

1. 서 론
2. 연구 배경
2.1 영상 처리 기반 차량 탐지 기법
2.2 머신 러닝 기반 차량 탐지 기법
3. 터널 영상유고 기법들의 실험적 비교 검토
3.1 실험 범위
3.2 각 실험에 사용된 알고리즘
3.2.1 영상처리 기법 : 모션 히스토리 및 비-최대 억제 기법
3.2.2 머신 러닝 기법 : HoG를 이용한 차량 탐지
4. 실험 결과
4.1 실험 1 : 터널 입구 실험
4.1.1 MHI-NMS 기반 모델
4.1.2 HoG-NMS 기반 모델
4.1.3 결과 분석
4.2 실험 2 : 터널 내부 실험
4.2.1 MHI-NMS 기반 모델
4.2.2 HoG-NMS 기반 모델
4.2.3 결과 분석
4.3 실험 3 : 터널 출구 실험
4.3.1 MHI-NMS 기반 모델
4.3.2 HoG-NMS 기반 모델
4.3.3 결과 분석
5. 결 론
1. 서 론
본 논문에서는 터널 내 설치되어 있는 CCTV영상을 통해 돌발 유고상황을 자동으로 탐지하고 빠른시간 내에 현장대응을 유도하여 2차 사고를 예방할 수 있는 시스템을 개발하기 위한 선행 연구를 수행하였다. 본 선행 연구는 터널 내 자동 영상유고 시스템 개발을 위해 핵심 정보를 제공하기 위한 터널 내 차량을 탐지하여 이동 동선을 추적하는 기법들을 검토하였으며, 그 효과들을 고찰하였다.
정지영상 및 동영상에서 특정 물체를 탐지하고 추적하는 기술은 영상처리 기술의 발전과 함께 지속적으로 발전되어 왔다. 단순하게 영상 자체를 분석하거나 영상의 화질을 개선시키는 원론적인 방법과 영상 내에 존재하는 사물, 동물 등을 탐지, 분류하는 기술들은 영상을 이용한 보안 분야에서 많이 응용되어 왔다. 근래에는 인공지능 개념에 기반한 머신 런닝(신휴성 등, 2017) 및 딥러닝 기법의 발전으로 영상에 포함된 피사체들을 탐지하고 분류하는 기술들이 새로이 시도되고 발전되고 있으나, 현재에도 영상 내 객체의 탐지 및 추적 분야는 여전히 딥러닝 보다 특정화 된 알고리즘을 기반으로 구동되고 있는 것이 현실이다.
영상처리 기술에서 탐지 기술과 추적 기술의 차이는 시간 축에 대한 해석의 유무에 따라 달라진다. 현재 정지영상에서 특정 물체의 존재 유무와 영상 내에서의 위치를 알아내는 것을 탐지 기술로 본다. 그리고 연속적이거나 여러 시간에 걸쳐 수집된 정지영상들의 집합, 또는 동영상을 대상으로 이전 프레임과 현재 프레임에서 탐지한 물체의 동일성, 위치 변화, 상태변화를 알아내는 것을 추적 기술로 본다. 두 기술의 특성 차이로 인해 영상을 이용한 감시 시스템에서는 두 기술을 번갈아 가며 사용하거나 동시에 사용하는 방법을 사용한다. 본 논문에서는 탐지 기술에 집중하며, 추적 기술은 비-최대 억제 기법 기반의 탐지 상자 병합 기법을 이용해 처리하는 방법을 사용한다.
일반적으로 영상을 처리함에 있어 특정 물체를 탐지하고 추적하는 기술은 카메라의 배치와 조명의 배치에 크게 영향을 미친다. 카메라의 배치는 두 가지 조건을 최대한 만족시키는 곳을 찾아내는 것으로 시작된다. 첫 번째 선결 조건은 공간영역 내에서 시야 사각을 최소화 시켜 최대한 넓은 범위를 감시할 수 있는 위치를 찾는 것이다. 두 번째 조건은 감시 대상 피사체에서 탐지하기 쉬운 특징점이 가장 잘 보이는 위치를 찾는 것이다. 두 가지 조건이 어떤 상황에서도 항상 완벽하게 만족되는 위치는 존재하지 않기 때문에 두 가지 조건을 잘 평가하여 적절한 위치에 카메라를 배치해야 한다. 이후 조명의 배치는 감시 대상 피사체의 특징점이 잘 드러날 수 있도록 광원의 위치와 반사각 등을 고려하여 최적의 위치를 선정해야 한다. 하지만 본 논문에서 다루어 지는 터널 내부에서는 카메라 및 조명 배치가 이미 지정되어 있다는 큰 제약조건이 따른다.
