

1. 서 론
1.1 터널 건전성 관리 기술의 필요
1.2 학습 데이터의 증강을 위한 연구 동향
2. 균열 영상 데이터의 증강 기법
2.1 균열 데이터의 구성
2.2 Stable diffusion을 이용한 영상 데이터의 증강
2.3 학습 환경 구성
3. 결과 분석 및 논의
3.1 증강 영상의 결과 분석
3.2 증강된 영상 결과 비교 및 논의
3.3 균열 탐지 정확도 분석
4. 결 론
1. 서 론
1.1 터널 건전성 관리 기술의 필요
고해상도 카메라를 이용한 콘크리트 구조물의 건전성을 점검하는 기술은 인프라 유지관리 분야에서 널리 활용되고 있다(Lei et al., 2021). 이는 터널의 콘크리트 구조물에서도 예외가 아니다. 특히 터널 천장부에 가해지는 하중을 견디기 위해서는 정기적이고 지속적인 상태 점검이 필요하다. 현재 이러한 점검은 다년간의 경력을 가진 전문 점검자들의 육안 검사로 수행되고 있다(Lee et al., 2007; Lynch et al., 2016). 이들은 현장에 직접 방문하여 균열과 같은 손상의 종류와 상태를 직접 확인하는 절차를 거친다. 이러한 작업은 많은 시간과 비용이 소요될 뿐만 아니라, 점검자의 경험과 주관적인 판단에 크게 의존하는 경향이 있다(Phares et al., 2004). 따라서 이러한 전통적인 방법을 통한 상태 진단은 결과가 매번 달라질 수 있다. 예를 들어, 하나의 균열을 두고 측정하는 두께의 지점이 다를 경우 균열에 대한 평가 등급도 달라질 수 있다. 또한 균열은 주변의 잡음 패턴이 무수히 많고, 먼지에 의해 덮여 있어 쉽게 관찰되지 않을 수도 있다(Li et al., 2020). 더불어 인구 감소와 고령화로 인해 노후 인프라 점검을 위한 전문 작업자의 수가 줄어들고 있어, 전통적인 점검 방식을 대체하려는 수요가 증가하고 있다.
이러한 문제를 해결하기 위해 최근에는 딥러닝 기술을 접목한 균열 탐지 기술이 활발히 연구되고 있다(Munawar et al., 2021). 균열은 복잡한 배경에서 발생하는 미세한 객체다. 따라서 복잡한 배경으로부터 효과적으로 제거하기 위해 딥러닝 기술이 적용되며, 미세한 객체를 추출하기 위해 고해상도 카메라가 활용된다. 균열 탐지에 사용되는 신경망 모델의 방식에는 분류(classification), 객체 인식(object detection), 그리고 분할(segmentation) 방식이 있다. 최근 분할 방식을 활용하는 연구가 점차 증가하고 있다(Hsieh and Tsai, 2020). 균열 탐지의 최종 목적은 균열의 두께를 측정하는 것이며, 이들 방식 중 오직 분할 알고리즘만이 균열의 물리적 정보를 얻을 수 있다. 이러한 이유로 분할 알고리즘의 활용도가 높아지고 있다.
이러한 신경망 모델의 높은 성능을 보장하기 위해서는 다수의 훈련 데이터가 필수적이다. 그러나 다양한 훈련 영상을 확보하기 위해서는 시간과 비용이 많이 소요된다. 특히 터널 천장부의 균열을 촬영하기 위해서는 작업자가 터널을 직접 방문하고 차로를 점거해야 하기 때문에 위험성이 매우 높다. 또한 균열은 비정상적인 장면으로, 주변에서 흔히 발생하지 않아 촬영을 통해 데이터를 얻는 것이 어렵다(Shim, 2022). 이러한 문제를 해결하기 위해 생성형 AI를 통해 영상을 합성하는 연구가 진행되고 있다(Li and Zhao, 2023). 본 연구에서는 이러한 맥락에서 거대 AI 모델을 활용한 균열 영상 데이터 증강 방법을 제안하고자 한다.
