

1. 서 론
2. 균열 탐지 성능 향상을 위한 초해상화 기법
3. 실험 설계
3.1 데이터셋 구성 및 실험환경
3.2 평가지표
4. 결과 및 분석
4.1 초해상화 알고리즘의 성능
4.2 균열 검출 결과 및 분석
5. 결 론
1. 서 론
기술의 발전과 더불어 콘크리트 터널을 비롯한 다양한 지하공간 및 구조물의 건설이 꾸준히 이루어지고 있다. 특히, 지상 도심지 포화 및 도시공간의 효율성에 대한 의견들이 제시됨에 따라 앞으로 지하공간의 활용도가 더욱 증가할 것으로 예상되며, 이러한 구조물의 안전성과 내구성을 유지하기 위한 관리의 중요성이 더욱 부각되고 있다. 그러나 터널과 같은 콘크리트 구조물은 시간이 지남에 따라 성능 저하되는 재료적 특징과 충격, 진동 등과 같은 외부 요인으로 인해 균열, 누수, 손상 등의 열화 현상이 발생할 수 있으며, 이는 구조물의 전체적인 안정성을 크게 저하시킬 수 있다(Kim et al., 2021). 현재 많은 터널 구조물들이 건설된 지 30년 이상이 경과하여 노후화가 진행된 상태로, 이러한 구조물들의 안전 관리가 시급한 과제로 부상되고 있다. 특히, 균열은 터널 내구성 저하의 초기 징후로 나타나는 중요한 열화 지표 중 하나로, 구조물 관리에 있어 체계적이고 지속적인 모니터링이 요구되는 핵심 요소이다.
최근 인프라 구조물의 유지관리 분야에서 균열 탐지 기술은 매우 중요한 역할을 담당하고 있다(Yamaguchi and Hashimoto, 2010). 균열은 구조물의 안정성에 직접적인 영향을 미치며, 이를 조기에 발견하고 적절히 보수하는 것은 구조물의 수명을 연장하고 안전성을 확보하는 데 필수적이다. 기존 균열 관리는 균열자, 균열 게이지 등을 활용하여 작업자가 직접 측정하고 평가하는 방식을 따르며, 이는 터널의 길고 넓은 특성상 많은 시간과 비용이 소모되며, 측정 및 평가 결과는 작업자의 주관에 의존적인 특징을 나타낸다. 이에 해당 한계점을 극복하고자 컴퓨터비전(computer vision, CV)을 활용한 연구들이 수행되었다(Ren et al., 2020). 콘크리트 구조물의 장기적인 안정성을 유지하기 위해 균열 탐지가 필수적이며, 이를 자동화하기 위한 연구들이 활발히 진행되고 있다. 균열 이미지 혹은 영상을 대상으로 탐지하는 작업에서는 특히 합성곱 신경망(convolutional neural network, CNN)이 많이 활용되었으며(Cha et al., 2017), 이를 기반으로 하는 다양한 알고리즘들이 제안되었다. Pan et al. (2020)은 콘크리트 균열의 탐지 성능을 높이기 위해 새로운 신경망 구조를 제시하였다. 제시된 SCHNet은 VGG19를 기반으로 하며, 공간 및 채널 차원의 정보를 통합하여 균열 탐지 성능의 향상을 가능하게 하였다. 또한, 계층적 특징을 학습에 활용하는 신경망 구조로 DeepCrack이 제시되었으며(Liu et al., 2019), 더욱 복합적인 상황에 대한 균열탐지 성능의 향상을 위해 Cracklab가 제안되었다(Yu et al., 2022). 이처럼 다양한 형태로 영상센서를 활용하여 균열 탐지 및 평가를 보다 객관적으로 수행할 수 있는 연구들이 수행되어왔다. 그러나, 현장에서 수집된 균열 영상은 촬영 방식이나 환경 조건으로 인해 종종 저해상도이거나 흔들림이 발생할 수 있으며, 이는 균열 탐지의 정확도를 저하시키는 요인이 된다. 또한, 유지관리 측면에서 넓은 화각에서 대상을 명확하게 확보하는 것이 시간적 ‧ 비용적 이점을 제공하지만, 넓은 시야에서 촬영된 영상에서는 미세 균열이 잘 드러나지 않는 한계가 있다. 시설물의 안전 및 유지관리 실시 세부지침(MOLIT and KALIS, 2023)에 따르면, 터널과 공동구의 경우 균열 폭을 기준으로 평가하며, 그 수치는 구조물의 크기에 비해 매우 미세하다. 따라서, 미세 균열을 정확히 감지하기 위해서는 고품질의 영상 확보뿐만 아니라 근거리 촬영이나 고해상도 영상센서의 사용이 필수적일 수 있다.