터널 내부 환경은 시각적으로도 피사체들의 특징을 검출 해내기 매우 어려운 환경이다. 기본적으로 터널 내부는 카메라에 대한 유지보수를 수행하기 어렵기 때문에 성능보다는 내구성을 우선시한 카메라가 선정되어, 대체적으로 낮은 해상도의 영상을 획득하게 된다. 또한 조명이 시간대에 따라 지속적으로 조정이 되어 변화하기 때문에 조명의 강도도 일정하지 못하다. 전반적으로 어두운 영상을 획득하게 되며, 조명 자체의 색상으로 인해 영상에서 피사체의 색상도 왜곡되어 색상 기반 피사체 탐지 또한 어렵게 된다. 카메라로부터 습득하는 영상의 취득 속도도 문제가 될 수 있다. 대부분 구형 카메라를 사용하고 있기 때문에 영상 취득 속도가 30 fps조차 되지 않는 경우도 많으며, 카메라의 노출 정도가 충분치 않아 이동체의 흐려짐 현상(Motion blur)이 발생하게 된다. 이는 곧 영상으로부터 피사체의 특징점 추출 자체가 어려워 질 수 있다는 의미이다. 이를 극복하기 위해 개별 피사체의 특징을 차영상 기반으로 추출하게 되면 정차 차량에 대한 탐지가 어렵게 되며, 배경 학습 기법을 기반으로 차량을 탐지하게 되면 영상의 노이즈로 인해 차량을 탐지하기 어렵게 되거나 정차한 차량이 배경으로 오인식 되는 등의 문제점이 발생할 수 있다. 또한, 색상을 기반으로 차량을 탐지하게 되면 터널의 조명으로 인해 차량들의 색상을 구분하기 어려워 제대로 된 차량 탐지가 이루어지지 않을 수 있다.
본 논문에서는 이런 문제점들을 해결하기 위하여 차량의 탐지와 추적을 구분하여 고찰하였다. 본 논문에서 수행한 세 가지 기법 중, 첫 번째는 일정 시간 동안 취득한 차영상들의 단계별 합산을 통한 모션 히스토리 이미지를 이용해 화면에 나타나거나 이동한 차량들을 탐지하는 방법이다. 차량의 추적 기법은 색상의 히스토그램 비교만으로는 불가능하기에 최초 탐지한 차량 영역에 대해 초기 추적 윈도우를 설정하고 이 추적 윈도우와 가장 많이 겹치는 탐지 상자를 선택하여 이동 경로를 나타내는 추적 기법을 사용한다. 두 번째 방법은 Haar Cascade 기법을 이용한 차량 탐지 기법으로 Haar-like 특징점을 이용해 학습을 수행한 후 차량을 탐지하는 머신 러닝 기법이다(Viola and Jones, 2001). 추적 기법은 첫 번째와 동일한 방법을 사용하였다.
논문에서는 일반적인 환경에서의 영상 내 차량 탐지와 추적이 아닌, 터널 영상에서의 차량 탐지로 연구 범위를 설정하였다. 카메라의 배치는 한국의 터널 내 일반적인 CCTV 카메라 배치인 후방 측면을 바라보는 방향으로 설정한다. 또한 본 연구에서는 CCTV 카메라의 PTZ (Pan-Tilt-Zoom) 기능을 활성화하여 카메라가 움직이고 있는 동안에는 기능을 중지하는 것으로 한다. 본 연구에서는 조명의 상태는 터널에서 가변적으로 변화하고 있는 모든 상태에 맞추어 자동적으로 적응하는 것으로 하되, 조명 자체가 완전히 꺼지거나 조명이 고장 나서 육안으로도 영상을 판별하는 것이 불가능한 상황은 무시하는 것으로 한다.
본 논문은 다음과 같은 구조로 기술하였다. 1장에서는 본 연구의 필요성과 기존 방법들의 한계성에 대해 서술하고 있다. 2장은 관련 연구들과 각 연구들의 한계점, 그리고 본 연구에서 극복한 한계점들을 기술한다. 3장에서는 본 논문에서 제안하는 방법의 전체 형태와 세부 구현 전략을 설명한다. 4장에서는 본 논문의 방식을 이용해 구현한 알고리즘의 실험 결과와 기존의 다른 방법들의 실험 결과를 비교한 후 마지막 5장을 통해 추후 필요한 연구와 적용될 수 있는 분야에 대한 의견을 제시한다.
2. 연구 배경
서론에서 언급된 바와 같이, 터널 영상에 대해서 영상 처리 기법과 머신 러닝 기법을 이용한 두 가지 방법에 대해서 실험을 진행하고 상호 간 비교를 통해 조건별 적절한 방법에 대해 논의하고자 한다. 영상 처리 기법과 머신 러닝 기법의 차이점은 특징점의 구현 방법과 탐지기법에 있다. 영상 처리 기법은 특징점을 사람이 직접 이해하고, 직접 알고리즘화 하여 코딩작업을 통해 직접 프로그램을 제작하여야 한다. 이후, 코드화된 알고리즘의 규칙에 의거 영상 내 차량들과 그 특징을 탐지한다. 반면 머신 러닝 기법은 영상 내 차량들과 그 특징점들을 터널환경과 연계하여 기계에 통해 학습하고, 학습된 결과를 통해 학습되지 않는 영상 내 차량과 그 특징을 탐지해 추론해 낸다. 본 연구에서는 Support Vector Machine (SVM)이나 K-Means Classifier (Hartigan and Wong, 1979) 등의 머신 러닝 기법을 활용해 터널 영상 내 차량 및 특징을 학습시켜 그 효과를 분석하였다.
