

1. 서 론
2. 제안 기법
2.1 FCN (fully convolutional networks)
2.2 Deeplab V3+
2.3 하이브리드 손실 함수
2.4 평가 지표
3. 예측 모델 구성
4. 결과 및 분석
5. 결 론
1. 서 론
터널 세그먼트 라이닝 배면의 뒤채움 그라우트는 터널의 구조적 안정성과 장기적인 유지관리에 중요한 역할을 한다. 그러나 환경 요인, 시공 결함, 유지관리 미흡 등으로 인해 뒤채움 그라우트에 결함이 발생할 수 있으며, 이는 라이닝 부식, 지반 침하, 편심 하중 등과 같은 중대한 구조적 문제를 유발할 수 있다(Meguid and Dang, 2009; Wang et al., 2014). 이러한 문제를 예방하기 위한 뒤채움 그라우트 상태 평가는 다양한 비파괴 탐사 기법을 통해 수행될 수 있다. 이 중 지표투과 레이더(ground penetrating radar, GPR)는 넓은 영역을 신속하고 연속적으로 조사할 수 있다는 점에서 터널 검사에 자주 활용된다. 그러나 쉴드 TBM 터널에서는 세그먼트 라이닝에 삽입된 보강용 철근에서 발생하는 강한 전자기파 반사로 인해 클러터가 발생하는 한계가 있다. 이러한 클러터는 뒤채움 그라우트 내 결함에 따른 신호를 가리게 되어 신뢰성 있는 상태 평가를 어렵게 한다.
GPR 클러터 문제 해결을 위해 다양한 제거 기법이 제안되어 왔다. Li et al. (2015)은 완전 앙상블 경험적 모드 분해 기법을 도입하여 클러터를 억제하고 목표 신호를 효과적으로 추출함으로써, 광산 탐사와 같은 얕은 지반 환경에서 높은 효용성을 입증하였다. Terrasse et al. (2017)은 커브렛 필터링을 활용하여 클러터 제거 과정을 단순화하고 기법의 실용성을 향상시켰다. Zhou and Chen (2019)은 디지털 정보 이동과 형태학적 성분 분석을 결합하여 목표 신호를 클러터로부터 효과적으로 분리함으로써 결함 식별 성능을 크게 향상시켰다.