따라서, 본 연구에서는 저해상도 영상에서도 높은 탐지 정확도를 유지할 수 있도록 균열 탐지 구조에 초해상화 알고리즘을 적용하고자 하였다. 초해상화 알고리즘의 성능을 평가하고, 이를 활용하여 다양한 비율의 저품질 영상에서 균열 탐지 성능을 향상시키고자 하였다. 또한, 여러 초해상화 알고리즘을 제시하고, 이를 적용하여 균열탐지 알고리즘의 성능 향상을 실험을 통해 검토함으로써, 초해상화 알고리즘의 효용성 및 최종적인 균열탐지의 성능향상을 확인하였다.
2. 균열 탐지 성능 향상을 위한 초해상화 기법
딥러닝 기술의 발전은 이미지 처리 분야에서 눈에 띄는 성과를 거두었으며, 다양한 기술을 활용한 초해상화 기법들이 제시되었다(Wang et al., 2021). 구체적으로 보간법, CNN 기반 기법, 변환기(transformer) 기반 기법, 그리고 최근 각광받고 있는 확산 모델(diffusion model) 기반 기법 등이 각각의 방식으로 저해상도 영상의 세부 정보를 복원하고 고해상도 영상을 생성하는 데 사용될 수 있다. 첫 번째로, 보간법은 저해상도 영상에서 고해상도 영상을 예측하는 가장 기본적이고 널리 사용되는 기법으로, 선형 보간법(linear interpolation), 양입방 보간법(bicubic interpolation) 등의 여러 방법들이 제시되었다. 일반적으로 보간법을 이용한 초해상화 기법의 주요 원리는 저해상도 이미지의 픽셀 사이에 새로운 픽셀 값을 추정하여 이미지의 해상도를 높이는 것이다(Gilman et al., 2008). 기존 인접한 픽셀의 값을 활용하여 새로운 픽셀의 값을 추정하는 방식으로, 높은 계산의 효율성 및 구현의 용이함을 장점으로 제시될 수 있다. 그러나 기존의 정보만을 기반으로 추정하기 때문에 그 성능은 제한적이며, 특히 균열 이미지에서는 균열과 배경사이의 세밀한 경계 복원이 필수적이기 때문에, 보간법 기반의 방법은 한계가 있다.
이러한 한계점을 극복하기 위해 학습 기반의 기법들이 제안되었다. 학습을 통해 저해상도 영상과 고해상도 영상 사이의 관계를 분석함으로써 보다 정교한 복원이 가능해졌다. Dong et al. (2016)은 연속적으로 CNN 레이어를 쌓아서 만든 구조의 Super-Resolution Convolutional Neural Network (SRCNN)을 제시하였다. 이 구조는 입력된 저해상도 영상을 기반으로 더 높은 차원으로 업스케일링하고, 특징을 추출하여 고해상도 이미지로 복원하는 단계로 구성되어 있다. 이는 단순한 구조임에도 불구하고, 기존의 보간법에 비해 더 풍부한 정보를 학습할 수 있어 성능이 뛰어나다는 장점을 가지고 있다. 하지만 상대적으로 단순한 구조로 인해 복잡한 정보를 복원하는데 한계가 있을 수 있으며, 특히 균열과 같이 미세한 경계의 복원이 필요한 경우 성능이 저하될 수 있다. 이러한 성능의 한계를 극복하기 위해 생성적 적대 신경망(generative adversarial network, GAN)을 활용한 구조가 제안되었다. Super-resolution GAN (SRGAN)은 생성자(generator network)와 판별자(discriminator network) 간의 경쟁적인 학습과정을 통해 더욱 사실적인 고해상도 영상으로의 복원이 가능하였다(Ledig et al., 2017). 생성자는 저해상도 영상을 고해상도로 복원하는 역할을 수행하며, 판별자는 생성된 고해상도 영상과 원본의 고화질의 영상을 구분하는 역할을 수행한다. 이처럼 서로 다른 역할을 수행하는 두 네트워크를 경쟁적으로 학습시킴에 따라 CNN 기반 방법에 비해 경계 복원과 복잡한 패턴 처리에서 큰 성능 향상을 나타냈다. 하지만 모드 붕괴(mode collapse)와 같은 학습의 불안정성은 여전히 해결해야 할 문제로 남아있다.
