

1. 서 론
2. 실험 방법
2.1 데이터셋 구성 및 딥러닝 모델 학습
2.2 기존 터널 영상 취득 시스템 데이터셋 가공
3. 학습 결과
3.1 데이터셋 구성 및 PSPNet 학습 결과
3.2 기존 터널 영상 취득 시스템 데이터셋 가공 결과
3.3 성능 평가 결과
4. 결 론
1. 서 론
터널과 지하시설물을 비롯한 콘크리트 토목구조물을 안전하게 이용하려면 정기적인 점검을 통해 균열이 발생했는지 알아내야 한다. 특히 터널 콘크리트 라이닝 표면에 발생한 균열의 위치와 형태를 검사하는 일은 주로 심야 시간에 한 개 차로를 차단한 후 고소작업차를 투입하여 이루어진다. 나머지 차로에서 차량이 여전히 통행 중일 때 작업을 수행하므로 관련 종사자가 다치거나 사망하는 일이 자주 일어난다. 또한, 매번 같은 종사자가 같은 터널의 같은 부위를 검사하기 어려우므로 균열 검사 결과의 일관성을 유지하기도 어렵다. 따라서 토목구조물에 발생한 균열을 차량이나 로봇에 장착한 영상 센서로 촬영하고, 최근 컴퓨터 비전 분야에서 각광받고 있는 딥러닝 기법을 적용하여 균열을 자동 탐지하는 연구가 많은 관심을 끌고 있어 여러 선행 연구가 이루어졌다.
Jung et al. (2019)은 균열 조사 업무의 객관성과 효율성을 높이기 위한 노력의 일환으로 영상정보에 기반한 균열 검출 자동화 프로세스를 제시하였다. 특히, 레이저 포인터를 활용하여 생성한 붉은 원 모양의 레퍼런스를 포함하는 균열 이미지 레퍼런스가 이미지 내에서 차지하는 픽셀의 영역과 균열이 차지하는 픽셀 영역의 비율을 비교하는 방식으로 균열의 크기 정보를 추출하였다. Kim et al. (2018)은 전체 영상에서 균열에 해당하는 픽셀의 비율이 1% 정도밖에 되지 않는 클래스 불균형 문제를 해결하고 균열 검출과 해당 균열의 특성을 얻기 위해 객체 분류와 의미론적 분할을 합한 두 가지 단계의 방법을 제안하였다. Lee et al. (2018)은 딥러닝을 이용하여 콘크리트 구조물을 촬영한 이미지에서 박락부를 탐지하기 위한 인공신경망을 개발하였으며, 웹스크래핑과 실제 콘크리트 교량에서 획득한 이미지들을 사용하여 그 성능을 검증하였다. Paik et al. (2021)은 균열과 비균열 형상을 단일적으로 나누기 위해 의미론적 분할 기술을 사용하였다. 임베디드 환경에서 네트워크의 성능과 연산의 속도가 높은 U-Net을 사용하여 드론으로 촬영한 영상에 대한 딥러닝 기반의 교량분석을 실시하였다. Kim and Cho (2019)는 슬라이딩 윈도 방식을 적용하여 균열을 탐지하고 이미지 처리 기술을 활용해 균열의 폭을 정량화하였다. 균열을 올바르게 탐지했음에도 같은 픽셀을 감지하지 못한 것에 대한 페널티가 크게 부과되고, 아주 작은 편차에도 민감하게 반응하는 기존 균열 검출 평가지표의 문제점을 해결하기 위해 균열의 특성을 반영한 정량지표가 필요하다. 균열 탐지의 주관성 문제를 해결하기 위해 상대적인 페널티를 부과하는 버퍼 생성을 통한 새로운 성능평가 방식을 제시하였다(Tsai and Chatterjee, 2017).
선행연구에서는 특정한 형태의 균열을 집중적으로 학습시키기보다 여러 형태의 광범위한 균열을 동시에 학습시키는 연구가 많았다. 딥러닝 기반으로 균열을 탐지하려면 잘 학습된 딥러닝 모델 뿐만 아니라 영상자료 취득, 처리, 분석, 저장, 가시화에 이르는 총체적인 시스템이 필요하다. 이러한 균열 탐지 시스템에 사용될 딥러닝 모델에는 광범위한 데이터보다는 자료 취득 부문의 특성과 유사한 데이터를 집중적으로 학습시키는 편이 훨씬 효율적일 것이다.