1.2 학습 데이터의 증강을 위한 연구 동향
생성형 AI는 Generative Adversarial Network (GAN)에서 시작되었다(Goodfellow et al., 2014). GAN은 참 훈련과 거짓 훈련의 경쟁을 통해 새로운 영상을 합성하는 과정을 포함한다. 참 훈련은 원래의 훈련 데이터와 동일한 데이터를 합성하는 역할을 한다. 반면, 거짓 훈련은 훈련 데이터와 다른 데이터를 생성하는 기능을 갖는다. 이러한 두 훈련이 동시에 적용되어, 훈련 데이터와 유사하지만 다른 영상을 합성하는 것이 GAN의 특징이다. 이러한 GAN을 활용해 토목 분야에서 데이터 부족 문제를 해결하려는 연구가 다수 선행되었다. Zhang et al. (2020)은 순환적 일관성(cycle-consistency)을 이용해 균열 탐지용 데이터를 증강하였다. 이들은 균열 영상을 라벨 영상으로 변환하고, 다시 라벨 영상을 균열 영상으로 변환하는 순환 구조를 제안했다. 이때, 변환된 균열 영상이 원래의 균열 영상과 일치하도록 신경망 훈련 방법을 고안하였다. Maeda et al. (2021)은 도로 노면에서 발생하는 포트홀 영상의 부족 문제를 해결하기 위해 PG-GAN을 이용해 포트홀 영상을 합성하고, 이를 활용해 신경망 기반의 분류기 알고리즘을 제안했다. 하지만, 다수의 생성된 영상을 훈련에 포함하면 오히려 정확도가 감소하는 현상이 발생했다. 그러나 특정 수의 영상을 활용해 신경망을 훈련하면 인식 정확도가 향상되는 결과를 얻었다. Shim (2024)은 Pix2Pix 기반의 GAN 알고리즘을 통해 라벨 영상으로부터 균열 영상을 합성하는 방법을 제안했다. 이 연구에서는 GAN을 이용해 다양한 배경 영상을 합성하여 데이터 증강 효과를 얻었으며, 균열 영상이 생성되더라도 균열의 형상은 유지된다는 가정 하에 라벨 영상을 생성된 영상과 함께 자가 지도학습에 사용할 수 있도록 학습 구조를 설계하였다. 이를 통해 생성 영상을 활용한 분할 알고리즘 기반 균열 탐지 정확도 향상을 도모하였다. Huang et al. (2024)은 수중 구조물에서 발생하는 균열을 탐지하기 위해 CycleGAN을 적용하였다. 수중에서 데이터를 수집하는 데 많은 비용이 들기 때문에, 그들은 육상에서 촬영된 균열 영상을 수중에서 촬영된 균열 영상으로 변환하여 훈련에 활용하였다. 이 생성된 영상을 분할 알고리즘에 적용하여 수중 균열 탐지의 정확도를 향상시켰다.
이러한 생성 알고리즘은 데이터 증강 분야에서 부족한 영상 데이터로 인해 발생하는 문제를 해결하는 방법으로 활용되고 있다. 이러한 맥락에서 최근에는 문자열을 활용한 영상 생성 알고리즘이 소개되었으며, 생성 품질이 크게 향상되었다(Rombach et al., 2022). 본 연구에서는 이러한 생성 알고리즘을 통해 기존의 균열 데이터 세트로부터 다양한 균열 영상을 합성하는 방법을 제안하였다. 특히, 가장 현실적인 영상 합성을 위해 필요한 파라미터와 모델 선정 방법을 제시하여 새로운 데이터 증강 기법을 개발하였다.