최근에는 CNN 기반의 구조 외에도 트랜스포머, 확산 모델 기반 방법이 초해상화 분야에서 각광받고 있다. 트랜스포머 구조는 자연어 처리 분야에서 먼저 활용되었으나, 영상 처리 분야에도 도입되어 뛰어난 성능을 발휘하고 있다. 트랜스포머 기반의 방법은 이미지를 패치 단위로 나누어 각 패치 간의 관계를 학습하여 전체 이미지를 복원하는 방식이다(Lu et al., 2022). 이러한 특성으로 인해 전통적인 CNN 구조와 달리, 전역적 이미지 특징을 더 효과적으로 학습할 수 있어, 이미지 전반에 걸친 복잡한 패턴과 경계 복원에 유리하다. 하지만 연산 자원의 소모가 크며, 대규모의 학습데이터가 요구된다는 한계점이 있다. Liang et al. (2021)은 Swin transformer을 기반으로 고안된 SwinIR 모델을 제안하였다. 이 모델은 어텐션 메커니즘을 활용하여 고해상도 영상으로의 복원 성능을 극대화하였으며, 특히 세밀한 특징의 복원에서 우수한 성능을 나타내었다. 한편, 확산 모델 기반 기법은 이미지 생성과 복원에서 매우 우수한 성능을 보여주고 있다. 확산 모델은 이미지의 노이즈를 점진적 첨가하고, 그 노이즈를 제거하는 방식으로 고해상도의 이미지를 생성하는 기법이다. 낮은 품질의 이미지나 노이즈가 포함된 이미지로부터 점진적으로 노이즈를 제거하여 원본 고해상도 이미지로 복원하는 것이 목표이며, 복잡한 이미지에서의 세부 정보 복원에 강력한 성능을 나타낸다(Croitoru et al., 2023). 이러한 확산 모델을 기반으로 초해상화를 목표로 한 Super-Resolution via Repeated Refinement (SR3) 모델이 제안되었다(Saharia et al., 2023). SR3는 저해상도 이미지에서 고해상도 이미지로 복원하는 과정에서 확산모델의 강점을 활용하여 세밀한 디테일의 복원이 가능하였지만, 이 과정에서 반복적인 노이즈 제거가 필요하여 계산의 복잡성 및 긴 추론시간이 요구된다. 이처럼 다양한 초해상화 기법들이 개발되어 왔으며, 각 기법들의 대표적인 특징은 Table 1에 요약되어 있다.
Table 1.
Characteristics of super-resolution method
3. 실험 설계
3.1 데이터셋 구성 및 실험환경
본 연구에서는 초해상화 알고리즘과 이를 활용한 균열 탐지 알고리즘의 성능을 평가하기 위해 동일한 데이터셋을 활용하였다. 초해상화 알고리즘을 통해 입력 영상의 품질을 개선하고, 균열 탐지의 성능을 향상시키는 것을 목표로 하였으며, 각 알고리즘의 학습과 성능 평가를 위해 데이터셋을 두 가지 목적으로 구성하였다(Fig. 1). 두 데이터셋 모두 기존 연구에서 제시된 콘크리트 균열 RGB 영상과 일부 레이블 영상을 기반으로 구성되었으며(Maguire et al., 2018; Ozgenel, 2018; Kulkarni et al., 2023), 동일한 크기의 영상으로 변환하여 학습에 활용되었다. 구체적으로, 앞서 제시된 데이터셋은 초해상화 알고리즘 학습을 위한 데이터셋과 균열 탐지 알고리즘 학습을 위한 데이터셋으로 구분된다. 각 데이터셋의 영상 크기가 상이하기 때문에, 모든 이미지는 256 × 256 pixels로 변환하여 학습에 사용되었으며, 총 5,356장의 콘크리트 표면 균열 이미지 중 70%인 3,750장이 학습 데이터로, 나머지 1,606장이 성능 평가에 활용되었다. 이 중 일부 데이터셋은 RGB 영상만 제공하기 때문에, ImageAnnotation 소프트웨어를 사용하여 균열의 라벨 영상을 제작하였으며(Kim et al., 2021), 그 외 데이터는 학습 네트워크 구조에 맞춰 일부 수정하여 사용하였다.
초해상화 알고리즘의 학습 목적은 입력영상의 품질의 의존도를 낮춤과 동시에 해상도를 높여 균열탐지 성능의 안정성 및 정확도 향상을 목표하였다. 이를 위해 저품질 및 저해상도 영상을 고품질 및 고해상도 영상으로 복원이 가능하도록 학습데이터셋의 구성이 필요하다. 이를 위해서 구성된 데이터셋의 형태는 Fig. 1(a)에 나타낸 것과 같다. 초해상화 알고리즘의 학습데이터는 데이터셋의 50%에 가우시안 블러 필터의 강도를 달리 적용하여 품질의 저하를 구현하여 활용하였다. 이때, 블러 필터의 적용 강도를 조절하는 커널 크기(kernel size)를 5에서 23 사이의 값으로 랜덤하게 설정하여 이미지를 저품질화 처리하였다. 커널 크기는 블러 효과의 강도와 연관된 지표이며, 커널 크기가 커질수록 이미지가 더 흐려지는 경향이 나타난다. 본 연구에서 적용한 가장 약한 블러 효과와 강한 효과를 적용한 이미지의 예시를 Fig. 1(c)에 제시하였다.