본 연구에서는 GPR 클러터를 제거하고 세그먼트 라이닝 배면의 뒤채움 그라우트 상태를 평가하기 위한 딥러닝 기반 이미지 처리 모델을 제안하였다. 제안된 모델은 철근 클러터를 효과적으로 제거하여 뒤채움 그라우트 내 결함의 식별 성능을 향상시켰다. 이를 위해 FCN (fully convolutional networks)과 Deeplab V3+를 포함한 이미지 분할 기법을 적용하였고, 정성적·정량적 성능 평가를 통해 모델의 정확성을 검증하였다.
2. 제안 기법
2.1 FCN (fully convolutional networks)
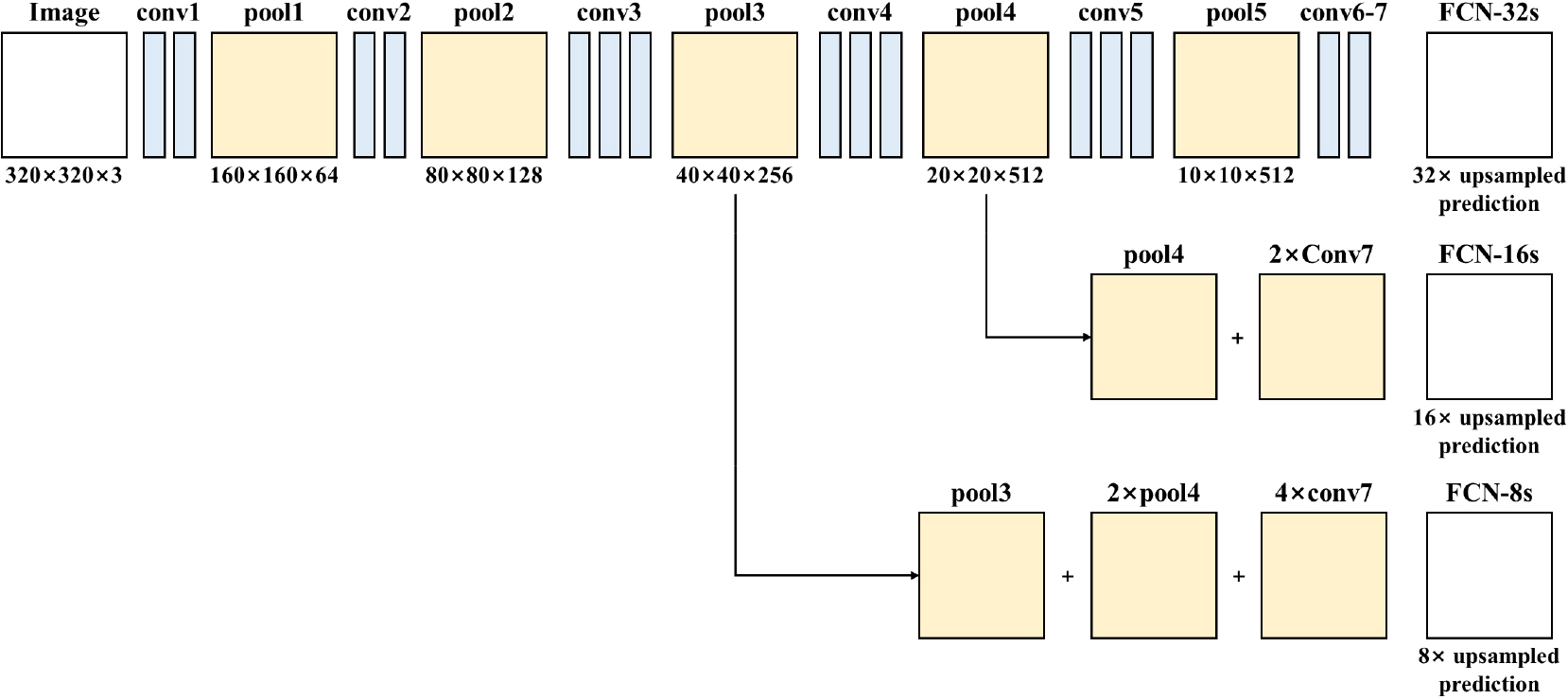
FCN (Long et al., 2015)은 딥러닝 기반의 대표적인 이미지 분할 기법으로, 이후 제안된 많은 최신 이미지 분할 기법들의 기반이 되었다. FCN은 기존 분류기에 사용되던 완전연결층을 1 × 1 합성곱으로 치환하여 임의 크기의 입력 이미지에 대해 픽셀 단위의 클래스 점수 맵(score map)을 산출하는 완전 합성곱 구조를 갖는다. 이로 인해 입력 이미지 크기에 제약을 받지 않고 분할 작업을 수행할 수 있으며, 업샘플링(upsampling) 과정을 통해 원본 해상도를 복원할 수 있다. 또한 FCN은 skip connection을 활용하여 얕은 층의 저수준 공간 정보를 상위 층의 정보와 융합한다. 이는 얕은 층의 점수 맵을 1 × 1 합성곱으로 변환한 뒤, 상위 층의 업샘플링된 점수 맵과 요소별 합으로 결합함으로써 보다 정밀한 객체 경계 추출이 가능하다. 이러한 특성은 객체 주변에 노이즈가 존재하거나 배경이 복잡한 경우에도 안정적인 분할 성능을 제공한다. 본 연구에서 사용한 FCN의 전체 구조는 Fig. 1에 제시하였다.