2. 균열 영상 데이터의 증강 기법
2.1 균열 데이터의 구성
본 논문에서 사용하는 영상 데이터는 선행 연구에서 공개된 콘크리트 균열 영상과 도로 균열 영상을 사용하였다(Bianchi and Hebdon, 2021). 이들의 영상은 모두 448 × 448이고 총 수량은 10,955장이다. 이 영상들은 아스팔트와 콘크리트에서 발생한 균열 영상과 손상이 없는 정상 영상들이다. 이 영상들 중에서 본 논문에서는 사용한 콘크리트 영상은 Fig. 1과 같다. 이들의 공통점은 균열을 촬영하였다는 점이며, 차이점은 다양한 색상과 형상을 띠고 있다는 점이다. 서로 다른 환경과 장소에서 발생한 균열로 재질과 변질의 정도가 다르게 나타난다. 본 연구는 터널 내부에서 관찰될 수 있는 균열을 대상으로 하고 있으므로, 아스팔트 균열 영상은 제외하였다. 또한, 콘크리트 균열이 선명하게 포함된 영상을 선별하여 데이터 세트로 활용하였다. 그 결과, 총 3,421장의 영상을 생성 모델의 입력으로 사용하였다.

2.2 Stable diffusion을 이용한 영상 데이터의 증강
잠재적 확산 모델은 영상 생성 모델로서 기존의 화소 기반 생성 모델과 달리 잠재 공간 기반 확산 방식과 사전 학습된 자기부호화기를 사용한다. 이를 통해 적은 리소스로 학습과 추론이 가능하며, 문자열-영상 생성, 영상-영상 변환, 초해상도, 인페인팅 생성 등 다양한 활용이 가능하다(Rombach et al., 2022). 본 논문에서는 잠재적 확산 모델을 기반으로 학습된 stable diffusion 모델을 활용하여 균열 영상을 증강하는 방법을 제안하였다. 먼저, 영상 증강을 위해 사용할 가중치 파일로는 두 가지를 고려하였다: CompVis의 sd-v1-4와 StabilityAI의 sd-v2-1을 활용하였다. 또한, 두 모델의 가중치를 합쳐 또 다른 가중치 파일을 생성하였다. 가중치 파일을 합치는 방법은 checkpoint merger로, 서로 다른 버전의 모델에 있는 가중치를 결합하여 새로운 결과를 낼 수 있는 모델을 만드는 방식이다. 이때 가중치를 합하는 비율은 0.5:0.5로 설정하였다. 이 방법의 장점은 별도의 추가 학습이 없어도 상호 보완적인 모델을 얻을 수 있다는 점이다.
Stable diffusion 모델의 원리를 살펴보면, 우선 문자열 기반 영상 생성에서 임의의 잡음을 생성한다. 이때 사용하는 잡음은 표준정규분포 X~N (0, 1)로부터 발생한 난수를 사용하였다. 다음으로 프롬프트 내용을 가이던스로 삼아 잡음을 제거하여 영상을 생성한다. 따라서 이러한 원리에 의해, 임의의 잡음 대신 입력 영상에서 잡음 제어 연산을 수행하면 입력 영상과 유사하지만 다른 영상이 생성된다. Fig. 2에 나타난 것처럼, 입력된 화소 공간(pixel space)의 원본 영상은 암호화기(encoder)를 통해 잠재 공간으로 변환된다. 잠재 공간으로 변환된 영상은 잠재적 영상이 되며, 해당 영상에 잡음을 더하는 확산 연산 과정을 수행한다. 이러한 과정을 통해 잡음이 추가된 잠재적 영상이 생성되며, 이 추가된 잡음은 입력 영상과는 다른 영상을 합성하는 요인으로 작용하게 된다. 또한, 추가되는 잡음의 양에 따라 더욱 다양한 영상 생성이 가능하다. 이렇게 잡음이 추가된 잠재적 영상은 U-Net 기반의 잡음 제어(denoising) 과정을 거친다. 이때 사용자의 프롬프트를 기반으로 한 가이던스를 U-Net 기반 잡음 제어 과정에 함께 입력함으로써, 프롬프트에 따른 영상 생성이 가능해진다. 사용자가 입력하는 프롬프트 문장은 문자열 암호화기(text encoder)의 규칙에 따라 벡터 형식으로 변환된다. 이렇게 변환된 벡터 데이터는 잡음이 추가된 잠재적 영상과 함께 U-Net 기반의 잡음 제어 과정에 참여한다. 이러한 과정을 통해 얻어진 결과는 복호화기(decoder)를 통해 다시 화소 공간으로 변환되며, 최종적으로 균열 영상 형태로 생성된 결과를 확인할 수 있다.