2.1 영상 처리 기반 차량 탐지 기법
단순하게 영상에서 직접 사람이 특징점을 추출하고 이를 기반으로 차량을 탐지하는 기법은 여러 가지가 있다. 첫 번째로 Saliency를 이용한 기법이 있다(Alonso et al., 2008). 이 기법은 이미지에서 시각적으로 도드라진 특성을 이용, 차량이 있을 법한 후보군을 추출한 후 크기에 따라서 차량을 분류하는 기법이다. 두 번째 방법은 Edge 정보를 이용한 방법으로 이미지 내의 색상 사이 경계선을 이용해 탐지하는 기법이다(Tsai et al., 2007). 이 방법은 비교적 사람이 육안으로도 특징을 쉽게 이해할 수 있다는 장점이 있으나 잡음에 민감하다는 단점이 있다. 세 번째 방법은 Difference of Frames 기법을 이용하는 방법(Zhang and Wu, 2012)이다. 여러 프레임에 걸쳐 영상의 차영상을 얻어내고, 이를 기반으로 움직이는 모든 물체들을 분류해 낸다. 이후 분류된 물체들을 크기에 따라서 차량/사람 및 기타 물체로 구분한다. 이 방법은 비교적 구현이 간단하고 실시간성이 보장되는 방법이지만 동시에 도로 색상과 유사한 차량은 잘 탐지 해내기 힘들다는 문제점이 있다. 또한 여러 대의 차량이 몰려서 이동하거나 유사한 색상의 차량이 연달아 지나가는 경우 잘못 인식할 확률이 있으며, 차영상 생성 기법에 따라서 버스나 트럭 등 대형 차량은 탐지가 되지 않을 수 있다. 네 번째 방법은 Background Subtraction 기법을 이용한 방법으로, 차량이 없는 터널 배경 영상을 생성한 후 지나가는 차량들을 인식하는 기법이다(Unzueta et al., 2012). 이 방법은 차영상 기법에 비하면 느린 속도를 보이지만, Saliency 등을 사용하는 기법에 비해서 상당히 빠른 속도를 가지고 있다. 하지만 색상 변화에 민감한 편이고 차영상을 이용한 기법과 마찬가지로 카메라가 움직이거나 진동이 발생한 경우, 조명에 변화가 발생한 경우에 민감하다. 또한 도로 색상과 비슷한 차량의 색상은 탐지하기 어려운 문제점이 있다. 그리고 차영상, 배경 추출 기법 모두 오랫동안 서있는 물체에 대해서는 인식이 어렵다.
2.2 머신 러닝 기반 차량 탐지 기법
머신 러닝 기반 차량 탐지 기법으로는 첫 번째로 Histogram of Oriented Gradient (HoG)를 이용한 기법(Cekander et al., 2006)이 있다. HoG의 경우는 차량 뿐만 아니라 보행자, 특정 물체 등 다양한 케이스를 인식할 수 있으나, 분류기로 SVM을 사용하는 경우는 SVM의 특성 상, 단일 종류에 대한 True/False 판정만 가능하기에 1종류의 객체만 인식할 수 있다. 또 다른 기법으로는 Local Bit Pattern (LBP) 특징점을 이용한 방법이 있다(Chen et al., 2010). 이 방법은 미리 지정된 샘플의 특징점(직선, 대각선 등의 이진 패턴)에 대해 학습을 수행하고 이를 기반으로 탐지를 수행하는 기법이나, 흑-백의 단순 패턴만 사용한다. Haar-Cascade 기법은 LBP 패턴처럼 이진 패턴을 사용하나 저-고-저, 고-저-고의 조금 더 복잡한 패턴을 특징으로 사용해 학습을 진행한다(Haselhoff and Kummert, 2009). 또한 분류기로 HoG처럼 SVM을 사용할 수도 있으며, Bag of Word (BoW) 기법을 이용해 다중 클래스 분류 또한 가능하다(Yu et al., 2013). 본 논문에서는 HoG 기반에 차량만을 학습시켜 SVM 분류기로 실험을 진행하였다.
3. 터널 영상유고 기법들의 실험적 비교 검토
본 논문에서는 세 가지 방법을 직접 구현하고 실험하며, 이 결과를 통해 터널 유고 상황 판정을 위한 각 방법의 장단점을 파악하고 추후 필요한 후속 연구의 방향을 설정코자 하였다. 1, 2장에서 소개한 바와 같이 영상처리 기법, 머신 러닝 기법의 두 가지 방법론에 대해 실험을 진행하였다.