2.2 Deeplab V3+
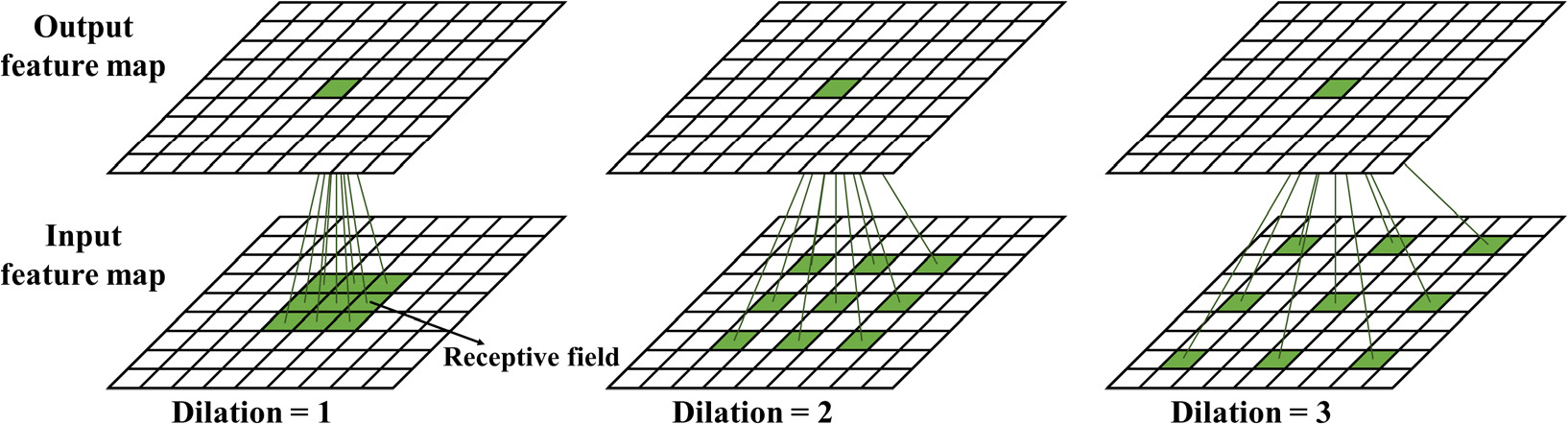
Deeplab 시리즈는 구글이 제안한 대표적인 이미지 분할 모델로, Atrous Convolution을 활용하여 다양한 크기의 객체를 픽셀 단위로 정밀하게 분할한다. Atrous Convolution은 합성곱 신경망의 수용 영역(receptive field)을 확장하여 해상도를 유지하면서 더 넓은 문맥 정보를 활용할 수 있도록 한다. 여기서 수용 영역은 출력 픽셀을 결정하는 입력 영역의 공간 크기를 의미하며, 일반적으로 필터의 크기와 동일한 값을 갖는다. Fig. 2에 나타낸 바와 같이, 수용 영역의 크기는 확장 비율(dilation rate)을 조정하여 변경할 수 있다.
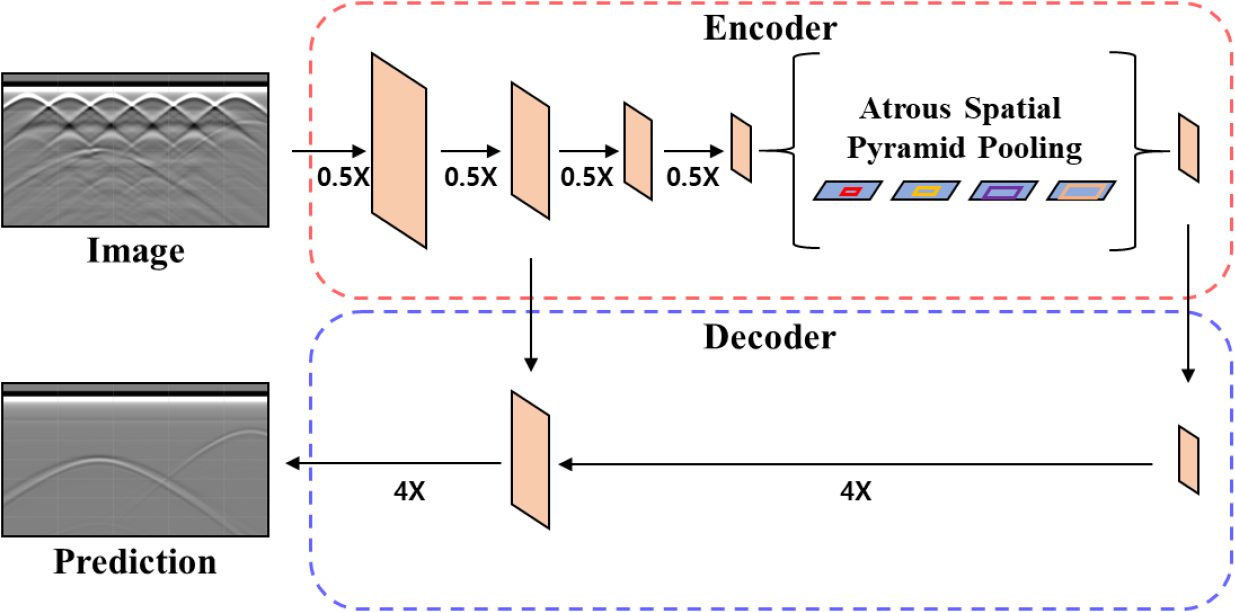
최신 버전인 Deeplab V3+는 Fig. 3과 같이 인코더-디코더 구조를 도입하여 분할 성능을 크게 향상시켰다. 인코더 단계에서는 Atrous Convolution의 확장 비율을 각각 다르게 병렬로 적용하고 다시 결합하는 ASPP (atrous spatial pyramid pooling)를 적용하며, 디코더 단계에서는 이차원 선형 보간(bilinear interpolation)을 통해 16배 업샘플링을 수행하고 skip connection을 통해 해상도를 보존한다.
2.3 하이브리드 손실 함수
손실 함수는 모델의 예측값과 실제값 간의 차이를 측정하여, 학습 과정에서 이 차이를 최소화하도록 최적화한다. 손실 함수의 선택은 모델 성능에 직접적인 영향을 미치므로, 적절한 함수를 활용하는 것이 중요하다. 그러나 개별 손실 함수는 각각 고유한 한계점을 갖고 있으며, 이를 보완하기 위해 여러 손실 함수를 결합한 하이브리드 손실 함수를 활용할 수 있다.