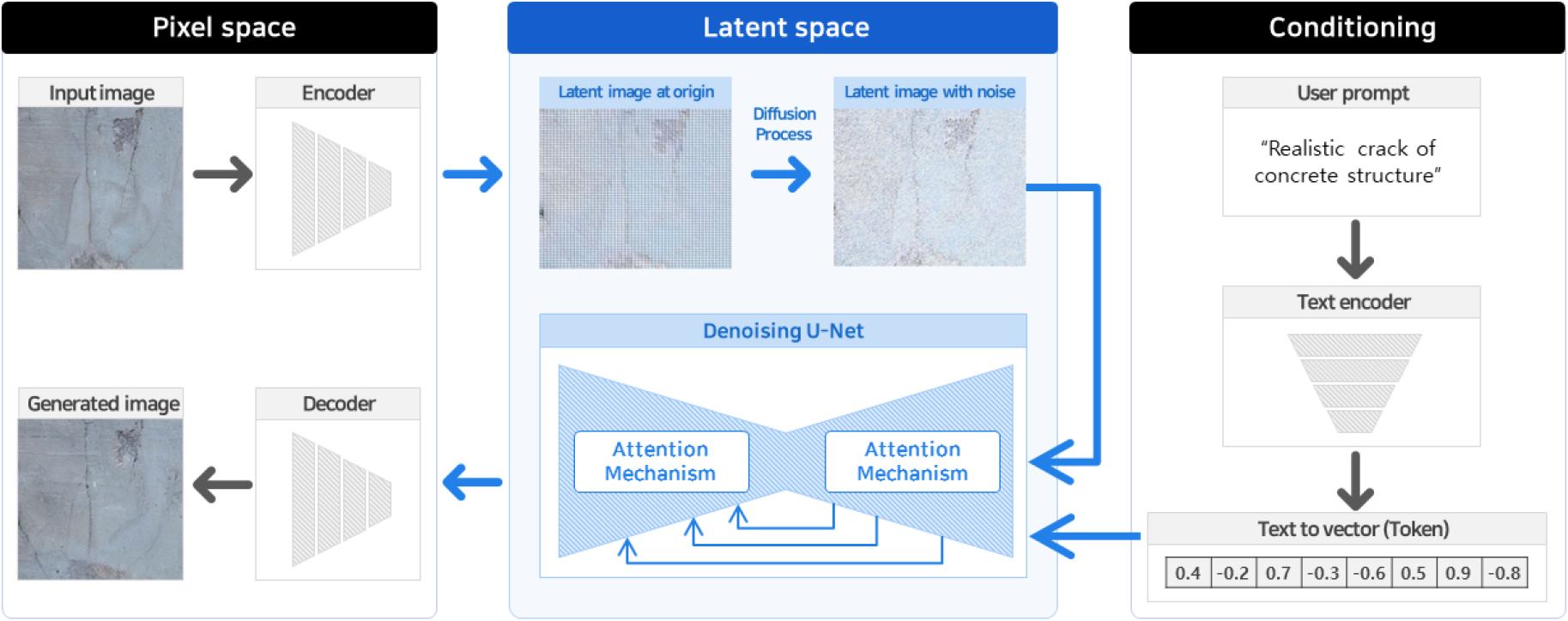
2.3 학습 환경 구성
콘크리트 균열 영상과 도로 균열 영상을 변환하여 새로운 균열 영상을 생성하는 실험을 수행하기 위해 사용한 하드웨어의 사양은 Intel Xeon 6226R 2.9 GHz, 320 GB의 메모리 그리고 NVIDIA Quadro 8000이다. 소프트웨어는 Ubuntu 22.04를 운영체제로 사용하였고 Pytorch를 딥러닝 라이브러리로 사용하였다. 본 논문에서 사용한 최적화 함수는 모두 Adam을 사용하였다. Adam을 사용할 때 필요한 파라미터는 learning rate, beta-1, 그리고 beta-2로 각각 0.0002, 0.5, 그리고 0.999로 설정하였다.