구체적으로 고품질 및 고해상화를 위한 초해상화 알고리즘 학습을 위해 기 확보된 RGB 이미지를 저품질 및 저해상화 시켜 입력 이미지로 설정하였으며, 기 확보된 영상을 초해상화 알고리즘을 통해 복원시킨 이미지로 설정하였다. 즉, 확보한 데이터셋()의 크기를 1/2배 줄이고, 가우시안 블러 필터를 적용하여 저해상도 및 저품질의 영상()을 제작하였다. 이처럼 초해상화 알고리즘의 학습과정에서는 와 영상이 동시에 활용되었다. 균열 탐지 알고리즘의 학습 및 성능 평가를 위한 데이터셋은 균열이 표시된 RGB 영상()과 해당 균열 위치를 나타내는 정답영상인 라벨 영상()으로 구성되었으며, Fig. 1(b)에 나타낸 바와 같이 구성되었다. 이 데이터셋은 초해상화 알고리즘이 복원한 고해상도 영상을 균열 탐지에 적용하여, 실제로 균열 탐지 성능이 향상되는지 평가하기 위해 사용되었다.
초해상화 알고리즘과 균열 탐지 알고리즘의 학습 과정에서는 다양한 하이퍼파라미터가 활용되었으며, 모든 실험은 i9-10980XE CPU, 108 GB RAM, NVIDIA-RTX 3090으로 구성된 PC에서 Linux 기반 PyTorch를 활용하여 수행되었으며, 성능 평가는 학습된 모델을 검증 데이터셋에 적용하여 이뤄졌다.

3.2 평가지표
성능 평가는 두 가지 측면에서 수행되었다. 첫 번째로, 초해상화 알고리즘의 성능은 고화질의 영상과 인위적으로 저품질 및 저해상도로 변환된 이미지를 복원한 이미지 간의 품질을 비교하여 평가하였다. 이를 위해 다양한 품질평가 지표가 활용되었으며(Wang et al., 2004; Sheikh and Bovik, 2006; Zhang et al., 2018; Ding et al., 2022), 총 6가지 지표가 사용되었다: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), Multi-Scale Structural Similarity Index Measure (MS-SSIM), Visual Information Fidelity (VIF), Learned Perceptual Image Patch Similarity (LPIPS), Deep Image Structure and Texture Similarity (DISTS). 먼저 PSNR은 복원된 이미지와 원본 이미지 간의 픽셀 차이를 기반으로 화질 손실 정보를 평가하는 지표이다. 주로 영상 복원 성능을 수치적으로 평가할 때 사용되며, 식 (1)과 같이 계산된다. 여기서 R은 각 픽셀의 최대값을 의미한다. SSIM은 두 이미지 간의 밝기, 대비, 구조 정보를 고려하여 유사성을 평가하는 지표로, 사람의 지각 특성을 반영한다는 점에서 중요하다. 식 (2)에서 와 는 밝기, 와 는 대비, 는 구조적 요소를 평가하는데 활용되는 요소이다. MS-SSIM은 SSIM의 확장 버전으로, 다양한 해상도에서 이미지의 유사성을 평가하는 지표로서, 다중 해상도에서 SSIM을 반복 계산함으로써 복원 품질을 측정하는 방식이다. VIF는 원본 영상의 시각적 정보가 복원된 이미지에서 얼마나 손실 없이 재현되었는지를 평가한다. PSNR의 한계였던 인간 지각 관점에서의 평가를 포함한다는 특징이 있다. LPIPS는 딥러닝 기반의 지표로, VGG, AlexNet과 같은 딥러닝 모델의 중간 레이어에서 추출한 특징맵을 사용하여 두 이미지 간의 시각적 품질과 구조적 유사성을 평가하는 지표이다. 마지막으로 DISTIS는 영상의 구조적 정보와 질감적 정보를 동시에 고려하여 평가하는 지표이다. 기존의 많은 지표들이 주로 구조적 유사성에 초점을 맞추는 반면, 질감적 정보를 추가적으로 중요한 요소로 평가하는 특징을 가지고 있다. 총 여섯 가지 지표 중 SSIM, MS-SSIM, VIF는 값이 클수록 복원된 이미지가 원본에 가까움을 의미한다. 반면, LPIPS와 DISTS는 값이 작을수록 복원 성능이 우수함을 나타낸다. 이처럼 이미지의 복원 성능을 평가할 수 있는 다양하게 제시되었으며, 각 지표별 특징과 평가 방식에 대해서 Table 2에 요약하였다.
Table 2.