본 연구에서는 SSIM (structure similarity index measure)과 손실을 결합한 하이브리드 손실 함수를 적용하였다. SSIM은 명도(luminance), 대비(contrast), 구조(structure)의 세 요소를 바탕으로 두 이미지의 유사도를 평가하는 지표로, 인간의 시각적 인지 특성을 반영한다(Wang et al., 2003). SSIM은 식 (1), (2), (3), (4)와 같이 정의된다.
여기서, 두 이미지를 각각 , 라 할 때, 식 (1)은 SSIM의 기본 정의이며, , , 는 이미지 간 명도, 대비, 구조 비교 함수에 해당한다. 식 (2), (3), (4)에서 , 는 평균 픽셀 값, , 는 표준편차, 는 공분산을 나타낸다. 또한, , , 은 분모가 0에 가까워지는 것을 방지하기 위한 상수로, , , 로 각각 정의되며, 일반적으로 =0.01, =0.03, =255 (픽셀 값의 범위)로 설정한다.
따라서, SSIM은 다음 식 (5)와 같이 정리할 수 있다.
SSIM 지표는 그 값이 1에 가까울수록 두 이미지 간의 유사도가 높음을 의미한다. 따라서 SSIM을 손실 함수로 활용하기 위해서는 다음 식 (6)과 같이 적용할 수 있다.
한편, 손실은 평균 절대 오차(mean absolute error, MAE)에 기반한 지표로, 실제 픽셀 값과 예측된 픽셀 값 간 차이의 평균을 계산한다. 손실은 다음 식 (7)과 같이 정의된다.
여기서, , 은 각각 이미지 , 내의 위치 (, )에서의 픽셀 값을 의미하고, 와 는 이미지의 높이와 너비를 픽셀로 나타낸 값이다.
이에 따라, 본 연구에서 두 손실 함수의 장점을 결합하는 하이브리드 손실 함수를 다음 식 (8)과 같이 정의하였다.
여기서, 𝛼=0.5를 적용하여 SSIM과 손실에 동일한 가중치를 부여함으로써, 구조적 유사도와 픽셀 단위 오차를 동시에 고려할 수 있도록 하였다.