3. 결과 분석 및 논의
3.1 증강 영상의 결과 분석
본 연구의 목표는 생성된 균열 영상을 이용하여 학습 데이터 세트의 다양성을 높이는 것이다. 이를 위해 stable diffusion 방법에서 사용되는 여러 모델을 적용하였으며, 생성 과정에서 사용되는 파라미터도 조정하였다. 본 논문에서 제안하는 모델이 생성하는 영상의 품질을 평가하기 위해 두 가지 기 학습된 모델을 사용하였다. 첫 번째는 stable diffusion에서 공개한 version 1.4 모델이고, 다른 하나는 version 2.1 모델이다. 이 모델들은 각각 SD-1.4와 SD-2.1로 표기하였다. 아울러 두 모델을 합친 모델을 Merged SD라 하였다. 본 논문에서 이 모델들을 이용해 균열 영상을 생성하도록 하였다. Stable diffusion은 문자열-영상 생성 알고리즘이지만, 본 논문에서는 영상과 문자열을 입력으로 하여 새로운 영상을 생성하도록 하였다. 장의 훈련용 균열 영상에서 4개의 균열 영상을 생성하였다. 생성되는 영상의 다양성을 제어하기 위해 본 논문에서는 잡음 제어 강도를 조정하였다. 그 외의 파라미터인 cfg_scale, sampling_steps, sampling_method는 각각 11, 100, DPM++SDE Karras로 설정하였다. 생성되는 영상의 크기는 입력 영상과 동일하게 448 × 448로 하였다.
Stable diffusion 모델에 의해 생성된 균열 영상의 품질을 평가하기 위해서 Fréchet Inception Distance (FID)를 사용하였다(Heusel et al., 2017). 이는 식 (1)과 같이 정의된다. μo와 σo는 훈련용 균열 영상으로부터 계산된 평균과 분산이고 μ와 σ는 생성된 균열 영상으로부터 얻어진 평균과 분산이다. 이 두 값이 차이가 적을수록 두 영상의 세트는 유사성이 높다는 것을 뜻한다.
생성 영상의 유사성을 나타내는 FID에 영향을 미치는 요소는 모델 종류와 잡음 제어 강도다. 모델 종류와 잡음 제어 강도에 따른 FID는 Table 1에 나타나 있다. 본 논문에서 수행한 실험 결과 중 가장 낮은 FID는 Merged SD 모델에서 잡음 제어 강도 0.35를 사용했을 때 기록되었다. 우선, 잡음 제어 강도를 고려해보면 각각의 모델에서 0.38과 0.35를 사용하였다. SD-2.1 모델에 동일한 잡음 제어 강도를 적용했을 때, FID는 각각 71.68과 59.65로 나타났다. 또한, SD-1.4 모델에 잡음 제어 강도를 0.38과 0.35로 적용했을 때, FID는 각각 50.65와 40.64를 기록하였다. 이를 통해 알 수 있는 공통점은 잡음 제어 강도가 작아질수록 FID가 줄어든다는 점이다. 이는 잡음 제어 강도가 기존 영상과의 차별화 정도를 결정하는 주요 요소이기 때문이다. 이러한 경향은 Merged SD에서도 나타난다. 동일한 잡음 제어 강도를 적용했을 때, FID는 54.18에서 31.73으로 감소하였다. 결과적으로, 잡음 제어 강도를 0.03만큼 줄였을 때 FID는 약 10 정도 감소하는 것으로 나타났다. 모델 간의 비교를 해보면, 잡음 제어 강도가 0.35일 때 SD-2.1의 FID와 SD-1.4의 FID는 19.01 차이가 났다. 잡음 제어 강도가 0.38일 때도 유사하게 FID는 21.03 차이가 났다. 또한, 잡음 제어 강도가 0.35일 때 Merged SD의 FID는 SD-1.4보다 8.91 감소하였으나, 잡음 제어 강도가 0.38일 때는 오히려 FID가 3.53 증가하였다. 이를 통해 모델 종류가 FID 감소에 주요한 영향을 미친다는 것을 알 수 있다.