3.1 실험 범위
본 논문에서는 실험 범위를 “터널 환경”으로 한정 짓는다. 또한 각 기법에서 발생하는 장/단점의 차이를 최소화하기 위해 “장대터널” 환경으로 한정하고 “직선 구간”으로 범위를 제한하였다. 터널 내의 조명 상태는 항상 동일한 조건이 되도록 하여 특정 기법에 유리하지 않도록 하기 위해 동일한 영상을 선택하는 것으로 하였다. 선택된 모든 영상은 차선 변경이 불가능한 실선 구간 영상만 사용하였다.
본 논문에서는 다음과 같은 사유로 두 가지 방법을 나누어 접근한다. 특징점 정의와 추출 방법의 차이점 때문이다. 영상처리 기법을 기반으로 접근할 때에는 특징점과 추출 방법을 모두 직접 정의해야 한다. 머신 러닝 기반의 방법은 특징점만 직접 정의를 해주고 추출은 프로그램, 시스템이 직접 진행하되 학습이라는 과정이 추가가 된다. 이로 인해 대규모의 학습 데이터가 사전에 만들어져야 한다. 이는 곧 사람에 의한 수정이 즉시 이뤄지기 어렵고 새로운 사례 발생 시에도 이를 즉시 반영하기 어렵다는 것을 의미한다.
3.2 각 실험에 사용된 알고리즘
3.2.1 영상처리 기법 : 모션 히스토리 및 비-최대 억제 기법
본 논문에서 첫 번째 실험으로 사용한 기법은 Motion History Image (Javed and Shah, 2002)와 Non-Maxima Suppression (Neubeck and Van Gool, 2006)을 이용한 방법이다. Motion History Image (이하 MHI)는 차영상의 단점을 극복하기 위한 방법이며, 차영상을 통해 직전 프레임과 현재 프레임, 혹은 직전 프레임과 다음 프레임 사이의 색상 차이를 이용해 움직인 물체가 존재하는지를 확인하게 된다.단, 지나치게 민감할 경우 바람에 나무가 흔들리는 것도 감지가 될 수 있으며 카메라가 움직이지 않는다는 전제가 필요하다. 그리고 다루는 시간의 범위가 매우 좁기 때문에 정지해 있는 물체에 대해서는 탐색이 어렵다. 반면 MHI는 원하는 만큼 긴 시간에 걸쳐서 영상을 생성한다. MHI는 여러 시간에 걸쳐서 발생한 차영상들을 누적시킨 이미지를 의미한다. Fig. 1에서 좌측은 차영상을 이용해 움직임을 탐지한 것을 나타내고 오른쪽은 MHI를 이용해서 움직임을 탐지한 것을 나타낸다.

Fig. 1에서 차영상을 이용한 기법은 차량의 일부만 감지되는 문제점이 있다. 차량 속도가 현저히 느리거나, 혹은 정차했거나, 차량의 크기가 너무 큰 경우에 차량의 일부만 감지될 수 있다. 또한 차영상을 기반으로 할 경우 정차한 차량은 탐지가 되지 않는다. 반면 MHI를 이용한 방법은 차량이 느리게 움직이더라도 여러 프레임에 걸쳐서 누적 시키기 때문에 차량의 대부분을 움직임 영역으로 감지할 수 있다. 하지만 수치 수준에 따라서 차량보다 더 넓은 영역이 감지될 수도 있다.
비-최대 억제 기법(Non-Maxima Suppression, 이하 NMS)를 이용한 추적 방법은 이전 프레임에서 획득한 움직임 탐지 영역 리스트와 현재 프레임에서 획득한 움직임 탐지 영역 리스트를 비교하여, 지나치게 작은 영역 리스트는 무시하고, 가장 유사한 영역들을 병합, 선정하여 이전 프레임, 현재 프레임 사이의 움직임 궤적을 추적할 수 있는 기법이다. 본래는 겹치는 여러 영역들을 점수에 따라 가장 높은 점수의 영역으로 병합하는 기술이나, 본 논문에서는 추적용으로 사용하기 위해 일정 수준 이상 겹치는 영역들을 병합하는 용도로 사용하였다. Fig. 2는 탐지-추적이 결합된 MHI와 NMS를 이용한 프로그램의 의사 코드이다.

3.2.2 머신 러닝 기법 : HoG를 이용한 차량 탐지
HoG 기법은 여러 개의 미리 정의된 특징 종류를 조합하여 원하는 물체가 존재하는지를 확인하는 기법이다. 경계선 특징, 일반선 특징, 중앙 돌출 특징 등 다양한 특징들을 이용한다. Fig. 3은 HoG들을 나타낸다.