본 연구에서는 기존 터널 영상 취득 시스템에서 취득한 영상을 대상으로 딥러닝 기술을 적용하여 균열을 자동으로 탐지하는 연구를 수행한다. 의미론적 분할(semantic segmentation)을 수행하는 딥러닝 모델을 선정하고, 딥러닝 모델에 공개 데이터셋을 학습시키고, 기존 터널 영상 취득 시스템의 데이터셋을 이용하여 모델 성능을 평가한다. 특히 공개 데이터셋은 기존 터널 영상 취득 시스템의 데이터셋과 유사한 성격을 가진 것을 선별하여 학습시켰다. 기존 터널 영상 취득 시스템의 데이터셋을 딥러닝 모델이 입력시켜 성능 평가를 수행하기 위해 기존 터널 영상 취득 시스템 특성에 알맞는 데이터 전처리 방법을 설계하고 적용한다.
2. 실험 방법
2.1 데이터셋 구성 및 딥러닝 모델 학습
균열 영상 데이터를 학습시킬 의미론적 분할 딥러닝 모델로 PSPNet (Pyramid Scene Parsing Network; Zhao et al., 2017)을 선정하였다. PSPNet은 영상을 여러 가지 해상도로 변환한 결과의 집합인 영상 피라미드(image pyramid)를 내장하고 있어 크기가 다양한 여러 가지 대상을 잘 탐지할 수 있도록 설계된 모델이다.
PSPNet에는 대표적인 데이터 과학 플랫폼인 Kaggle에 공개된 Crack Segmentation Dataset (이하 캐글 데이터셋)을 학습시킨다(Middha, 2021). 캐글 데이터셋은 균열 영상과 그에 상응하는 라벨링 이미지가 쌍으로 포함되어 있으며 12가지 데이터셋을 병합하여 제작되었다. 12가지 데이터셋 중에서는 후술할 기존 터널 영상 취득 시스템의 데이터셋과 서로 관련성이 높은 데이터셋이 있고, 반면에 관련성이 낮은 데이터셋이 있다. 본 연구에서는 전체 데이터셋을 학습시켰을 경우와 관련성이 높은 데이터셋만 선택하여 학습시켰을 경우의 성능을 비교해보았다.
데이터 관련성에 따른 성능을 평가하기 위해 Fig. 1과 같이 실험을 설계했다. 데이터의 특성에 따라 학습 데이터를 3가지(Kaggle-original, Kaggle-relevant, Kaggle-relevant-noncrack)로 나누었다. Kaggle-original은 캐클 균열 모든 데이터셋, Kaggle-relevant은 캐글 모든 균열 데이터셋 중에 기존 터널 영상 취득 시스템의 데이터와 관련있는 데이터셋, Kaggle-relevant-noncrack은 Kaggle-relevant에 균열이 없는 데이터도 추가한 데이터셋을 나타낸다. 각 데이터로 학습하여 생성한 각각의 딥러닝 모델을 기존 터널 영상 취득 시스템의 데이터로 검증하였다.