Table 1.
FID results of generated images
| Model | Denoising_strength | FID |
| SD-2.1 | 0.38 | 71.68 |
| 0.35 | 59.65 | |
| SD-1.4 | 0.38 | 50.65 |
| 0.35 | 40.64 | |
| Merged SD | 0.38 | 54.18 |
| 0.35 | 31.73 |
본 연구에서는 잡음 제어 강도의 범위를 0.35에서 0.38로 설정하였다. 그러나 잡음 제어 강도의 값이 이 범위를 벗어나게 되면 지금과는 다른 영상이 생성된다. 구체적으로, 잡음 제어 강도가 낮으면 생성된 영상에 거의 변화가 없게 된다. 반면, 잡음 제어 강도가 점차 커지면 전혀 다른 콘크리트 균열 영상이 합성될 수 있다. 때로는 비현실적인 형상의 콘크리트 구조물이 합성되기도 한다. 이러한 영상은 실제 균열 탐지에 큰 도움이 되지 않기 때문에 피해야 한다. 따라서 데이터 세트에 적합한 적절한 잡음 제어 강도를 선정하는 것이 중요하다.
3.2 증강된 영상 결과 비교 및 논의
생성된 균열 영상의 품질은 모델의 종류와 파라미터에 따라 편차가 존재한다. 이를 비교하기 위해 모델별로 생성된 영상의 상태를 확인한 결과는 Fig. 3과 같다. 이 균열 영상들은 모두 잡음 제어 강도를 0.35로 설정했을 때 원본 영상으로부터 새롭게 생성된 것이다. 생성된 균열 영상에서 가장 주목해야 할 부분은 콘크리트의 재질이다. 균열 형상은 실제 구조물에서도 임의의 방향으로 나타나므로 이를 기반으로 영상의 품질을 논하기 어렵다. 반면, 콘크리트는 재료를 활용한 작업 공정을 고려한다면 표면의 균질성을 유지해야 한다. 이러한 점을 고려했을 때, SD-2.1과 SD-1.4로 생성된 균열 영상에서는 콘크리트 표면에서 노란색으로 타원으로 표시된 것과 같이 인공물(artifact)이 관찰된다. 먼저, Fig. 3(a) 열의 영상을 보면, SD-2.1과 SD-1.4로 생성된 영상에서 크리스탈 무늬가 나타나는 것을 확인할 수 있다. 특히 SD-2.1로 생성된 영상의 상부에서는 비현실적인 형상이 관찰된다. Fig. 3(b) 열의 영상에서는 콘크리트 재질에서 부자연스러운 무늬가 발견되었다. SD-2.1의 균열 영상에서는 해링본 무늬가 나타났고, SD-1.4의 균열 영상에서는 크리스탈 무늬가 발견되었다. Fig. 3(c) 열의 영상에서는 인위적으로 만들어진 무늬가 나타났다. 특히, SD-2.1로 생성된 균열 영상에서는 시점의 변화가 발생했으며, 균열에 단차도 생긴 것으로 관찰되었다. Fig. 3(d)에서는 콘크리트 표면에 빗살무늬와 실지렁이 무늬가 과도하게 나타났다. 콘크리트 재질은 마감 시 이러한 무늬가 발생하지 않도록 처리되기 때문에, 이러한 무늬가 있는 영상은 현실성이 떨어진다고 볼 수 있다. 결과적으로 Merged SD로 생성된 균열 영상이 현실성이 가장 높은 것으로 나타났다.

