로 수렴되고 있음을 알 수 있다.
이를 통해, 결론적으로 학습된 객체가 학습되지 않은 객체보다 추론성능이 우수함은 당연히 추론성능 결과를 통해 확인할 수 있으며, 차량의 경우 학습되지 않은 객체에 대해서도 매우 양호한 AP값 수준의 추론성능으로 객체 인식이 가능했다. 이를 통해, 상대적으로 가용한 객체의 수가 현저히 적었던(차량 객체의 수의 5% 이하 수준) 보행자의 경우는 상대적으로 낮은 AP수준으로 추론성능을 보였으나, 지속적으로 가용한 보행자 객체의 수가 점차 증가하고, 추가 학습이 진행된다면 학습되지 않은 보행자의 추론성능도 향상될 수 있을 것으로 예측할 수 있다.
Fig. 11은 A시간구간 동안 S1터널과 S2터널에서 확보한 데이터셋을 통합하여 학습한 추론 성능 결과를 나타낸다. 학습에 사용된 데이터셋에 대한 재추론 결과, S1터널의 경우는 차량과 보행자 공히 0.8 이상의 AP값으로 매우 우수한 성능의 추론결과를 보였다. S2터널의 경우, 차량 객체에 대한 추론은 0.8 이상으로 매우 우수한 추론성능을 보였다. 이와는 달리, 보행자의 경우는 상대적으로 낮은 0.6의 AP수준으로 추론성능을 보였으나, 학습이 진행됨에 따라 현격히 추론성능이 향상되고 있는 것을 보이고 있다. 이는 통합된 학습자료를 학습하는 과정에서 S1터널의 객체들과 S2터널의 차량 객체가 우선적으로 학습이 진행되었고, S2터널의 보행자 객체가 후행 하여 점차 학습수준이 향상되고 있음을 알 수 있다. 이는 충분히 추가 학습이 진행된다면 S2터널의 보행자 객체도 S1터널의 보행자 수준으로 재추론 성능을 보일 수 있음을 의미한다. 또한, 서로 다른 CCTV설치 및 촬영 환경에서 촬영된 터널 자료들의 통합 학습 시에도, 각각의 터널 객체에 대한 추론성능은 결코 떨어지지 않고 동일 이상 수준의 추론성능을 보일 수 있음을 알 수 있다.
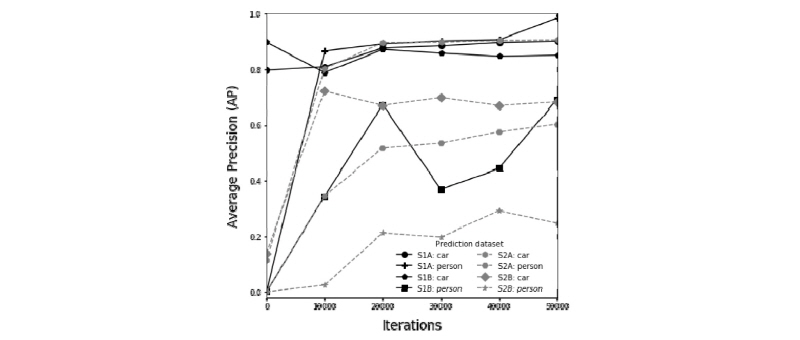
학습되지 않은 시간구간(B)에 대한 객체인식 추론의 경우, Fig. 10의 경우와 유사한 추론성능 평가 경향을 보였다. S1 및 S2 양 터널 모두, 차량 객체의 경우는 0.7 이상의 우수한 추론성능을 보였으나, 보행자 객체의 경우는 상대적으로 낮은 추론성능을 보였다. 그리고 S1터널의 보행자 객체의 경우도 20,000회 학습 이후부터는 0.7 AP수준의 높은 추론성능을 보였고, 학습이 진행됨에 따라 지속적으로 추론성능이 향상되는 경향을 보였다. 이는 Fig. 10의 경우와 같이, 양 터널 모두 보행자 객체 수의 부족으로 추론성능이 상대적으로 낮게 나타난 것으로 판단되며, 향후 가용한 객체 영상이 지속적으로 증가하고 추가학습이 진행된다면 그 추론성능이 차량에 대한 추론성능 수준으로 크게 향상될 수 있을 것으로 판단된다.