Evaluation criteria of image reconstruction
두 번째로, 균열 탐지 알고리즘의 정확도를 측정하는 지표는 다양하게 제안되었다(Long et al., 2015). 그 중에서도 균열 탐지 성능을 파악하기 위해 두 가지 지표를 사용하였다: Crack intersection over union (Crack IoU)와 F1-score. 먼저, Crack IoU는 탐지된 균열 영역과 실제 균열 영역 간의 겹치는 부분을 평가하는 지표로, 식 (3)으로 표현할 수 있다. 여기서 는 클래스 에 속하는 전체 픽셀의 개수를 의미하며, 는 클래스 로 추정한 클래스 의 픽셀 수를 나타낸다. 따라서 식 (3)에서 는 균열의 전체 픽셀 수를 표현하고, 는 실제 균열의 영역과 균열로 추정된 영역의 합집합에 해당하는 픽셀 수를 의미한다. Crack IoU 값이 클수록 정확도가 높음을 나타내며, 특히 영상 내에서 균열이 차지하는 비율이 상대적으로 작기 때문에, 이를 활용함으로써 균열이 얼마나 정확하게 탐지가 되었는지를 확인할 수 있다. 또한, F1-score는 탐지된 균열의 정밀도(Pr)와 재현율(Re)의 조화평균으로. 식 (4)로 표현될 수 있으며, 이 값이 1에 가까울수록 높은 탐지성능을 나타낸다. 정밀도와 재현율은 각각 식 (5)와 식 (6)으로 표현되며, 두 가지 지표는 오차행렬(confusion matrix)을 기반으로 한다. 분류는 다음과 같은 4가지의 시나리오가 발생할 수 있다. 구체적으로 실제 균열이 있는 영역을 균열로 정확히 예측한 경우(true positive, TP), 실제로 균열이 없는 영역을 균열로 잘못 예측한 경우(false positive, FP), 실제 균열이 없는 영역을 올바르게 균열이 없는 영역으로 예측한 경우(true negative, TN), 실제 균열이 있는 영역을 탐지하지 못한 경우(false negative, FN)가 있다. 따라서, Pr는 예측된 균열 영역 중에 실제 균열 영역의 비율을 의미하며, Re는 실제 균열 영역 중에 모델이 균열로 예측한 영역의 비율을 나타낸다. 이 두 가지 지표를 통해 균열 탐지의 전반적인 성능을 종합적으로 평가할 수 있다.
4. 결과 및 분석
본 장에서는 입력 이미지의 저품질 비율에 따른 초해상화 알고리즘의 성능의 변화에 대해 자세히 기술하였으며, 초해상화 알고리즘을 활용한 균열탐지 알고리즘의 적용 시 성능향상의 효과를 관찰 및 비교하였다.
4.1 초해상화 알고리즘의 성능
본 연구는 입력 영상의 품질에 상관없이 높은 균열탐지 성능 확보를 목표하였으며, 균열 탐지 성능은 입력 영상의 형태에 영향을 많이 받기 때문에, 초해상화 알고리즘의 학습에서는 저품질의 이미지와 고품질의 이미지를 모두 활용하였다. 초해상화 알고리즘의 저품질 데이터 비율에 따른 성능 변화를 관찰하기 위해서 동일한 데이터셋을 활용하여 각 알고리즘을 학습하였다. 초해상화 알고리즘은 각 기법별로 대표적인 알고리즘을 하나씩 활용하였으며, 학습이 완료된 초해상화 알고리즘의 성능 평가는 저품질 데이터의 비율을 0, 25, 50, 75 그리고 100% 5가지 경우로 나누어 수행하였다. 여기서 저품질의 데이터의 비율은 테스트 데이터셋에 포함된 저품질 데이터의 비율을 의미하며, 0%는 모든 데이터가 저화질임을 표현하며, 100%는 모든 데이터가 저화질 및 저품질 데이터임을 나타낸다. 이는 균열 탐지 알고리즘의 성능 변화를 다양한 조건에서 관찰하기 위한 설정으로, 실제 데이터 수집 과정에서 저품질 데이터가 랜덤하게 확보될 가능성을 반영하였다.
각 알고리즘별, 저품질 데이터 비율에 따른 성능 변화는 Fig. 2와 같다. 여섯 가지 성능지표 모두에서 알고리즘의 종류에 상관없이 저품질 데이터의 비율이 높아질수록 복원 성능이 전반적으로 하락하는 경향을 보였다. 더불어 복원 이미지의 품질 평가 지표를 활용한 성능평가 결과는 Table 3에 나타낸 것과 같다. Table 3에서는 저품질 데이터 비율에 따른 다섯 가지 경우별에 대해 초해상화 알고리즘의 성능을 평균과 분산을 통해 제시했다. 여기서 평균이 높은 것은 다양한 저품질 데이터의 확보 상황에서도 높은 성능을 유지함을 의미하며, 분산이 낮다는 것은 여러 조건하에서도 성능변화가 크게 나타나지 않음을 의미하여, 초해상화 알고리즘이 다양한 조건에서도 얼마나 안정적인지를 평가할 수 있게 한다. 각 성능 지표는 중점적으로 평가하는 내용이 다르기 때문에, 지표별 최고성능 모델은 상이하게 나타났다. 그럼에도 불구하고, 전반적으로 평가된 4가지의 초해상화 알고리즘 중 트랜스포머 기반의 모델인 SwinIR (light)와 확산모델 기반의 SR3 모델이 가장 우수한 성능을 보였다. 특히 SwinIR는 구조적인 정보를 주로 평가하는 SSIM과 MS-SSIM 지표에서 일관되게 높은 성능을 나타냈으며, 뿐만 아니라 해당 지표들에서 낮은 분산값을 나타냈다. 이러한 결과는 SwinIR이 균열과 배경의 경계 구분에 있어 안정적인 성능을 유지할 수 있음을 시사한다.