실제와 유사한 균열 영상을 생성하는 모델을 활용해 다수의 균열 영상을 합성한 결과는 Fig. 4와 같다. 하나의 균열 영상으로부터 4장의 균열 영상을 생성하였다. 전반적으로 콘크리트 재질에 나타난 무늬뿐만 아니라 균열 형상에도 변화가 발생하였다. 이러한 결과 영상들은 원래의 균열 형상을 다양하게 제공하며, 콘크리트 재질에 대한 다양성을 높여 다양한 경우의 수를 포함한 영상 데이터가 되도록 한다. 구체적으로 설명하자면, 콘크리트 표면은 얼룩, 변색된 부분, 상이한 재질을 가진 부분 등 다양한 영역으로 구성되어 있다. 본 연구에서는 이러한 영역들의 다양한 조합을 통해 새로운 콘크리트 재질을 생성하는 데 중점을 두고 있다. 이로 인해 생성된 영상은 유사한 영역들이 반복되어 서로 유사성을 가지지만, 그 위치와 조합이 다르기 때문에 다양성도 함께 나타난다. 이러한 기술을 활용함으로써 실제 현장에서 균열 장면을 다양하게 촬영하는 데 소요되는 시간을 줄일 수 있다. 또한, 훈련 데이터의 다양성을 근본적으로 높임으로써 신경망을 더 많이 훈련할수록 모델의 성능이 향상된다. 이러한 맥락에서 본 연구의 결과는 강인한 균열 탐지 모델을 개발하는 데 기여할 것으로 예상된다.

영상을 자동으로 생성하려는 시도는 오래전부터 꾸준히 이어져 왔으며, GAN 모델의 등장과 함께 의미 있는 영상 생성 성능을 보이기 시작했다. 최근에는 확산 모델 기반의 생성 모델이 우수한 결과를 내기 시작했으며, 특히 stable diffusion의 등장은 영상 생성 모델 연구 분야의 폭발적인 성장을 이끌었다. 본 연구는 이러한 영상 생성 모델을 학습에 필요한 데이터 세트 증강에 활용하는 방향으로 접근하였다. 흥미로운 점은, 일반적인 실사 영상 생성에서 높은 성능을 보이는 모델이 반드시 균열 영상 증강에서도 좋은 성능을 보이지는 않는다는 것이다. 첫 stable diffusion 모델이 등장한 이후 다양한 개선 알고리즘이 나타났고, 양질의 영상을 생성하는 후속 모델들이 공개되었다. 하지만 본 연구를 통해 균열 영상 데이터에 적합한 모델과 파라미터를 찾는 것이 중요하다는 결론에 도달했다. 따라서 토목 분야에 적합한 활용을 위해서는 이러한 생성 모델에 대한 심층 연구와 다양한 실험이 지속적으로 필요할 것으로 기대된다.