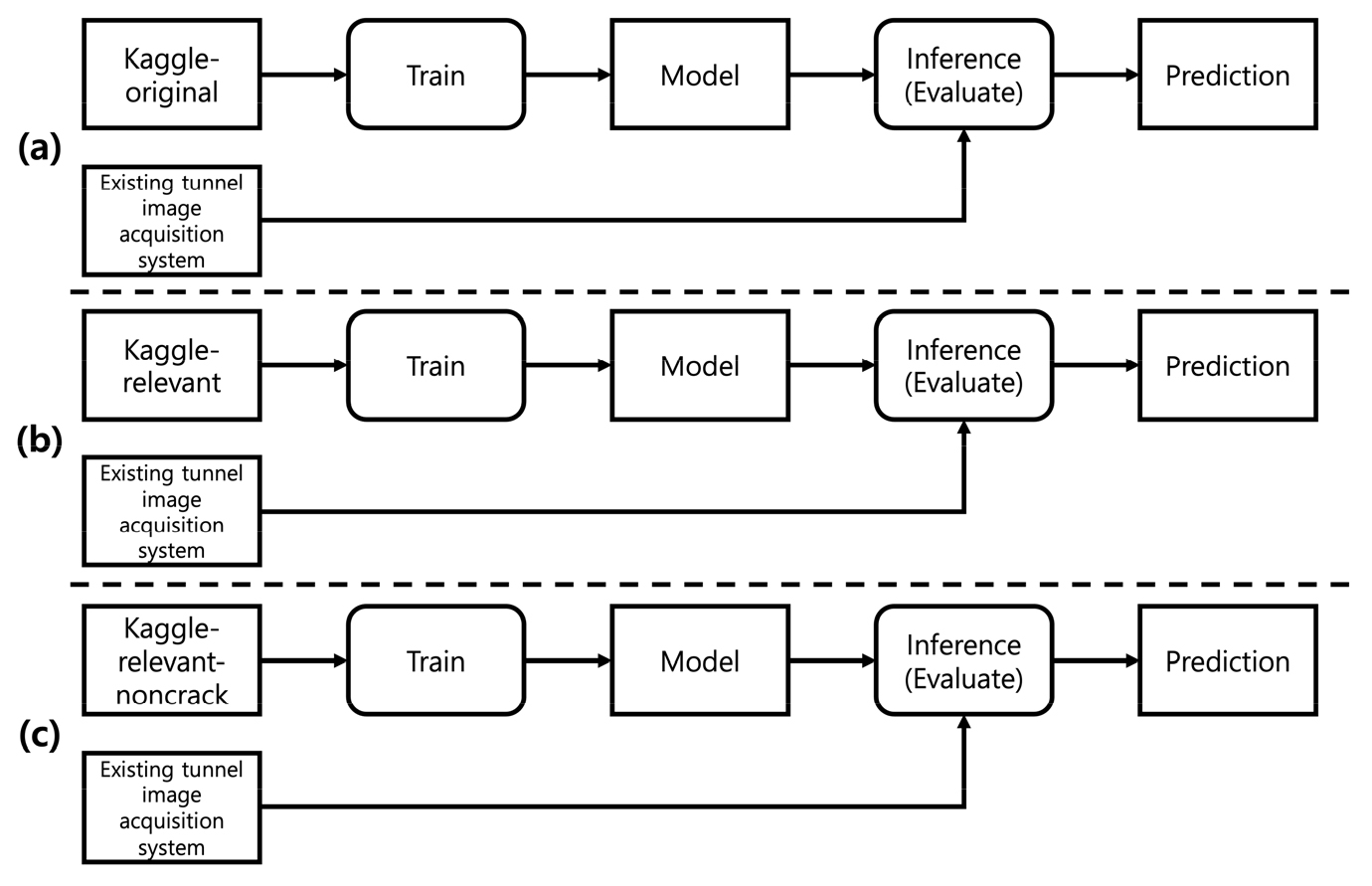
2.2 기존 터널 영상 취득 시스템 데이터셋 가공
기존 터널 영상 취득 시스템은 2.5 t급 트럭에 선형카메라, 조명, 연산장치를 장착한 터널 내 영상 취득 체계를 말한다. 기존 터널 영상 취득 시스템은 취득, 처리, 분석 과정으로 나누어 활용할 수 있다. 먼저 취득 과정에서는 터널의 각 차로별로 영상 취득을 실시한다. 선형카메라는 일반적인 센서 감광부가 면형으로 배열된 프레임 카메라와 달리 센서 감광부가 일렬로 배열되어 있어 차량 진행 방향에 따라 연속적으로 각 차로별로 영상을 취득한다.
다음으로는 처리 과정으로서 차로별 선형카메라 영상을 접합하고 콘크리트 라이닝 스판 단위로 나누어 관리한다. 각 차로마다 영상을 취득한 후에는 전용 소프트웨어를 이용하여 차로별 영상을 접합하고 콘크리트 라이닝 스판 단위로 구분하여 자체 포맷으로 저장한다. 이때 전용 소프트웨어에 터널의 제원을 입력하여 접합이 자동으로 이루어지도록 한다.
이렇게 제작한 스판별 터널 영상은 Fig. 2와 같은 특성을 나타낸다. 영상의 열(column) 방향은 터널 차로의 종방향이고, 행(row) 방향은 차로의 횡방향이다. 한 개 화소의 가로 및 세로 길이는 1 mm이다. 따라서 각 스판 영상은 1개 스판의 터널 종방향 길이가 10 m일 때 열 방향으로는 10,000 화소이다. 행 방향으로는 2차로 터널인 경우와 3차로 터널인 경우가 다르다. 2차로 터널인 경우 14 m이므로 14,000 화소이며 3차로 터널인 경우 19 m이므로 19,000 화소가 된다.

마지막으로 위와 같이 처리한 기존 터널 영상 취득 시스템의 데이터셋에서 균열 부위를 육안으로 찾아 선(polyline) 형태로 표시한다. 자체 소프트웨어에는 균열 탐지 기능이 포함되어 있으나 터널 내 시설물, 얼룩, 타일 경계 등을 균열로 오인하는 경우가 많아 실제 사용자의 만족도는 높지 않아 작업 시 참고용으로만 사용한다. 표시한 균열 부위 데이터는 외관망도로 작성하여 수요자에게 배포한다.