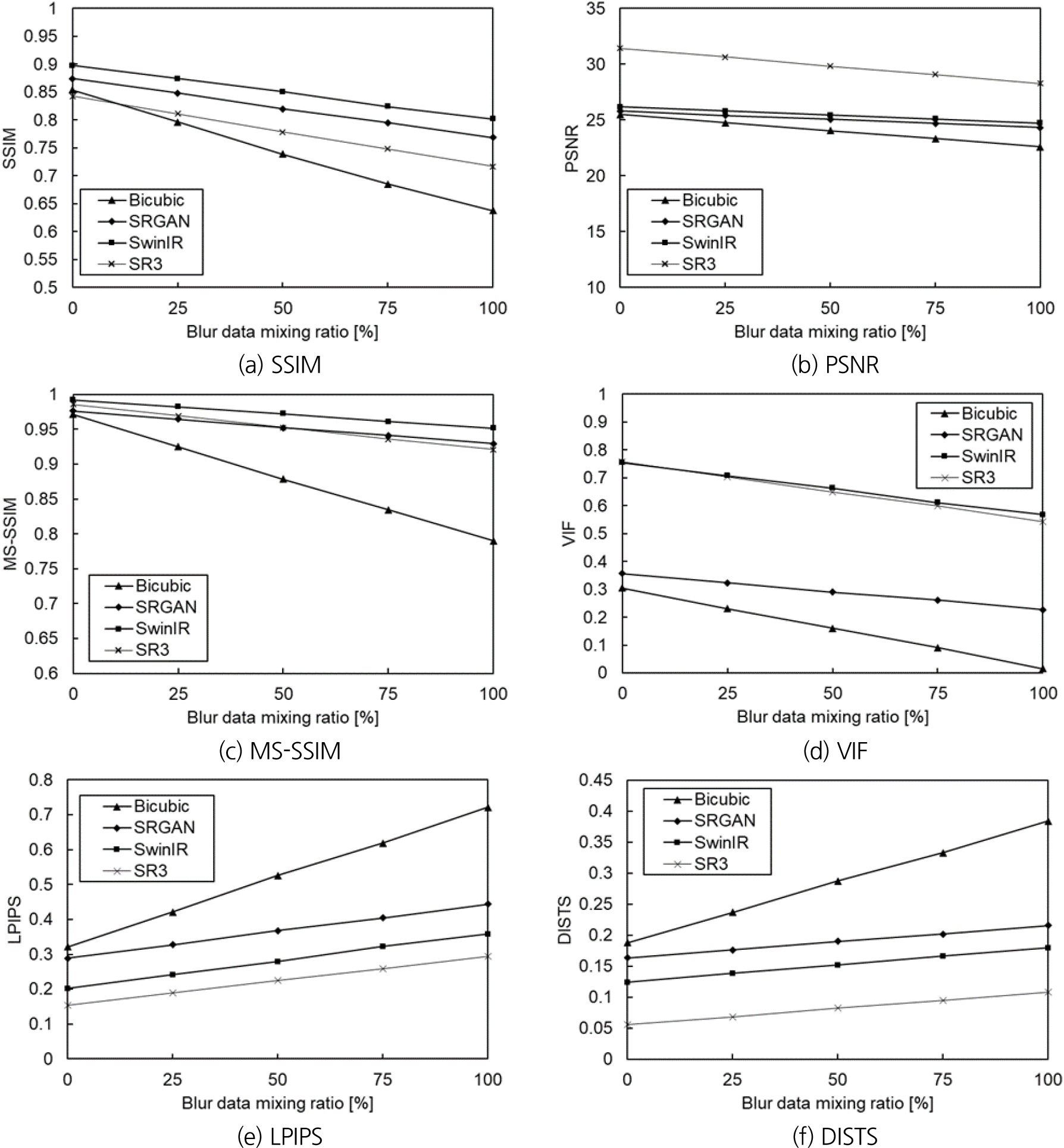
Table 3.