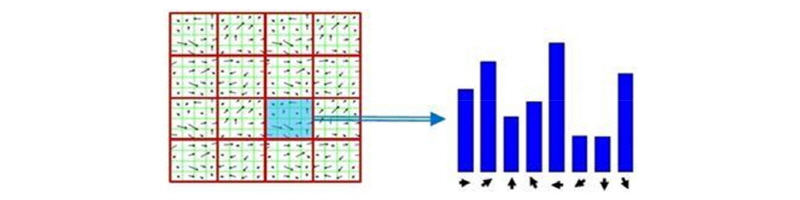
이 기법은 BoW와 유사하다고 볼 수 있으며, SVM 분류기를 통한다면 해당 클래스에 대해 Positive/Negative만 확인할 수 있으나 분류기의 확장을 구현한다면 BoW 분류기를 이용해 다중 물체 탐지 또한 수행할 수 있다. 하지만 본 논문에서는 차량 탐지와 추적을 통한 유고상황 선행연구를 목표로 하기 때문에 SVM 분류기를 이용한다.
추적 기법에 대해서는 영상처리 기법과 동일하게 NMS 방법을 사용한다. HoG는 기본적으로 이미지에 대해서 설계된 특징이기 때문에, 여러 영상에 걸친 움직임은 잡아내지 못하기 때문이다. 이에 대해서 HoG 방법론만으로 해결하기 위해서는 HoG를 시간 차원에 대응할 수 있도록 3차원 연산을 별도로 개발하고 적용시켜야 한다. 본 논문에서는 가능성 확인 차원에서 시간 차원에 대한 대응은 별도로 구현하지 않고 기본적인 HoG 기법을 사용하는 것으로 한다.
4. 실험 결과
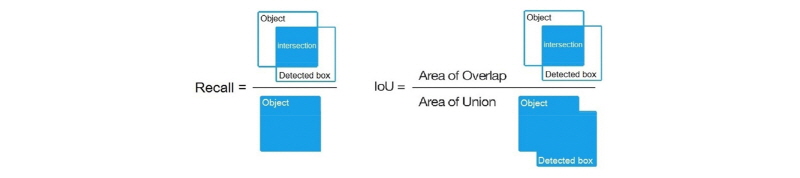
본 논문의 실험은 Intel I7 CPU, Windows 10 64bit OS, 32GB Ram 환경에서 진행되었다. 실험에 사용된 영상은 1920 × 1080 해상도이며 Ground Truth (이하 참값) 설정은 3개 영상(터널 초입부, 중반부, 출구부)에 대해 각각 1천 프레임씩을 직접 수작업으로 기록하였다. 오차 수치는 Fig. 4에서 정의된 Recall과 IoU를 기준으로 측정하였다. Recall이 높다는 것은 물체 영역을 잘 포함하고 있다는 것을 의미하며 IoU가 높다는 것은 물체 영역을 놓치지 않고 제대로 포함시켰음을 의미한다. 각 실험 모델로부터 도출된 결과 도표(Fig. 5 ~ Fig. 16)에서 파란색선은 최저값, 주황색선은 평균값, 노란색선은 최대값을 의미하며, 각 도표의 수평축은 프레임 번호, 수직축은 오차 수치를 의미하는 것으로 모든 도표가 공통적으로 적용된다. Fig. 5부터 Fig. 16까지는 순서대로 MHI-NMS 기반 모델의 IoU와 Recall값, HoG-NMS 기반 모델의 IoU와 Recall값 순서로 반복하여 도시하였고, 각 4장마다 터널 초입부, 중반부, 출구부의 실험 결과 오차 도표를 나타냈다. 실험 영상은 오전 9시경의 터널 영상을 기준으로 사용하였다. 여기서, 적용된 터널은 4차선 및 장대터널 환경이다.
4.1 실험 1 : 터널 입구 실험
4.1.1 MHI-NMS 기반 모델
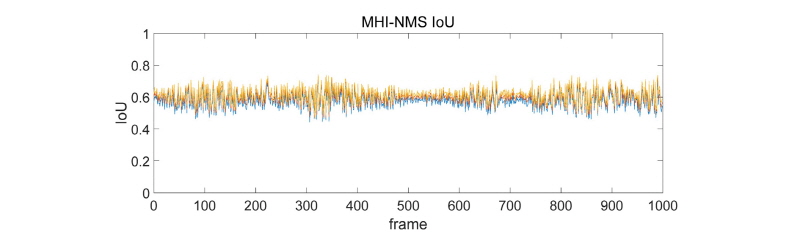
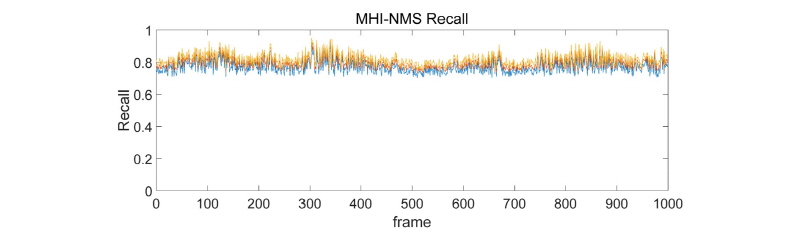
MHI를 기반으로 한 경우는 차량의 겹침 등의 현상이 발생하여 Recall은 유지되나, IoU가 낮게 떨어지는 문제점이 있었다. IoU는 50% 미만까지 하락하는 경우도 상당하였으며, Recall 또한 80% 이하로 떨어지는 경우가 다수로 차량을 탐지하기는 하나 정확한 위치를 대변한다고 할 수 없는 문제점을 보였다.