2.4 평가 지표
클러터 제거 모델의 정량적 성능 평가를 위해 SSIM, MS-SSIM (multi-scale SSIM), 그리고 PSNR (peak signal-to-noise ratio)의 세 가지 평가 지표를 적용하였다. MS-SSIM은 여러 스케일에서 산출된 SSIM 값의 가중치를 활용하여 이미지 유사도를 종합적으로 평가할 수 있는 지표로, 전체 스케일의 수를 이라 할 때 식 (9)와 같이 정의된다.
PSNR은 모델이 생성한 출력 이미지의 품질 손실을 객관적으로 평가하는 지표이다. 이 지표는 데시벨(dB) 단위로 표현되며, 식 (10)과 같이 계산된다.
여기서, 는 이미지가 가질 수 있는 최대 픽셀 값을 의미하며, 는 실제 이미지와 예측 이미지 간의 평균 제곱 오차를 의미한다.
3. 예측 모델 구성
쉴드 TBM 세그먼트 라이닝의 뒤채움 그라우트 내 결함을 모사한 GPR 이미지 데이터셋을 구축하기 위해 수치해석 모델을 개발하였다. GPR 수치해석은 Maxwell 방정식에 대한 Python 기반 유한차분 시간 영역(finite-difference time-domain, FDTD) 해석 프로그램인 gprMax를 사용하여 수행하였다(Warren et al., 2016). 해석 영역 두께 200 mm의 콘크리트 세그먼트와 두께 500 mm의 뒤채움 그라우트를 포함하도록 총 2,000 mm × 740 mm로 설정하였다.
클러터 제거 모델의 범용성과 성능 향상을 위해, 다양한 패턴을 반영한 학습 데이터셋을 구축하였다. 이를 위해 세그먼트 라이닝 내 철근의 위치 및 간격, 뒤채움 그라우트 내 결함의 개수, 형상, 크기, 위치를 무작위로 설정하였다. FDTD 모델의 세부 기하학적 요소는 Table 1에 정리하였다.
Table 1.
Geometric components of the numerical model
| Type | Component | Value |
| Cavity | Number | 1, 2, 3 |
| Size (mm)* | 40, 80, 120 | |
| Shape | Sphere, Cube | |
| Rebar | Spacing (mm) | 300, 400, 500 |
| Number of layers | Single, Double |
Table 2에는 수치해석 모델에 적용된 각 재료의 전자기적 특성을 정리하였다(Go and Lee, 2021; Zeng et al., 2023). GPR 안테나는 중심 주파수 750 MHz의 가우시안 형태 펄스를 방출하도록 설정하였으며, 수치해석 모델의 step size는 2 mm, time window는 20 ns로 적용하였다.
Table 2.
Electromagnetic parameters of materials
| Material | Relative permittivity | Conductivity (mS/m) |
| Concrete | 6.5 | 0.1 |
| Rebar | ∞ | ∞ |
| Backfill grout | 12 | 5 |
| Air | 1 | 0 |
철근 클러터 제거 모델의 학습용 데이터셋은 GPR 수치해석으로 획득한 이미지만으로 구축하였으며, 총 1,162개의 입력(input)과 정답(ground truth) 데이터 쌍으로 구성되었다. 입력 데이터는 철근 및 공동으로 인한 반사가 모두 포함된 이미지를 사용하였고, 정답 데이터는 철근에 의한 간섭은 제외되고 공동 반사만을 나타내는 이미지를 활용하였다. 전체 데이터셋은 학습(training), 검증(validation), 테스트(testing) 세트로 각각 5:1:1의 비율로 분할하였다. 제안된 모델은 PyTorch 프레임워크 기반으로 구현하였으며, 최적화 알고리즘으로 Adam (adaptive moment estimation)을 적용하였다. 1차 및 2차 모멘트의 감쇠계수 , 는 통상적으로 사용되는 기본값으로 설정하였고, 수치적 안정성을 확보하기 위해 𝜖은 0이 아닌 충분히 작은 값으로 두었다(Kingma and Ba, 2014; Ruder, 2016). 또한, 학습에 소요되는 메모리와 연산 효율을 고려하여 배치 크기(batch size)와 에폭(epoch)을 적정 수준으로 결정하였다. 구체적인 학습 파라미터 설정은 Table 3에 제시하였다.