이와 같은 기존 터널 영상 취득 시스템의 특성을 고려해볼 때, 기존 터널 영상 취득 시스템에서 생산한 데이터를 딥러닝 분야에서 활용하려면 다음과 같은 사항을 고려해야 한다. 첫째, 현존하는 GPGPU 특성상 전체 스판 영상을 한꺼번에 학습시키거나 추론할 수 없으므로 작은 부분 영상으로(예를 들어 512 by 512 화소) 분할하여야 한다. 둘째, 자체 소프트웨어에 저장된 포맷은 다른 소프트웨어에서 읽어들이기 곤란하므로 균열 작성 자료와 스판 영상을 각각 CAD와 BMP로 출력하는 기능을 활용하여야 한다. 셋째, 벡터 형태의 CAD 자료와 래스터 형태의 BMP 자료를 동시에 활용하려면 벡터 자료와 래스터 자료를 처리하고 분석하는 기능이 풍부한 GIS 패키지를 응용할 필요가 있다.
따라서 본 연구에서는 Fig. 3과 같이 상호정합(co-registration), 격자화(rasterization), 클리핑(clipping)으로 이루어진 기존 터널 영상 취득 시스템 자료의 가공 프로세스를 제안한다. 상호정합 과정은 스판 영상과 CAD 자료의 축척과 원점좌표를 일치시켜 같은 화소가 같은 위치를 표현하도록 하는 작업이다. CAD 파일에 나타난 스판 경계점 4개와 그에 상응하는 스판 영상의 각 경계점을 공액점(tie-point)으로 지정하고 원점이동 및 축척변환계수를 추정한다. 딥러닝 모델에는 벡터 자료를 입력할 수 없으므로 벡터 형태인 CAD 자료를 격자화하여 래스터 형태로 변환한다. 균열에 해당하는 위치의 화소값이 1, 그렇지 않은 위치의 화소값은 0이 되도록 한다. 마지막으로 클리핑 과정은 스판 영상과 격자화한 균열 자료를 512 by 512 크기의 부분 영상으로 분할하는 과정을 말한다. 이때 분할한 스판 영상과 격자 영상이 서로 연관(association)될 수 있도록 별도 폴더에 같은 파일명으로 저장한다.
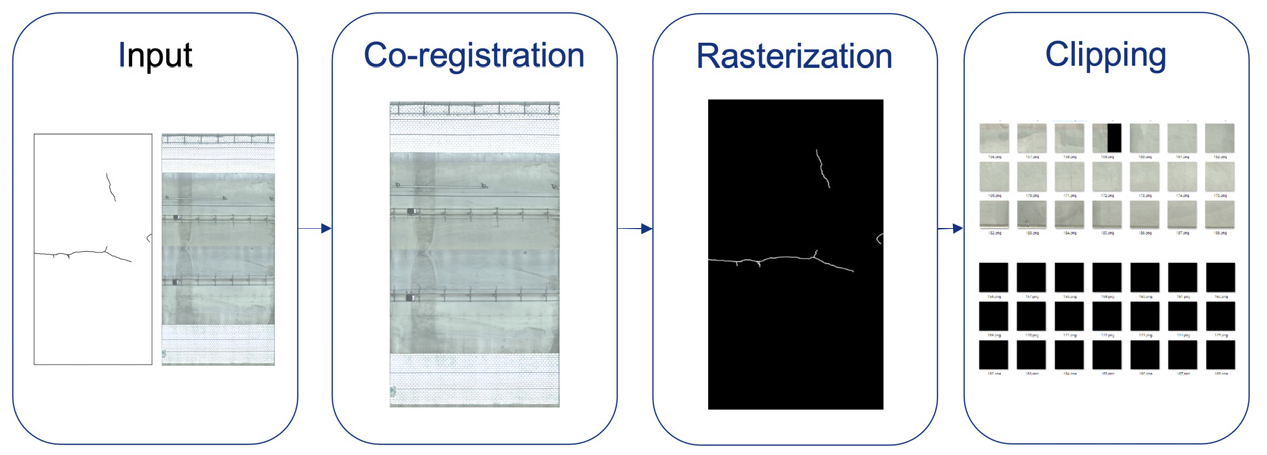
3. 학습 결과
3.1 데이터셋 구성 및 PSPNet 학습 결과
PSPNet을 학습시키기 전에 먼저 캐글 데이터셋의 세부 구성을 분석하였다. 캐글 데이터셋은 12종의 부분 데이터셋으로 이루어져 있으며 세부 데이터셋에 따라 관련성을 분석하였다. 기존 터널 영상 취득 시스템의 영상은 매끈한 콘크리트 표면으로 이루어져 있어 골재가 섞인 아스팔트 표면 등은 관련성이 떨어지는 것으로 간주하였다. 그 결과 Table 1과 같이 부분 데이터셋별로 관련성을 파악할 수 있었으며 Table 2와 같이 3가지 구성으로 학습시킬 준비를 하였다.