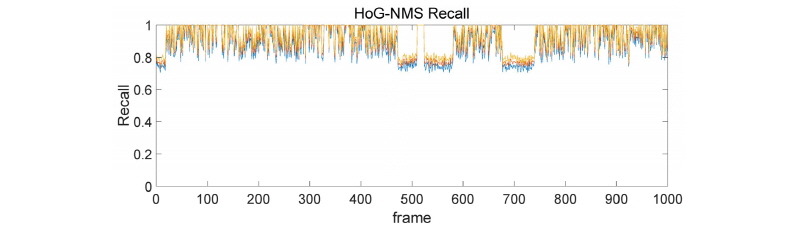
4.1.2 HoG-NMS 기반 모델
HoG를 기반으로 한 경우는 학습용 이미지를 크게 사용한 덕분에 Detection Box가 크게 잡혀 Recall이 항상 높게 나오는 특성을 보였다. 하지만 IoU가 적합하지 않게 나오는 문제점이 나타났다. 그리고 터널 초입부의 경우 급격한 빛의 변화로 인해 탐지 성능에서도 일부 문제가 있는 것으로 파악되었다.
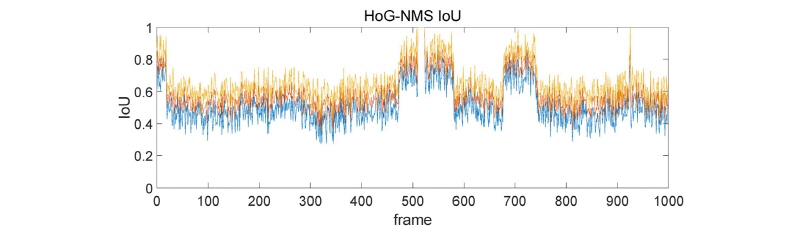
4.1.3 결과 분석
대체적으로 MHI기반 모델과 HoG 기반 모델, 모두 화면 내 차량의 숫자가 늘어날수록 탐지 능력이 점진적으로 떨어지는 결과를 확인할 수 있었다. 이는 NMS를 이용해 Bounding Box의 겹침을 추정하는 과정에서 나타난 것으로 보이며, 추적을 위한 연산을 실시간성을 고려하여 최대한 가벼운 연산으로 구성했기 때문에 발생하는 오차로 보인다. 이를 극복하기 위해서는 추적 관련 알고리즘의 개선이 필요할 것으로 보인다.
4.2 실험 2 : 터널 내부 실험
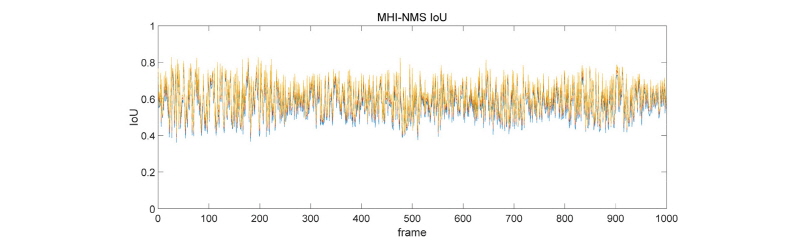
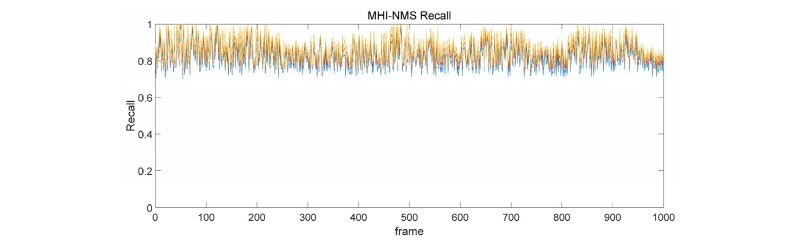
4.2.1 MHI-NMS 기반 모델
터널 내부에서는 조명의 변화가 일정하기 때문에 비교적 일정한 IoU와 Recall을 유지하는 것을 확인할 수 있다. 하지만 조명 변화가 크지 않았기 때문에 IoU와 Recall의 상하 폭은 커졌지만, Recall의 평균 수치가 터널 입구부에 비해 상당히 높음을 확인할 수 있었다. 또한 시간대의 특성 상 차량의 숫자가 일정하게 유지되었기 때문에 차량 숫자의 증감에 따른 효과는 확인하기 어렵다.