또한, TS2모델과 같은 통합자료의 학습과 추론 모델을 통해 다양한 터널에서 확보된 영상 데이터셋이 다른 터널의 이동 객체 인식 및 영상유고감지에 활용될 수 있음을 보였다. 따라서, 다양한 터널의 유고영상을 통합관리하고, 통합자료를 학습자료로 활용하는 것이, 개별 터널 내에서 유고영상을 관리하고 시스템에 반영하는 것 보다 유고영상 빅데이터를 보다 빠르게 확장시킬 수 있으며, 보다 효과적으로 유고영상 빅데이터를 관리할 수 있을 것으로 판단된다. 본 연구를 통해, 딥러닝 영상유고추론 성능은 인식 대상 객체 및 유고영상 데이터 확보 수준에 가장 크게 영향을 미침을 알 수 있었으므로, 향후 유고영상 빅데이터 확보 및 관리가 터널 영상유고감지 성능 확보를 위해서 가장 중요한 사항이라 할 수 있다.
4.3.3 객체인식 추론 영상 분석
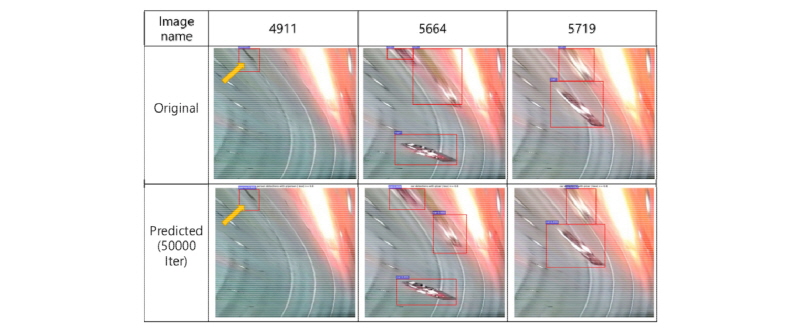
Fig. 9에서 명명된 TS1과 TS2 학습모델을 통해, 학습되지 않은 시간구간(B)의 몇몇 정지 이미지 내의 객체 들을 인식하고 그 유형을 추론한 결과들의 추론 영상을 Fig. 12~15에 나타내었다. 그림 상에서 Original이라고 표현된 영상은 학습에 사용되지는 않았지만, 영상 내 객체와 객체의 유형이 정의되어 있는 이미지이다. 또한, 추론 결과 영상(predicted image)은 학습모델을 50,000회까지 학습을 진행하고 추론한 영상으로 original 영상과 비교를 통해 추론 성능을 육안으로 확인할 수 있다. TS1-S1A의 학습모델의 경우는 학습되지 않은 2435번 영상 이미지의 보행자를(화살표시) 정확히 인식하였으나 2543번 및 2595번 영상 이미지에서는 인식하지 못했음을 알 수 있다. 하지만, 상대적으로 차량 객체는 모든 발췌영상 이미지 내에서 상대적으로 정확히 객체를 파악하여 추론해 낸 것을 알 수 있다. TS1-S2A 학습모델의 경우에서는 4911번 영상 이미지에서 보행자 영상을 정확히 감지하였으며, 타 영상 이미지에서는 존재하는 차량 객체를 감시해 냈다. 특히, 5680번 영상 이미지 상에서는, 원본 영상의 상단 부에 작은 크기의 차량이 존재했지만 객체로 정의하지 않았으나, 추론단계에서 차량으로 감지한 사례를 보여준다.