Table 1.
Sub-datasets and their relevance to the Big Eye imagery
Table 2.
Re-organized Kaggle dataset
PSPNet을 학습시키기 위하여 PyTorch를 이용해 의미론적 분할 모델을 학습시킬 수 있는 MMSegmentation을 이용하였다. 구체적으로는 특징 추출을 위한 백본(backbone)으로 Resnet-50을 사용했으며, Adam 최적화기로 학습을 수행하였고, 학습률(learning rate)은 일정 에포크(epoch)마다 감소하도록 하여 초반에는 빠르게 학습하고 후반에는 미세조정이 가능토록 하였다. 학습 중에는 무작위로 상하좌우 방향 뒤집기(flip)를 수행토록 하여 학습 데이터 양을 2배 증강하도록 하였다. 이러한 조건 하에서 학습은 10 epoch 진행하였다.
3.2 기존 터널 영상 취득 시스템 데이터셋 가공 결과
제안하는 방법으로 기존 터널 영상 취득 시스템의 데이터셋을 가공한 결과 5개 스판 영상으로부터 총 2,160개의 이미지-라벨링 쌍을 구축할 수 있었다. 가공 결과의 예시는 Fig. 4와 같다. 균열 작성 CAD 자료의 특성상 전체 프로세스를 자동화할 수는 없었고 일부 수작업이 개입되어야 했다. CAD 자료는 균열 뿐 만 아니라 각 스판의 경계까지 포함되어 있다. 따라서 격자화하는 과정에서 스판 경계는 제외하도록 설정하는 과정이 필요했고, CAD 자료는 그 특성상 기하적인 객체에 속성이 포함되지 않아 이 과정을 자동화하기 어려웠다. 또한, 상호정합 과정에서도 공액점 4개를 수동으로 선택하여야 했다. 향후 기존 터널 영상 취득 시스템의 데이터셋을 대량으로 가공하려면 자동화가 필수적이다.

한편, 격자화하여 생성한 라벨링 자료에서 균열의 폭은 1 화소로 표현된다. CAD 자료는 polyline으로 구성되므로 균열의 폭과 관계없이 1 화소로 표현될 수밖에 없는데, 실제 균열 폭을 적절히 반영하기 위하여 형태학적 연산(morphological operation)의 일종인 팽창(dilation)을 적용하여 균열 폭을 두껍게 바꿔주었다.
3.3 성능 평가 결과
학습된 PSPNet을 기존 터널 영상 취득 시스템의의 데이터셋을 이용하여 평가한 결과 Table 3과 같은 평가 결과를 얻을 수 있었다. Test mIoU는 캐글 데이터셋에서 관련 있는 것과 noncrack을 선택하여 학습시켰을 때가 가장 높았으며, 관련 있는 것만 선택했을 때와 전부를 학습시켰을 때가 그 뒤를 잇는다. 학습된 모델로 기존 터널 영상 취득 시스템의 데이터셋을 실제 추론한 결과는 Fig. 5와 같다. 캐글 데이터셋에서 관련 있는 것과 noncrack을 학습시킨 경우 균열 탐지 결과가 가장 정확한 것을 확인할 수 있다.

4. 결 론
본 연구에서는 터널과 지하시설물 등 콘크리트 토목구조물에서 발견할 수 있는 균열을 영상 기반으로 자동 탐지하기 위한 방법을 제시하였다. 영상 기반으로 균열을 탐지하는 업무는 영상 취득, 처리, 분석, 가시화 등 총체적인 업무 프로세스와 하드웨어/소프트웨어 시스템 상에서 이루어진다. 따라서 본 연구에서는 딥러닝을 적용하려면 범용적인 공개 데이터셋을 전부 학습시키는 대신 대상 시스템의 특성에 적합한 데이터셋을 선택하여 학습시키는 편이 더 효율적인지 확인하고자 하였다. 그 결과 본 연구에서 연구 대상으로 설정한 시스템이 기존 터널 영상 취득 시스템이 취득하는 자료와 유사한 질감을 가지는 영상, 그리고 균열이 없는(noncrack) 영상을 함께 학습시켰을 때 가장 효율적으로 좋은 성능을 획득할 수 있었다. 향후 공개 범용 데이터셋 뿐만 아니라 빅 아이 등 대상 시스템으로 취득한 자료를 이용해 전이학습(transfer learning)을 수행하면 더 좋은 결과를 얻을 수 있을 것이다.