4.2.2 HoG-NMS 기반 모델
HoG의 경우는 IoU 수치가 낮아진 모습을 보이나 Recall은 높은 모습을 보인다. NMS로 인해 잘못 기각된 물체들이 있기 때문으로 보이며, Recall의 수치로 보아 전반적으로 반드시 탐지해내야 하는 차량 오브젝트들은 모두 측정이 되었다고 볼 수 있다. 하지만 IoU수치의 신뢰도로 인해 차량들의 위치를 정확히 대변한다고 확정 지을 수 없으며, 대략적인 위치와 진행 방향 정도만 확인할 수 있다고 볼 수 있다. 차량 숫자가 많았던 영상 초반부가 차량 숫자가 적었던 영상 후반부에 비해서 IoU가 낮음을 확인할 수 있다.
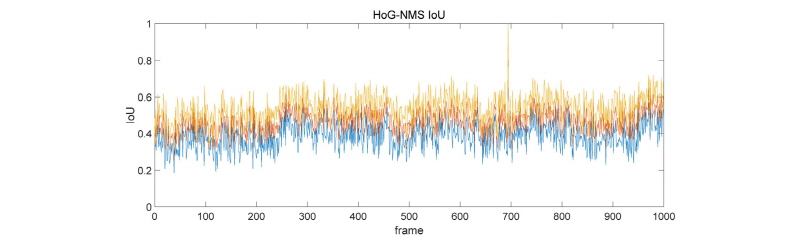
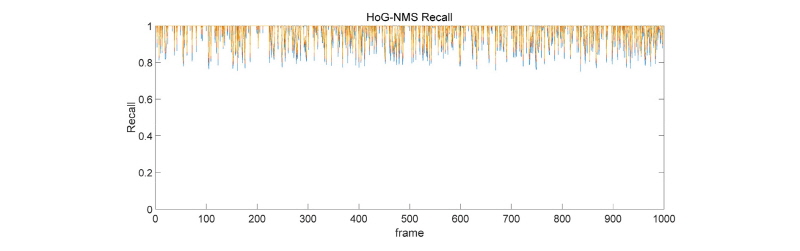
4.2.3 결과 분석
터널 중반부에서는 조명의 변화가 크지 않기 때문에 차량 탐지에 있어서 일관성 있는 탐지 결과를 확인할 수 있었다. 하지만 HoG-NMS 기반 모델의 경우는 어두운 터널 환경으로 인해 IoU가 급격히 떨어지는 문제점을 확인할 수 있었고, MHI-NMS 기반 모델은 상대적으로 HoG-NMS에 비해 탐지성능이 좋게 나타나는 특성을 보였다. 하지만 Recall 수치를 통해 두 방법의 장단이 명확히 갈림을 확인할 수 있다.
4.3 실험 3 : 터널 출구 실험
4.3.1 MHI-NMS 기반 모델
터널 출구부에서는 극단적으로 IoU와 Recall값이 큰 차이가 나고 있는 것을 확인할 수 있다. 터널 내부에서는 영상의 대비 설정 등이 모두 맞추어져 있기 때문에 터널을 나가면 차량이 잘 보이지도 않을뿐더러, 급격한 색상 변화로 인해 추적 모듈이 제대로 동작하지 못하여 발생하는 문제로 볼 수 있다. 상기 터널 초반부, 중반부 실험결과와는 대조적으로, 터널 출구부에서는 MHI-NMS 기반 모델을 사용하기 어려움을 알 수 있다. 또한 차량의 숫자가 매우 많은 상황에서는 MHI-NMS 기반 모델은 적절하지 못할 수 있음을 볼 수 있다. 이는 차량들이 겹쳐서 이동하면서 차량의 특징을 분리해내기 어렵기 때문이다.
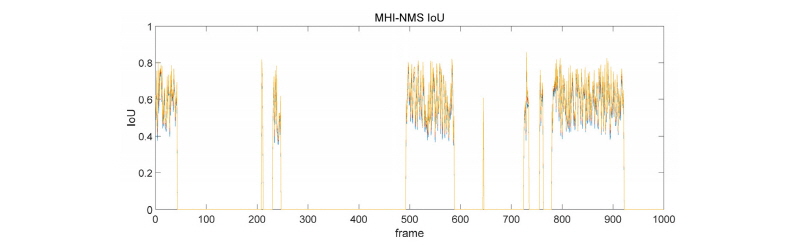
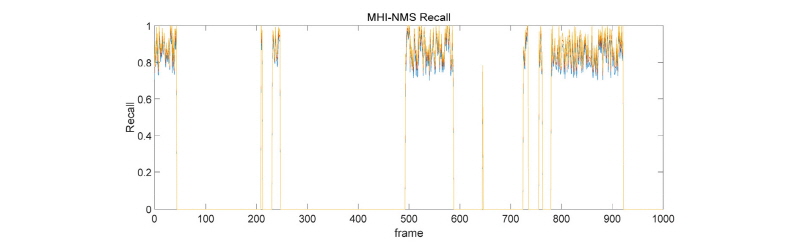
4.3.2 HoG-NMS 기반 모델
HoG 기반 모델은 IoU는 다른 실험에 비해 낮게 나오지만 Recall은 높게 나타났음을 확인할 수 있다. 또한 MHI-NMS 기반 모델의 경우 극단적으로 낮은 Recall과 IoU를 보이지만, HoG-NMS 기반 모델은 비록 수치는 좋지 않더라도 일정 수준 이상의 탐지능력을 일관성 있게 유지해주는 것을 확인할 수 있다.