Performance evaluation of super-resolution algorithms
Fig. 3에 제시된 복원된 이미지는 각 초해상화 알고리즘이 저품질 및 저해상도 이미지를 고해상도로 복원한 결과를 시각적으로 보여준다. SwinIR과 SR3는 특히 고품질 및 고해상도 이미지와 유사하게 균열과 배경의 경계를 명확하게 복원했으며, 이는 높은 성능과 일치하는 결과이다. 두 알고리즘 모두 저해상도 이미지에서 발생할 수 있는 노이즈와 경계의 모호함을 효과적으로 제거하여 균열의 형태를 더욱 뚜렷하게 복원하였다. 하지만, 저품질 데이터의 비율이 증가함에 따라 경계 구분이 모호해지는 경향이 나타났으며, SR3 모델과 SwinIR 모델 모두 높은 복원 성능을 보였지만, 일부 경계 부분에서 다소 불명확한 결과를 나타내는 경우를 확인할 수 있다. 이러한 결과는, 균열 탐지에 있어서 초해상화 알고리즘의 선택이 매우 중요한 요소임을 확인시켜준다. 특히, 터널 내 균열과 같은 정밀한 구조 탐지가 요구되는 환경에서는 SwinIR과 같은 트랜스포머 기반의 알고리즘이 균열 탐지 성능을 극대화하는 데 유리할 수 있음을 시각적으로 확인할 수 있다.

4.2 균열 검출 결과 및 분석
초해상화 알고리즘을 활용한 균열탐지 알고리즘의 적용 시 성능향상의 효과를 관찰하기 위해, 3가지 세그멘테이션 알고리즘과 앞선 초해상화 알고리즘의 성능 비교에서 가장 높은 성능을 보였던 SwinIR (light)을 활용하여 실험을 수행하였다. 실험에 활용된 세그멘테이션 알고리즘은 경량모델로 알려진 LedNet (Wang et al., 2019), CGNet (Wu et al., 2021), 그리고 ERFNet (Romera et al., 2018)이다. 균열 탐지의 성능 분석은 초해상화 알고리즘의 성능 평가와 마찬가지로 저품질 데이터의 비율에 따른 성능 파악을 위해 0%, 25%, 50%, 75%, 그리고 100%의 다섯 가지 경우로 나누어 학습 구조별 탐지 성능을 측정하였다. 학습 구조는 초해상화 알고리즘을 사용하지 않은 일반적인 지도 학습 구조(baseline)와 SwinIR을 적용한 초해상화 기반의 학습 구조(SR-based structure) 두 가지로 나누어 성능을 비교하였다.
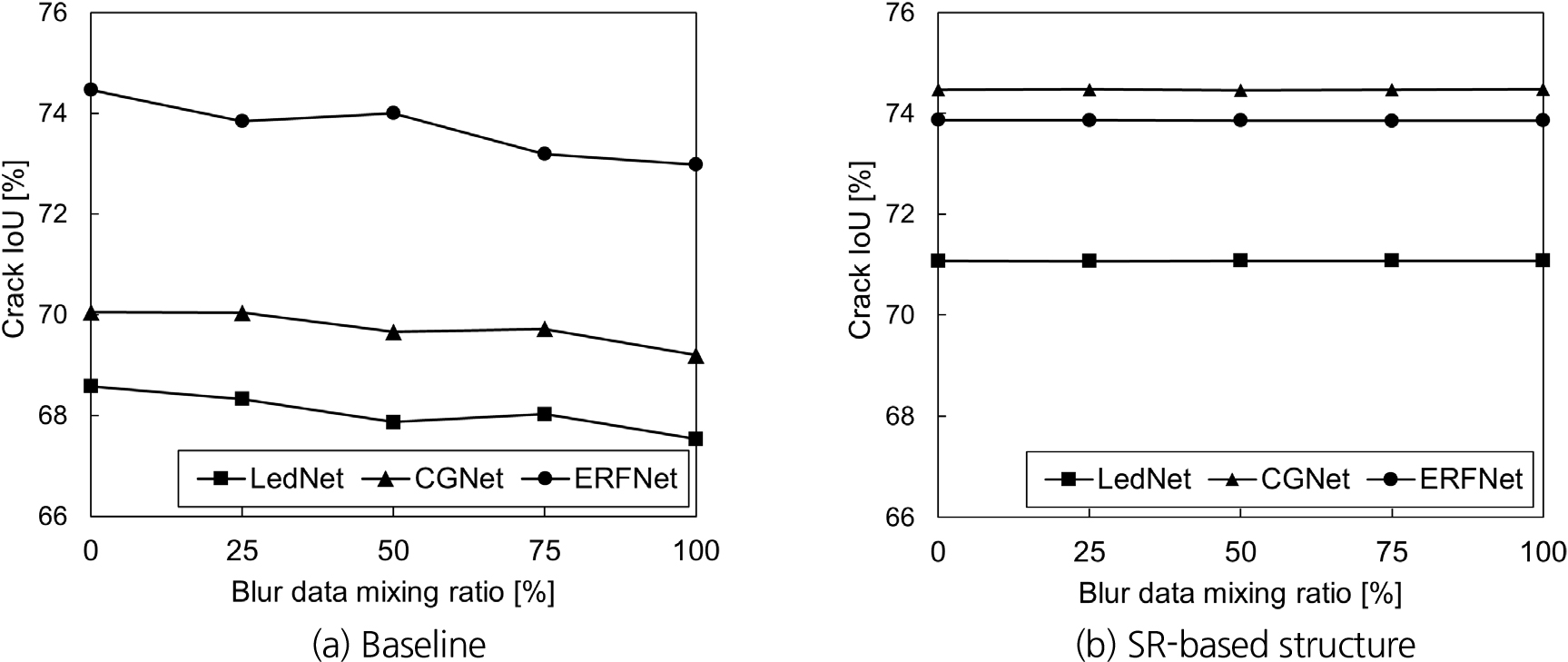
학습 구조에 따른 세그멘테이션 알고리즘의 성능 평가 결과는 Table 4와 Table 5에 요약되어 있으며, 저품질 데이터 비율에 따른 각 알고리즘의 성능은 Fig. 4에 제시하였다. 두 가지 탐지 성능 지표 모두에서 초해상화 알고리즘을 활용한 SR-based structure가 Baseline 대비 성능 향상을 보였다. 이러한 성능 향상이 나타난 주요 원인은 2가지가 있다. 첫 번째로, 입력 영상의 해상도를 높인 것이 탐지 성능 향상에 기여하였다. 이는 저품질 데이터가 포함되지 않은 0% 경우에서의 성능 향상을 통해 알 수 있다. 