3.3 균열 탐지 정확도 분석
생성된 영상의 목적은 균열 탐지의 정확도를 향상시키는 것이다. 이를 위해 증강된 영상이 균열 탐지에 미치는 영향을 정량적으로 평가할 필요가 있다. 평가를 위해 증강된 영상 없이 훈련한 모델과 증강된 영상을 활용해 훈련한 모델을 비교하였다. 훈련에 사용한 데이터의 수는 생성에 활용한 영상과 동일하게 3,421장이며, 평가에 사용한 균열 영상의 수는 717장이다. 균열 탐지에 사용한 신경망 모델은 분할 알고리즘 중 하나인 FDDWNet을 사용하였다(Liu et al., 2020). 생성된 균열 영상을 훈련에 활용하기 위해서는 새로운 방법이 필요하다. 생성된 균열 영상은 콘크리트 재질뿐만 아니라 균열 형상도 달라지기 때문에 라벨 영상을 가질 수 없기 때문이다. 따라서 일반적인 지도 학습으로는 신경망 모델을 훈련할 수 없으며, 준지도 학습을 적용해야 한다. 본 연구에서는 이를 위해 교차 의사 지도(cross pseudo supervision) 방법을 사용하였다(Chen et al., 2021). 이 방법은 동일한 신경망을 두 번 사용하여 서로의 예측 결과를 의사 라벨로 삼아 훈련을 진행하는 방식이다. 이를 통해 라벨이 없는 데이터도 훈련에 참여할 수 있게 된다. 훈련된 모델의 정확도를 비교하기 위해 평균 중첩도(mean intersection over union, m-IoU)와 F1 점수(F1)라는 두 가지 평가 지표를 사용하였다(Shim, 2024). 이를 통해 증강 데이터가 훈련에 참여했을 때 균열 탐지 정확도에 미치는 영향을 관찰하였다. 그 결과는 Table 2와 같다. 증강된 영상 없이 신경망 모델을 훈련한 경우, 정확도는 83.37%의 m-IoU와 80.47%의 F1을 기록하였다. 반면, 증강된 영상을 활용한 준지도 학습을 적용했을 때, 정확도는 85.65%의 m-IoU와 83.58%의 F1을 나타냈다. 두 실험을 비교한 결과, m-IoU와 F1은 각각 2.28%와 3.11%만큼 향상되었다. 결론적으로 생성된 영상이 균열 탐지 정확도 향상에 기여하는 것으로 나타났다.
4. 결 론
본 연구는 터널 내부 콘크리트 구조물에서 발생할 수 있는 균열 영상 데이터를 증강하는 방법을 제안하였다. 이를 위해 문자열 기반의 영상 생성 모델을 사용하여, 기존의 균열 영상에서 다른 콘크리트 재질과 다양한 균열 형상을 갖는 영상을 합성하였다. 또한, 보다 실제와 유사한 균열 영상을 합성하기 위해 생성형 AI의 기저모델과 잡음 제어 파라미터를 분석한 결과, 가장 현실성 높은 균열 영상을 합성하는 방법을 도출하였다. 본 연구의 결론은 다음과 같다.
1. 영상 생성에 활용되는 생성 모델 중 하나인 stable diffusion은 문자열을 기반으로 영상을 생성하며, 같은 문자열에서도 서로 다른 영상을 합성한다. 이는 모델에 활용되는 잡음이 최종 생성되는 영상을 결정하기 때문이다. 본 연구에서는 이러한 잡음의 임의성을 활용하여 데이터의 다양성을 높이는 방법을 제안하였다.
2. 생성된 균열 영상의 품질은 모델의 종류와 파라미터에 따라 달라진다. 생성 모델은 초거대 모델로서 영상 품질에 미치는 영향이 크다. 이를 고려하여, 본 연구에서는 두 모델을 융합해 균열 영상을 생성하였다. 또한, 잡음 제어 강도를 조정하여 31.73의 FID 값을 갖도록 하였다. 아울러 균열 탐지 정확도 또한 2.28% m-IoU와 3.11% F1만큼 향상되었다. 결과적으로 현실적인 균열 영상을 생성하기 위한 모델과 파라미터를 발견하는 절차를 정의하였다.
3. 최종적으로 선정된 모델과 파라미터를 통해 하나의 균열 영상으로부터 다수의 서로 다른 균열 영상을 합성하였다. 이러한 방법은 현장에서 균열 데이터를 수집하는 시간을 줄이고, 더 다양한 영상을 훈련 데이터로 활용할 수 있는 새로운 접근법을 제시하였다. 이러한 접근법은 균열 영상뿐만 아니라 박락, 백태, 철근 노출과 같은 다양한 손상을 포함한 영상으로도 확대 적용이 가능할 것으로 보인다. 생성 모델을 통한 손상 영상 합성은 균열 영상 합성과 마찬가지로 잡음 강도와 모델의 영향을 받는다. 따라서 적절한 모델 파라미터 조정 과정을 거친다면, 훈련 데이터의 다양성을 높이는 효과적인 방법으로 활용될 것으로 기대된다.