4. 결과 및 분석
학습된 클러터 제거 모델들의 성능 비교를 위해 우선 재구성된 GPR 이미지에 대한 정성적 평가를 수행하였다. Fig. 4는 모델 간 비교에 사용된 테스트 이미지의 기하학적 구조를 나타내며, 라이닝 세그먼트 내부 철근은 400 mm 간격으로 배치하였고 뒤채움 그라우트 내에는 공동 결함이 존재하는 경우를 가정하였다. 원본 GPR 이미지는 Fig. 5에 나타낸 바와 같이 결함으로 인한 반사 신호가 철근에 의해 발생한 클러터에 가려져, 육안으로 명확히 식별하기 어려운 상태임이 확인되었다.
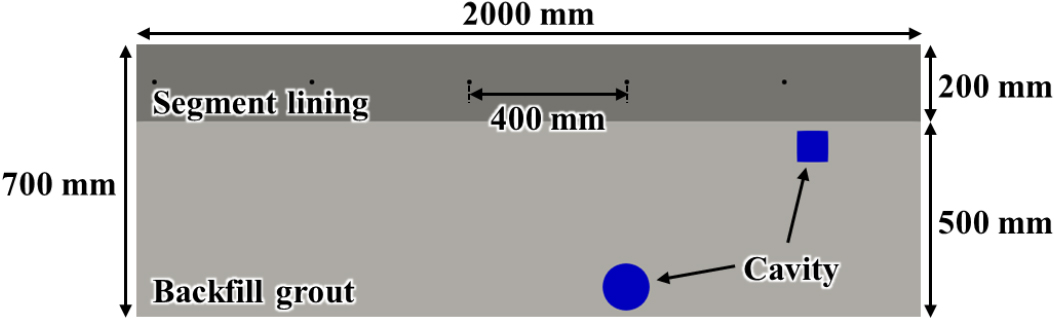
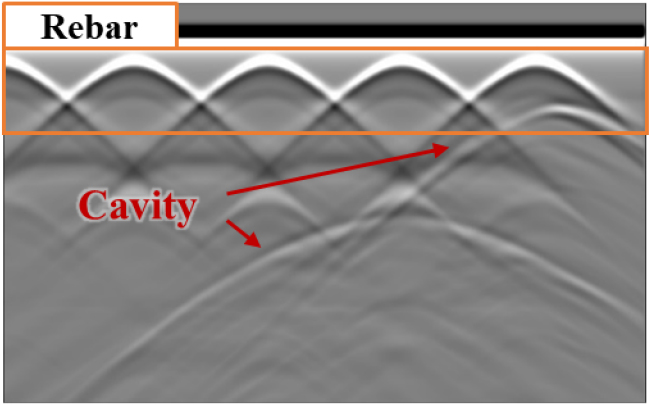
Fig. 6에는 각각 FCN과 Deeplab V3+ 모델로부터 얻은 클러터 제거 결과를 제시하였다. Fig. 6(a)의 FCN 결과는 대부분의 클러터를 제거하였으나, 재구성된 이미지의 해상도가 낮고 결함 신호의 선명도가 상대적으로 저하되었다. 이러한 현상은 두 결함 신호가 교차하는 지점에서 특히 두드러지게 나타났다. 반면, Fig. 6(b)의 Deeplab V3+ 결과는 클러터를 효과적으로 제거하면서도 원본에 가까운 해상도를 유지하였다. 또한 결함 신호를 매끄럽게 재구성하여 교차 지점에서도 신호가 온전하게 보존되었다. 종합적으로, 정성적 비교 결과 Deeplab V3+가 클러터 제거와 결함 신호 재구성의 두 측면에서 FCN보다 우수한 성능을 보였다.