입력 데이터의 해상도를 향상시킴으로써 균열탐지를 보다 고해상도 이미지에서 수행할 수 있었으며, 이는 결과적으로 균열과 배경을 명확하게 구분해야 하는 균열 탐지에 긍정적인 효과로 나타났다. 두 번째로, 초해상화 알고리즘의 활용을 통해 입력영상을 고품질 및 고해상도 영상으로 복원이 가능하였으며, 이는 노이즈로 인해 불분명했던 균열과 배경사이의 경계를 명확하게 구분할 수 있게 하였다. 이로 인해, 최종적으로 높은 정확도로 균열탐지가 가능했음을 보여준다. SR-based structure에서 활용된 초해상화 알고리즘은 저품질 영상의 비율에 상관없이 균열 탐지 알고리즘 기준에서 유사한 형태의 영상이 입력영상으로 활용될 수 있도록 복원하였기 때문에, 입력 영상에 대한 강건성이 확보되어 품질 변화에 따른 성능 변화가 거의 관찰되지 않았다. 다양한 저품질 데이터 비율에서도 SR-based structure의 성능이 안정적으로 유지됨에 따라, SwinIR (light)와 같은 초해상화 알고리즘이 터널 균열 탐지와 같은 환경에서도 효과적으로 적용될 수 있음을 확인할 수 있다.
Table 4.
Crack detection performance by structure (Crack IoU)
| LedNet | CGNet | ERFNet | ||
| Baseline | Average | 68.07 | 69.73 | 73.70 |
| Variance | 0.1640 | 0.1225 | 0.3673 | |
| SR-based structure | Average | 71.08 | 74.47 | 73.86 |
| Variance | 0.0000 | 0.0001 | 0.0000 | |
5. 결 론
본 연구에서는 터널과 같은 콘크리트 구조물에서 발생하는 균열을 효과적으로 탐지하기 위해 초해상화 알고리즘을 활용하는 방안을 제안하였다. 저해상도 영상에서도 높은 정확도를 유지할 수 있는 방안을 제시하고, 다양한 초해상화 알고리즘의 실효성을 실험을 통해 검토하였다. 본 연구에 의한 주요 결론은 다음과 같다.
1. 노후된 콘크리트 구조물의 증가에 따라, 효율적이고 정확한 안전 관리 방법의 개발이 필수적이며, 이에 따라 컴퓨터 비전 기술이 활용되고 있으나, 현장에서 수집된 영상의 품질은 수집조건에 따라 크게 달라져 성능의 저하의 한계가 존재한다. 이에 초해상화 알고리즘을 활용하여 다양한 품질의 입력 영상에서도 안정적이고 향상된 균열 탐지 성능을 유지할 수 있는 방안을 제안했으며, 실험을 통해 여러 초해상화 알고리즘의 효용성을 검토하였다.
2. 트랜스포머 기반의 SwinIR과 확산모델 기반의 SR3이 우수한 성능을 나타냈다. 특히, 우수한 성능의 초해상화 알고리즘을 활용하여 균열탐지를 수행할 경우 안정적이고 향상된 균열 탐지 성능을 달성할 수 있음을 확인하였다.
3. 본 연구는 초해상화 알고리즘이 터널 유지 관리에서 균열 탐지의 정확성을 높이는 데 유용하다는 가능성을 제시하였으나, 실제 현장에서 활용하기 위해서는 수집된 다양한 형태의 데이터에 대한 추가적인 실험과 검증이 필요하다. 이를 통해 실제 환경에서의 활용 가능성을 더욱 강화할 수 있을 것이다.