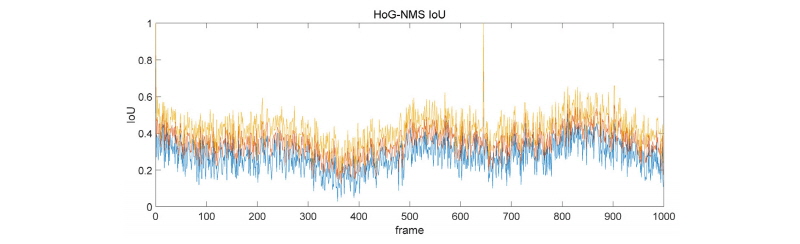
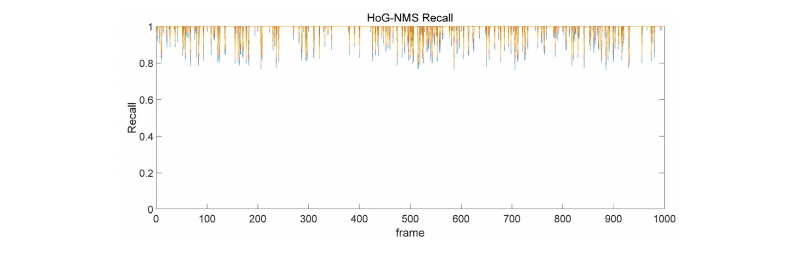
4.3.3 결과 분석
터널 출구부 구간에서는 급격한 조명 변화와 몰리는 차량들의 특성으로 인해 MHI-NMS 방법이 적용되기 어려움을 확인할 수 있었다. 극단적으로 IoU와 Recall이 0에 도달하는 프레임도 존재하였으며, 전반적으로 IoU와 Recall의 최대/최소 차가 지나치게 커지는 모습을 볼 수 있었다. 또한 차량이 10대가 넘어가면 탐지 조차 되지 않는 문제점도 발견되었다. 반면 HoG-NMS 기반 모델은 차량의 숫자가 많더라도 전혀 탐지가 되지 않는 문제는 없었으나, 여전히 IoU와 Recall에서 문제가 있음을 확인하였다. 이는 머신 러닝 기법에서도 영상 특징점을 표현하는 항목과 형식을 사전에 정의해 주어야 하기 때문이며, 이를 해결하기 위해서는 영상 특징점의 표현 형식과 항목을 사전에 정의하여 고정시키는 것이 아닌, 반복 학습시 마다 동적으로 변화시켜 나가는 딥러닝 기법을 도입해야 해결할 수 있을 것으로 판단된다.
5. 결 론
본 논문에서는 다양한 터널 환경내에서 확보한 CCTV영상자료를 대상으로, 영상처리 분야에서 일반적으로 적용되고 있는 차영상 기반의 MHI-NMS 방법과 머신 러닝 기반의 HoG-NMS 방법에 대한 영상처리 효과를 검토하였다. 이를 통해, 터널 내부 CCTV영상 내의 차량 대수가 늘어날수록 두 기법 모두 정확도가 급격하게 떨어지는 문제점이 발견되었으며, 특히, 차영상을 기반으로 한 방법은 차량 정체 시에는 거의 사용이 불가능할 수 있음을 확인하였다. 머신러닝 기반의 방법에서도 사용자가 직접 특징점을 표현하는 항목과 형식을 설계하고 추출하여야 하며, 영상 특징점 추출과 학습단계에서는 특징점 표현 형식이 고정되기 때문에, 급격한 조명 변화 등과 같은 사전 정의하기 어려운 조건에 대해서는 대응이 되지 않을 가능성도 매우 높음을 알 수 있었다.
따라서 이러한 문제점들을 해결하기 위하여 영상의 특징점을 표현하는 형식을 정의하고 추출하는 방법 또한 자동으로 구동되는 딥러닝 기반의 학습 기법을 도입할 필요가 있을 것으로 판단된다. 이를 기반으로, 추적 능력 및 이동 궤적 등 차량 별 다양한 이동 특성에 대한 추가 연구가 진행되어야, 매우 복잡하고 열악한 터널 내부 환경에서도 잘 작동될 수 있는 터널 영상유고 자동화 시스템이 개발될 수 있을 것으로 판단된다.