다음으로, 두 학습된 모델에 대한 정량적 성능 평가를 수행하였다. Table 4는 FCN과 Deeplab V3+의 세 가지 지표(SSIM, MS-SSIM, PSNR)에 대한 비교 결과를 제시한다. SSIM과 MS-SSIM 지표에서 Deeplab V3+가 FCN보다 우수한 결과를 보였으며, 이는 이미지 간 구조적 유사도를 보다 정밀하게 보존하는 것으로 판단된다. PSNR 지표 역시 FCN보다 Deeplab V3+ 모델이 높은 예측 결과를 보이며, 클러터 억제와 신호 보존 측면에서 성능 우위를 입증하였다. 즉, Deeplab V3+ 모델이 모든 지표에서 FCN 모델보다 일관되게 우수한 성능을 보였다(SSIM = 0.9431, MS-SSIM = 0.9445, PSNR = 77.30 dB).
Table 4.
Quantitative assessment results of each clutter-elimination model
| Metric | FCN | Deeplab V3+ |
| SSIM | 0.9166 | 0.9431 |
| MS-SSIM | 0.8905 | 0.9445 |
| PSNR (dB) | 72.26 | 77.30 |
정성·정량 평가 결과, 본 연구에서 제안한 Deeplab V3+ 기반 모델이 GPR 이미지의 클러터 제거에서 우수한 성능을 보였으며, 이를 통해 기존 GPR의 한계를 보완하고 터널 세그먼트 라이닝 배면 결함의 식별 가능성을 실질적으로 향상시켰다. 다만, 제안된 모델은 수치해석 결과를 기반으로 구축되었으므로 일반화된 결론을 도출하는 데에 한계가 있다. 따라서 향후 연구에서는 실내 모형실험 및 실제 현장 자료를 활용하여 적용성과 일반화 성능을 검증하고, 최신 이미지 분할 기법과의 체계적 비교를 통해 모델을 고도화할 계획이다. 이를 통해 세그먼트 라이닝 유지관리의 정확성과 효율성을 높여, TBM 터널의 내구성 확보와 사용 수명 연장에 기여할 것으로 기대된다.
5. 결 론
본 연구에서는 세그먼트 라이닝 배면 뒤채움 그라우트 상태를 효과적으로 평가하기 위해 GPR 탐사와 머신러닝 기법을 결합한 철근 클러터 제거 모델을 제안하였다. 제안된 모델은 세그먼트 내 철근에 의해 발생하는 클러터를 효과적으로 제거하고, 뒤채움 그라우트 내 결함 신호를 선명하게 재구성함으로써 결함 탐지 정확도를 향상시켰다. 학습용 데이터셋은 FDTD 수치해석을 통해 생성된 GPR 이미지를 기반으로 구성하였으며, 두 가지 이미지 분할 기법을 적용해 학습을 수행하였다. 이후 정성적·정량적 성능 평가를 통해 최적의 클러터 제거 모델을 도출하였다. 본 연구의 주요 연구 결과는 다음과 같다.
1. 시각적인 분석을 통한 정성적 평가 결과, FCN 모델은 대부분의 철근 클러터를 제거하였으나 재구성된 GPR 이미지의 해상도와 결함 신호의 선명도가 저하되었다. 반면, Deeplab V3+ 모델은 클러터를 효과적으로 제거하는 동시에 원본 수준의 해상도를 유지하며 결함 신호를 선명하게 재구성하였다.
2. 세 가지 성능 지표(SSIM, MS-SSIM, PSNR)를 활용한 정량적 평가에서 Deeplab V3+ 모델은 클러터 억제와 구조적 유사도 보존 측면에서 FCN 모델보다 우수한 성능을 입증하였다. 이를 통해 Deeplab V3+가 GPR 철근 클러터 제거 및 뒤채움 그라우트 결함 탐지에 효과적으로 활용 가능함을 확인하였다.
3. 제안된 모델은 GPR 탐사에서 철근 클러터로 인한 한계를 극복하고 쉴드 TBM 세그먼트 라이닝 배면 뒤채움 그라우트 내 결함을 보다 정확하게 탐지할 수 있음을 보여주었다. 이러한 결과는 쉴드 TBM 터널 세그먼트 라이닝의 유지관리 효율성과 사용 수명 연장에 크게 기여할 것으로 기대된다.