Fig. 13에서는 TS2-S12A 통합 학습모델을 이용하여 학습되지 않은 S1B 데이터셋의 몇몇에 대해 추론한 결과 이미지를 보여준다. 2435번 이미지에서는 차량 옆에 위치한 보행자를 정확히 감지하였으나, 2543번과 2595번 이미지에서는 감지하지 못했음을 보여준다. 하지만 차량의 경우는 그 차량의 크기에 대한 추론 정도에 차이가 있으나, 많은 차량이 존재함에도 객체인식 추론이 잘 이루어 졌음을 알 수 있다. 또한 Fig. 13에서는 동일한 통합 학습모델을 이용하여 S2B 데이터셋에 대한 추론 영상 일부를 도시하였다. 그림과 같이 모든 영상 이미지의 차량과 보행자 객체가 정확히 인식되었음을 알 수 있다.


5. 결 론
본 논문에서는 터널 영상유고감시 시스템을 개발하기 위하여 최신 영상 딥러닝 알고리즘의 하나인 Faster R-CNN 알고리즘을 코드화 하였고, 이를 이용해서 운용중인 2개의 터널현장(TS1과 TS2)에서 수집된 유고영상 데이터셋을 학습하여 터널 내 영상유고 대상객체에 대한 객체인식 추론성능을 고찰하였다. 본 연구를 통해 얻어진 주요 연구결과와 결론은 다음과 같다.
1.CCTV 촬영 및 설치조건이 매우 열악한 폐쇄된 터널 내부의 환경에도 불구하고, 터널 CCTV 영상을 통해 보여지는 다수의 이동 차량과 고정상의 주요 영상유고 대상 객체인 보행자 객체들은 성공적으로 학습될 수 있음을 보였다. 학습 후, 추론단계에 있어서는 학습시점과 가까운 시간구간에서는 높은 추론성능을 기대할 수 있었다.
2.학습단계와 추론단계의 시간차가 클 경우에, 학습단계에서 충분한 객체가 확보되어 있었던 차량 객체의 경우는 그 추론성능이 매우 우수했으나, 상대적으로 가용한 객체의 수가 적었던 보행자 객체의 경우는 그 추론성능이 현저히 떨어졌다. 이를 통해, 추론단계의 학습되지 않은 객체에 대한 추론 성능은 지속적인 추가 반복학습을 통해 확보될 수 있으며, 학습에 가용한 객체의 개수와 다양성 확보 수준이 그 객체에 대한 추론 성능을 좌우하는 것으로 판단된다.
3.두 개의 다른 터널에서 확보된 객체 및 유고영상들을 통합한 자료로 학습하고, 학습에 사용되지 않은 터널 영상 이미지에 대한 추론성능 분석을 통해, 다양한 터널에서 확보된 통합 영상자료가 다른 터널의 객체 인식 및 영상유고감지에 활용될 수 있음을 보였다. 따라서, 다양한 터널의 유고영상을 통합관리하고, 통합자료를 학습자료로 활용하는 것이, 개별 터널 내에서 유고영상을 관리하고 시스템에 반영하는 것 보다 유고영상 빅데이터를 보다 빠르게 확장시킬 수 있으며, 보다 효과적으로 유고영상 빅데이터를 관리할 수 있을 것으로 판단되었다.
결론적으로 본 연구를 통해, 딥러닝 영상유고 추론 성능은 인식 대상 객체 및 유고영상 데이터 확보 수준에 가장 크게 영향을 미치며, 향후 터널 유고영상 빅데이터 확보 및 관리가 터널 영상유고감지 성능 확보를 위해서 가장 중요한 사항인 것으로 판단되었다. 또한, 학습자료에 지배되는 터널 영상유고 추론 성능은 터널 CCTV 영상 및 유고상황 빅데이터의 지속적 확장과 지속적인 반복학습을 통해, 시스템의 추가 보정이나 수정 없이도 그 추론성능이 자동으로 향상되며, 예기치 못한 다양한 상황에서도 자동으로 적응 가능할 것으로 판단된다.
